
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
こんにちはー。野田貴子です。今回も英語が苦手な方向けに海外の人気コラムを意訳したものをご紹介します。
VMwareの研修を検討されている方は、実績も受賞歴も豊富なCTC教育サービスにどうぞ!
※VMware研修コース (https://www.school.ctc-g.co.jp/vmware/index.html)
画像処理装置(GPU)は、グラフィックスを重視するアプリケーション、たとえば3DモデリングソフトウェアやVDIインフラストラクチャを実行する際に使用されるハードウェアデバイスとして主によく知られています。消費者市場では、GPUは主にゲームグラフィックを高速化するために使用されています。今日、GPGPU(汎用GPU)は、現代のハイパフォーマンスコンピューティング(HPC)の世界においてコンピューターワークロードを加速するためのハードウェアの好手となっています。
HPC自体は、機械学習(ML)、ディープラーニング(DL)、人工知能(AI)のようなワークロードを処理するプラットフォームです。GPGPUを使用するのはもはや画像認識を必要とするML関連の処理だけではありません。表形式データの処理もまた、ヘルスケア、保険、金融業界の分野で一般的な課題なのです。しかし、なぜこれらの種類のワークロードすべてにGPUが必要なのでしょうか。このブログ記事では、GPUのアーキテクチャについてと、GPUがvSphere ESXi上で実行されているHPCワークロードに適切である理由について解説いたします。
まず、中央処理装置(CPU)とGPUの主な違いを見てみましょう。一般的なCPUは、操作をすばやく切り替える機能を維持しながら、できるだけ短い待ち時間でできるだけ速くタスクを完了するように最適化されています。この本質は、タスクを直列化して処理することにあります。一方GPUはスループットを最適化するものであり、できるだけ多くのタスクを一度に実行することを可能にしています。これはタスクを並列処理することで実現されています。次の図はCPUとGPUの「コア」数を示しています。両者の主な違いは、GPUにはタスクを処理するためのコアがはるかに多いことです。
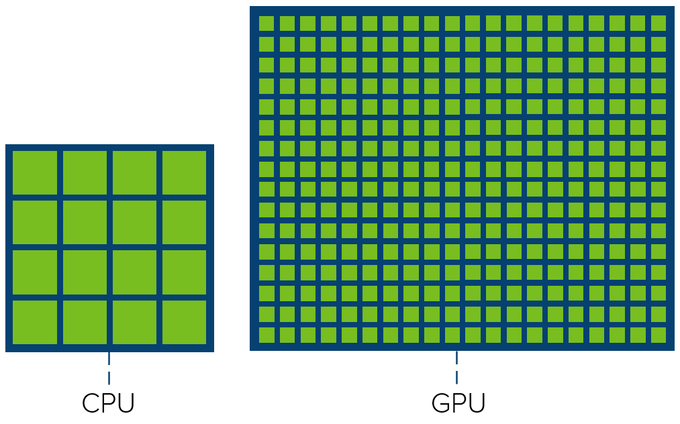
しかし、違いはコア数だけではありません。NVIDIA GPUのコアとは、ALU(Arithmetic Logic Unit)で構成されるCUDAのコアを指します。用語はベンダーによって異なるかもしれません。
CPUとGPUの全体的なアーキテクチャを見ると、2つの間には多くの類似点があります。どちらのメモリも、キャッシュレイヤ、メモリコントローラ、グローバルメモリから構成されています。最新のCPUアーキテクチャの簡単な概要では、重要なキャッシュメモリレイヤを使用することによって、アクセスの待ち時間が減るものであることが示されています。では、一般的なメモリ中心の最新のCPUパッケージを示す図を見てみましょう(注:正確な構成はベンダーやモデルによって大きく異なります)。
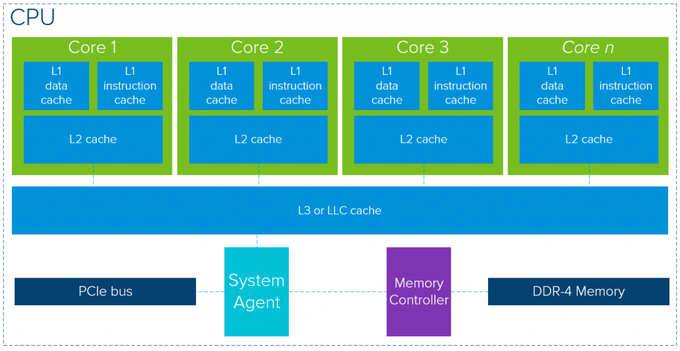
1つのCPUパッケージはレイヤ1にデータと命令のキャッシュをそれぞれ持ち、レイヤ2のキャッシュもサポートしています。レイヤ3のキャッシュ、つまり最終レベルのキャッシュは複数のコアで共有されます。データがキャッシュレイヤに存在しない場合は、グローバルのDDR-4メモリからデータを取得します。メイクとモデル次第ですが、CPUあたりのコア数はTurboモードで最大2.5 GHz~3.8 GHzで稼働して、最大28~32になります。キャッシュサイズはコアごとにレイヤ2のキャッシュが最大2MBです。
GPUアーキテクチャの簡単な概要を見てみると(こちらもメイクとモデルにに強く依存しますが)、GPUの本質は使用可能なコアを稼働させることがすべてであるため、キャッシュメモリアクセスの待ち時間の短さにはあまり焦点が当てられません。
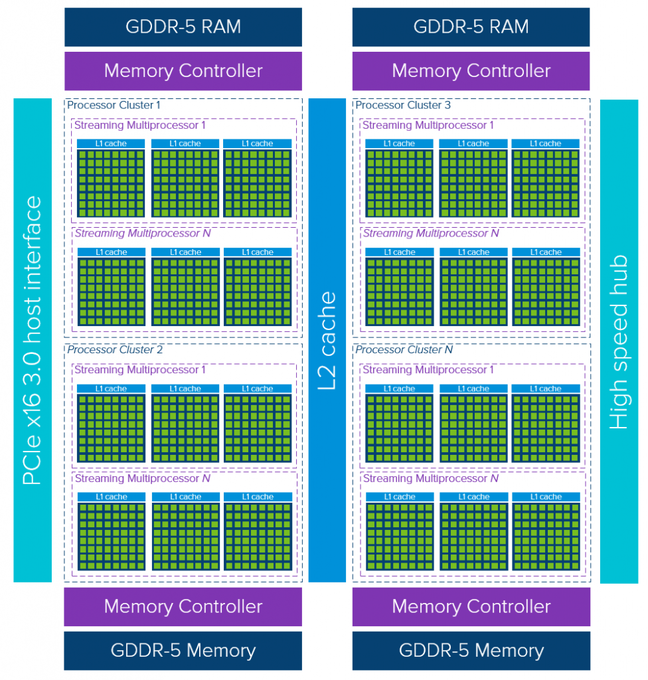
1つのGPUデバイスは、複数のストリーミングマルチプロセッサ(SM)を含む複数のプロセッサクラスタ(PC)で構成されています。それぞれのSMは関連付けられたコアとともにレイヤ1の命令キャッシュレイヤを収容しています。通常、1つのSMはグローバルなGDDR-5メモリからデータを取得する前に、専用のレイヤ1キャッシュと共有のレイヤ2キャッシュを使用します。このアーキテクチャはメモリの待ち時間を許容します。
CPUと比較して、GPUは少ない、そして比較的小さいメモリキャッシュレイヤで動作します。その理由は、GPUには計算専用のトランジスタが多いため、メモリからデータを取得するのにかかる時間が短くなることによります。潜在的なメモリアクセスの「待ち時間」は、GPUが十分な処理余力を手元に持ちつつビジー状態に保っている限りは露見しません。
GPUはデータ並列スループット処理のために最適化されているのです。
コアの数を見れば並列処理の可能性がすぐにわかります。現在のNVIDIAの主力製品であるTesla V100を分析すると、1つのデバイスに80個のSMがあり、それぞれに64個のコアがあり、コアの合計は5120になります。タスクは個々のコアにスケジュールされるのではなく、プロセッサクラスタとSMにスケジュールされます。そのため、並行処理が可能になります。この強力なハードウェアデバイスをプログラミングフレームワークと組み合わせることで、アプリケーションはGPUの処理能力を最大限に活用することができます。
VMware vSphere ESXiはGPUの使用をサポートしています。DirectPath I/Oを使用してGPUデバイスをVM専用にすることも、共同開発されたNVIDIA GRIDの技術やBitFusionのようなサードパーティツールを使用してパーティション化されたvGPUをVMに割り当てることもできます。vSphere ESXiのGPUサポートの内容や、GPUの構成方法を完全に理解するために、以下のブログシリーズをご覧ください。
ハイパフォーマンスコンピューティング(HPC)は、高度なアプリケーションプログラムを効率的に、確実に、迅速に実行する並列処理を活用しています。
GPUがHPCのワークロードにとって最適である理由はまさにこのためです。GPUを使用するとスループットが大幅に向上するため、ワークロードはGPUを使用することで大きなメリットを得ることができます。GPUを使用するHPCプラットフォームは、VMware vSphere ESXiハイパーバイザー上で実行すると、はるかに用途が広く、柔軟で、効率的になります。GPUベースのワークロードではGPUのリソースを非常に柔軟で動的な方法で割り当てることができるのです。
※引用元
https://blogs.vmware.com/vsphere/2019/03/exploring-the-gpu-architecture-and-why-we-need-it.html
※本コラムはVMware社が公式に発表しているものでなく、翻訳者が独自に意訳しているものです。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































