これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、機械学習の話題をお届けします。前回、機械学習を利用した画像認識システムによる、画像処理の例を紹介しました。こちらの画像にあるように、低解像度の画像が、鮮明な画像に自動変換されるというものです。
ところで、この変換後の画像を見ていると、何種類かの画像が合成されたように見えないでしょうか?
右下の画像の「300」の真ん中の0には、うっすらと「3」が混ざっているように見えます。左下の画像の「11-6■」の背後にも、他の数字がうっすらと見えます。これは、いったい何がおきているのでしょうか?
―― その答えは、本コラムの最後に明らかになります。
機械学習の理論の中には、複数の画像を合成する例として、「EMアルゴリズム」を用いた処理があります。さきほどの画像とEMアルゴリズムで生成した合成文字(図1)を比較すると、類似性が感じられて興味がわきます。
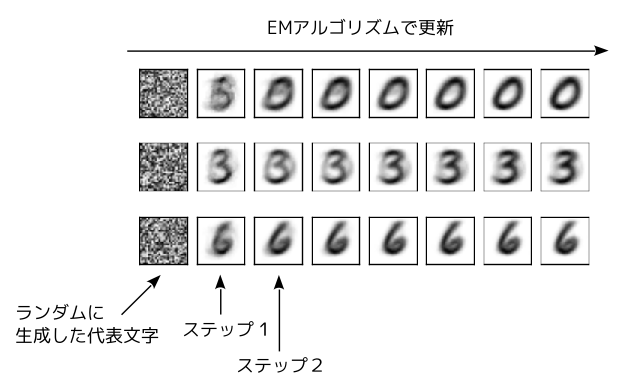
図1 合成文字を機械学習で更新していく様子
図1では、手描きの数字(この例では「0」「3」「6」の3種類)のサンプル画像を大量に収集して、EMアルゴリズムを用いた機械学習にかけることで、次の処理を行っています。
たくさんの顔写真を合成して、「代表的な顔」の画像を作るように、たくさんの手書きの数字から、代表的な形状の数字を作っていると考えてください。「代表文字」が用意できれば、新たな手書きの文字に対して、どの代表文字に似ているかによって、文字の種類が判別できるようになります。
ここで、「代表文字」と手書き文字の類似性を判断する方法を説明します。なかなかユニークな発想ですが、図2の左端にある「代表文字」を一種の「確率スタンプ」と考えます。代表文字の各点には、色の濃淡がありますが、この濃淡にしたがった確率で黒いインクを出力します。つまり、色が濃いところは、黒い点になりやすく、色が薄いところは、白い点になりやすいというわけです。
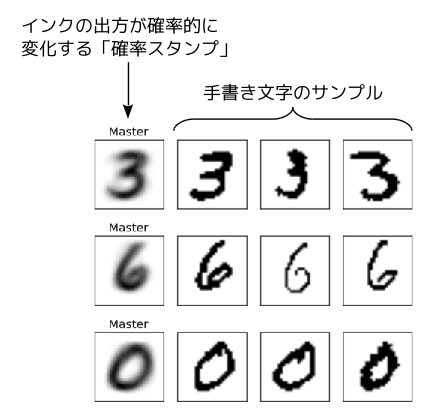
図2 代表文字との類似度による分類
このスタンプを何度も押すと、押すごとに異なる画像が得られます。そして、ある手書き文字の画像が与えられた際に、「確率スタンプを押した時に、与えられた手書き文字と同じ画像が得られる確率」を計算します。まったく同じ画像が得られるというのは、相当に低い確率のような気もしますが、たとえ小さな値であっても、何らかの確率は出てきます。この確率の値を代表文字に対する「類似度」として定義します。図2の例では、「0」「3」「6」の3種類の代表文字があり、いくつかの手書き文字のサンプルについて、類似度が最も高い代表文字を判別して、右側に並べてあります。
これで、代表文字との類似度が計算できましたが、そもそも「代表文字」はどうやって用意すればよいのでしょうか? これは、前回に説明した、「k平均法によるクラスタリング」に類似の手続きを用います。k平均法では、まずはじめに適当な代表点を用意して、どの代表点に近いかによって、データをグループ化しました。その後、各グループの重心として、新たな代表点を決定します。
ここでは、図2と同様に、「0」「3」「6」の3種類の手書き文字のサンプルが大量にあるものとします。まずはじめに、図1の左端にあるような、ランダムな画像を3つ用意して、これを仮の「代表文字」とします。その後、手書き文字のサンプル群について、3種類の「代表文字」との類似度を計算します。最初は、意味不明の代表文字のため、類似度の値はかなり小さくなりますが、とにかく、それぞれとの類似度が決まります。
次に、それぞれの代表文字について、「その代表文字との類似度の重みで、すべての手書き文字を合成した画像」を作り、これを新たな代表文字とします(図3)。図1の例では、左下の「ランダムに生成した代表文字」は、偶然にも「6」の手書き文字との類似性が高いようで、次の代表文字(ステップ1)は、「6」の影が強く写っています。一方、左上の代表文字は、特定の文字との類似性が高いわけでなく、次の代表文字(ステップ1)は、さまざまな数字が混在しているようです。
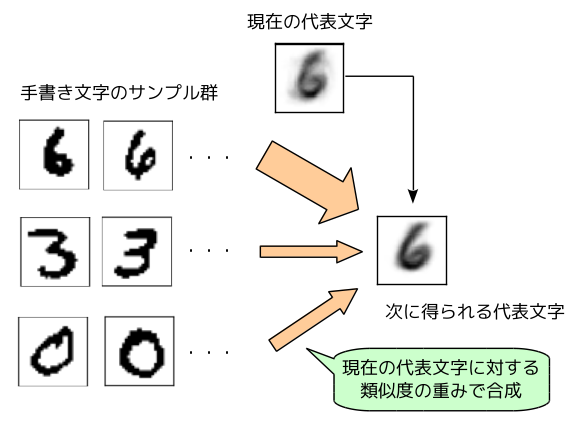
図3 新しい「代表文字」の作り方
この後は、これと同じ処理を繰り返します。左上の例であれば、ステップ1との類似度にもとづいて、新しい代表文字(ステップ2)を作ると、今度は「0」の影が濃くなりました。どうやら、ステップ1は、「0」との類似性が高かったようです。ステップ2の代表文字は、「0」との類似性がさらに高くなっており、この手順を繰り返すことで、きれいな「0」へと近づいていきます。他の代表文字は、それぞれ「3」と「6」に近づいています。
このように、確率による類似度でデータを分類していく方法が「EMアルゴリズム」になります。最初に生成したランダムな代表文字によって、その後の処理が変化するので、必ずしも適切な分類が行われるとは限りません。実際には、何度か処理をおこなって、その中から最適と思われる結果を採用するのなどの工夫を行います。
今回は、「確率スタンプ」というユニークな発想で、手書き文字の類似度を判別する方法を紹介しました。これは、数学的には「混合ベルヌーイ分布」と呼ばれる確率になります。数式を使わずに説明したので、厳密には不正確な部分もありますが、「機械学習理論」の面白さを感じられたのではないでしょうか。6月に開催するセミナー『ソフトウェアエンジニアのための「機械学習理論」入門』では、数式を用いたもう少し正確な解説も行いますので、ご期待ください。
なお、冒頭で紹介したナンバープレートの画像解析技術については、実は、解説論文が公開されています(*1)。この技術では、事前に高解像度のナンバープレート画像を集めておき、低解像度の画像との類似度を学習しています。変換前の画像を分析して、類似度の高い高解像度画像を選び出した後に、類似度の割合で合成するという処理をしているようです。つまり、事前に高解像度の画像を用意しておき、これらを合成することで、画像の復元を行っているというわけです。
さて、今週は、米国ノースカロライナ州のRaleighにある、Red Hatの本社オフィスに出かけてきます。OpenShiftの開発メンバーと、OpenShift v3の情報交換を行う予定です。次回は、Raleighからの最新情報をお届けしたいと思います。
*1 「高倍率・高精細を実現する事例ベースの学習型超解像方式(PDF)」
++ CTC教育サービスから一言 ++
このコラムでLinuxや周辺技術の技術概要や面白さが理解できたのではないかと思います。興味と面白さを仕事に変えるには、チューニングやトラブルシューティングの方法を実機を使用して多角的に学ぶことが有効であると考えます。CTC教育サービスでは、Linuxに関する実践力を鍛えられるコースを多数提供しています。興味がある方は以下のページもご覧ください。
CTC教育サービス Linuxのページ
http://www.school.ctc-g.co.jp/linux/

| 筆者書籍紹介 Software Design plusシリーズ 「独習Linux専科」サーバ構築/運用/管理 ――あなたに伝えたい技と知恵と鉄則 本物の基礎を学ぶ!新定番のLinux独習書 中井悦司 著 B5変形判/384ページ 定価3,129円(本体2,980円) ISBN 978-4-7741-5937-9 詳しくはこちら(出版社WEBサイト) |
 |
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































