
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
こんにちは、藺藤です。
今回のコラムでは、新しくリリースされた「Ruby 2.3」と、前回のコラムの続きで「Ruby技術者認定試験ゴールド試験のポイント」をご紹介します。
昨年末にRubyの新しいバージョン「Ruby 2.3.0」がリリースされました。(*1) 早速、私も触ってみました。 様々な更新内容を含むリリースでしたが、その中でも特に以下のものが便利だと感じましたのでご紹介します。
入れ子になったHashやArrayから、深い場所にある値を取り出すメソッドです。 次のように利用します。
{a: {b: {c: :d}}}[:a][:b][:c] #=> :d
{a: {b: {c: :d}}}.dig(:a, :b, :c) #=> :d
#[]を使った値の取り出しと#digの利用の違いは、#digの場合には途中に値が存在しない場合に例外を発生させず、代わりにnilを返すことです。
{a: {b: {c: :d}}}[:a][:unknown_key][:c] #=> NoMethodErrorが発生
{a: {b: {c: :d}}}.dig(:a, :unknown_key, :c) #=> nil
深い位置にある値を取り出したいが、途中の要素が値を持たない可能性があるとき、#digを利用すると便利です。 存在チェックの処理を省いて、すっきりとコーディングできるようになります。
上の例ではHashが入れ子になったものに対して#digを使ってみましたが、ArrayやHashのような"コンテナ"以外のインスタンス(例えばFixnumクラスのインスタンス)に対して#digを呼び出すとTypeErrorが発生します。 これによって、
を区別できます。
Ruby 2.3では新たなメソッド呼び出し記法『&.』がサポートされます。 『&.』は通常のメソッド呼び出し『.』と挙動が異なり、Railsの#tryに似た挙動を持ちます。
#『.』を使ったメソッド呼び出し nil.undefined_method #=> NoMethodError #『&.』を使ったメソッド呼び出し nil&.undefined_method #=> nil # Railsの#try nil.try(:undefined_method) #=> nil
ただし、Railsの#tryとは少し違った挙動をする点も覚えておきましょう。
#『.』を使ったメソッド呼び出し 'some_text'.undefined_method #=> NoMethodError #『&.』を使ったメソッド呼び出し 'some_text'&.undefined_method #=> NoMethodError # Railsの#try 'some_text'.try(:undefined_method) #=> nil
上で例を示したメソッドに加え、似たような働きをするメソッドとしてRailsの#try!が挙げられます。 メソッド呼び出しには幾つかの方法がありますが、どれを使うのが便利なのかはケースバイケースだと思います。 それぞれの振る舞いの違いを押さえておきたいですね。
言葉で説明しても少々わかりにくい部分もありますので、挙動の違いを表にまとめました。
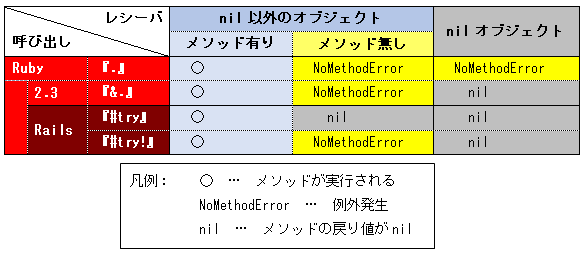
なお、Ruby 2.3以前では『&.』を使うことはできません。 SyntaxErrorが発生しますのでご注意ください。
今回のバージョンアップ内容を見て、筆者は、自分が初めてRubyに触った頃のことを思い出しました。 以下のようなコードがときどき原因不明のエラーに見舞われ、初学者の私は混乱しました。
def user_name (mail_address) mail_address.split("@").first #=> NoMethodError end
引数のmail_addressには"user@mail.com"のような文字列が渡されることを期待しています。 このメソッドは、メールアドレスのうち"@"よりも前の部分を「ユーザ名」として切り出すためのものです。
#user_nameメソッドは引数mail_addressにメールアドレス形式の文字列が格納されているときには正しく動作します。 しかし、実際のデータを使って動かしてみるとNoMethodErrorが発生してしまいました。 一体何が原因なのか、読者の皆様は特定できますか?
しばらく格闘した後、私は原因を見つけました。 それは、mail_address の値が何らかの事情でnilだったため、NilClass#splitというメソッドを呼び出そうとしてしまいエラー発生していました。 もちろん、そのようなメソッドは存在しないため例外が発生します。
ひとたび原因がわかってみると、このようなエラーに対して"NoMethodError"というエラーメッセージは不親切だと感じました。 コーディングした側から見ると、エラー原因は「メソッドが無いから」というよりも「レシーバがnilだから」の方が直接的です。 例えば"NilReceiverError"なんて名前だったらもう少し早く原因を特定できたかもしれません。(もちろん、NoMethodErrorと"NilReceiverError"の違いをRubyに理解させるのは少々大変そうですが。)
さて、新しく導入された記法『&.』を使うと以下のようになります。
mail_address = nil mail_address&.split("@")&.first #=> nil
メールアドレスを登録していないユーザもいることでしょう。 このようにユーザ側に起因する原因によって処理を行えない場合は、例外を発生させるよりも単にnilを返す方が便利なときもあります。 例えば、次に示すように"デフォルト値"を設定することができます。
# mail_addressがblankの場合、戻り値は "Guest" def user_name (mail_address) mail_address&.split("@")&.first || "Guest" end
一方、次の例ではメールアドレスを格納する(=値は文字列であることを期待している)変数に、数値型の値が格納されています。 このように、#user_nameメソッドの作成者の意図に反した使い方がなされるケースは、メソッドを利用するプログラマ側のコーディング・ミスや勘違い等の可能性があります。
mail_address = 123 mail_address&.split("@")&.first #=> NoMethodError
この場合はNoMethodErrorを発生させることで、何か不都合なことが起きたとプログラマに伝えることができます。
Ruby 2.3では、ここでお伝えした以外にも多くの新機能が追加されていますので、ぜひ一度リリースノートをご覧ください。(*1)
前回のコラム(第24回)ではRuby技術者認定試験ゴールド試験を合格するためのポイントとして「オブジェクト指向」の学習方法をご説明しました。(ゴールド試験の試験範囲や、お勧めの参考書等は前回のコラムをご覧ください。)
今回はゴールド試験の出題範囲のうち「オブジェクト指向」以外の部分から、以下の3つを取り上げて説明していきたいと思います。
(1) キーワード引数
(2) ラムダ式 (->)
(3) Refinements
以下でコード例を示してゆきますが、是非、お手元の環境で実行して結果を確認しながら読み進めていってください。 学習の際にはirbの利用が便利です。 冒頭で紹介したように現在のRuby最新バージョンは2.3系ですが、試験対策という意味では2.1系を使用することを強くお勧めします。
なお、ここから下のコードは筆者の使っているWindows環境、Ruby 2.1.6で動作を確認しています。
キーワード引数はRuby 2.0で導入されました。 また、Ruby 2.1で更に機能が強化されています。 キーワード引数を持つメソッドと、通常のメソッド(キーワード引数を持たないメソッド)の定義および実行をそれぞれ見てみます。
# 通常の引数を持つメソッドの定義と実行 def english(s, v, o) puts "#{s} #{v} #{o}" end english('You', 'Watch', 'Movie') #=> You Watch Movie # キーワード引数を持つメソッドの定義と実行 def english2(s:, v:, o:) puts "#{s} #{v} #{o}" end english2(s: 'I', v: 'Read', o: 'Book') #=> I Read Book
2つ以上の(通常の)引数を持つメソッドを呼び出す場合、「何番目の引数に、どの値を渡したのか」が重要な意味を持ちます。 このため、次の2つのメソッド呼び出しは異なった結果となります。
english('You', 'Watch', 'Movie') #=> You Watch Movie english('Watch', 'Movie', 'You') #=> Watch Movie You # != You Watch Movie
一方、キーワード引数を持つメソッド呼び出しの場合はちょうどHashのようにキーとバリューのペアを用いて「どの引数に、どの値を渡したのか」を表現します。 引数の順番は重要ではありません。 次のコードを見てください。 上の例とは異なり、2つの実行結果が同じになることに注意してください。
english2(s: 'I', v: 'Read', o: 'Book') #=> I Read Book english2(v: 'Read', o: 'Book', s: 'I') #=> I Read Book
メソッドの引数にはデフォルト値を与えることができます。 これも確認しておきましょう。
# 通常の引数は "="(イコール)を使ってデフォルト値を指定する def english3(s = 'I', v, o) puts "#{s} #{v} #{o}" end english3('Watch','Movie') #=> I Watch Movie # キーワード引数の場合は":"(コロン)を使ってデフォルト値を指定する def english4(s: 'You', v:, o:) puts "#{s} #{v} #{o}" end english4(v: 'Read', o: 'Book') #=> I Read Book
最後に可変長引数の利用を見てみます。
# 可変長引数は "*"(アスタリスク)を使って指定する def english5(s, v, *oo) puts "#{s} #{v} #{oo.join(' ')}" end english5('He', 'Saw', 'His', 'Ex-girlfriend', 'Yesterday') #=> He Saw His Ex-girlfriend Yesterday # キーワード引数の場合は"**"を使って指定する def english6(s:, v:, **oo) puts "#{s} #{v} #{oo.values.join(' ')}" end english6(s: 'I', v: 'Think', o: 'Her' , c: 'Kind') #=> I Think Her Kind
ここまで見てきたキーワード引数の性質は以下のような場合に活用できます。
①メソッドに渡されている値がどのようなものか明示させたい(⇔キーワード引数の利用)
②メソッドの挙動に影響を与えるオプションを指定可能にしたい(⇔デフォルト値の利用)
③必須項目とオプション項目の両方を指定可能にする(⇔可変長引数の利用)
実際には①~③を全て同時利用することも多くはないでしょうが、少し強引ですが、最後に例として"メールマガジンを送信するメソッド"を示します。
# [必須項目] subject: 件名, body: 本文, to: 送信先メールアドレスの配列 # [オプション項目] from: 差出人, options: オプション項目 def send_mail_magazine(subject:, body:, to:, from: 'merumaga@zenet.japan', **options) (メソッドの中身は省略します) end send_mail_magazine( subject: "Ruby on Rails 5がリリースされました!", body: 'このメールは弊社メルマガを購読されているお客様にお送りして...', # デフォルト値を上書き、またtoと順序交換 from: 'rails@zenet.japan', to: ["abc@AAAA.comp", "xyz@BBBB.co.japan", "zyx@CCCC.comp"], message_id: 'zenet-2016-xx-yy', x_priority: 2 )
fromを省略した場合にはデフォルト値である'merumaga@zenet.japan'が使われます。 今回はメソッド呼び出し時にfromの値を指定しました。 また、メソッド定義時とは異なる順序でfrom, toを指定していますが、キーワード引数を使っているため問題なく動作します。 subjectやbody, to以外に付加的な情報が必要な場合、メソッド定義時に**optionsを用意していますので、メソッドに渡すことができます。 メソッドの中でmessage_idや、x_priorityの値を取り出したい場合には次のようにします。
def send_mail_magazine(subject:, body:, to:, from: 'merumaga@zenet.japan', **options) (メソッドの中身は省略します) puts "Message-ID: #{options[:message_id]}" puts "X-Priority: #{options[:x_priority]}" end
optionsはただのHashですので、いつものHashと同じように利用できます。
まず初めに、ラムダ式とlambdaメソッドの使い方を示します。
a = 2 # lambda メソッド lam = lambda{|x| x + a } lam.call(3) #=> 5 # ラムダ式 (->) lam2 = ->(y){ y + a } lam2.call(-1) #=> 1 # (参考) 通常のメソッド def met3(z) ; z + a ; end met3(4) #=> NameError: undefined local variable or method 'a'
lambdaに続けてブロックを与え、ブロック内に実行したい処理を書きます。 この時点ではブロックの中身は実行されません。 実行するにはProc#callを使います。 #callに渡した引数は、ブロック変数に代入されます。 ちょうど通常のメソッドの引数のように使えます。(この点はlambdaメソッドよりもラムダ式の表記の方が直感的だと思います。)
コード(特にラムダ式)を一見すると、
①まずメソッドを定義して
②後にメソッド呼び出す
といったようにも見えます。 しかし、ラムダ式がメソッドと違う特徴がスコープを持つ点です。 コードの最初に用意した a = 2 を利用して計算を行っています。 これはラムダの外側の変数ですが、スコープを持つために計算を実行可能です。
一方、メソッドでは同様のことは実現できません。 参考として、"似たような"メソッドを作成しましたが、メソッドmet3を実行すると「ローカル変数(またはメソッド)aが見つからない」とエラーになります。
lambdaと合わせて覚えておきたい仲間がProcです。(Procの仲間がlambdaです、の方がより正確な表現です。) Procの仲間達の違いはreturn/breakした際の挙動や、ブロック変数に対して大らかかそれとも厳密か、スコープは継続されるか独自か、といった点です。 Procの挙動を見てみましょう。
# return及びbreakを実行すると例外発生する p1 = Proc.new do return end p1.call #=> LocalJumpError: unexpected return p2 = Proc.new do break end p2.call #=> LocalJumpError: break from proc-closure # nextより下の処理は実行されない p3 = Proc.new do puts "A" next puts "B" end p3.call #=> A
Procの内部でreturnやbreakはできません。 これはLocalJumpErrorという例外を発生させます。
returnやbreakとは違い、nextは問題なく呼び出すことができます。 これは"メソッドのreturn"と同様に動作します。 nextに対して戻り値を渡すことができます。 また、nextよりも下の部分は実行されません。
もう一つ例を見てみます。
p4 = Proc.new do |x, y, z| x + y + z end p4.call(2, 3, 4) # 戻り値は「9」。 x, y, zはそれぞれ2, 3, 4 p4.call(2, 3, 4, 5) # 戻り値は「9」。 4つ目の引数「5」は単に捨てられる。 p4.call(2, 3) # 例外発生。 zはnilであり、数値(= x + y)と足せない。
Procは引数の数に対しては大らかで、引数の数とブロック変数の数が一致しない場合でも例外は発生しません。(最後の例ではzの値はnilとなっています。 この例では例外発生しますが、これはあくまで「数値とnilを足せないために起きたTypeError」です。)
同様の実験をProc/lambdaとその仲間達に行ったときのそれぞれの挙動をまとめておきます。 ここでは#lambda, #proc, Proc.newを取り上げます。 また、参考としてメソッド、ブロックも掲載します。 表中のlambda/procは、メソッドに近いものから、ブロックに近いものへと整列させました。

#procは#lambdaと同様に利用できますが、このメソッドの挙動はProc.newに近いものです。 #procはRubyのバージョンによって振る舞いが変わっていますので、注意してください。 Ruby 2.1では上の表に示したようにProc.newと極めて近い挙動となります。
今回のコラムで最後に取り上げるのはRefinementsです。 これはRuby 2.1から導入された機能です。 初めにrefinementsと関係のあるオープン・クラスを見てみます。
Rubyの特徴的な点ですが、既存のクラスに対して自由にメソッドを追加できます。 また、削除したり挙動を変更したりすることも可能です。 このような性質をオープン・クラスと呼びます。
# オープンクラス [:a, :b, :c, :d, :e].each_odd do |e| puts e end #=> NoMethodError class Array def each_odd each_with_index do |e, i| next if i % 2 == 0 yield e end end end [:a, :b, :c, :d, :e].each_odd do |e| puts e end #=> b #=> d
ArrayクラスはRubyに元々組み込まれているクラスですが、例では奇数番目のインデックスを持つ要素のみを繰り返す、Array#each_oddというメソッドを追加しました。
オープン・クラスは非常に便利で強力なものですが、大きな難点も抱えています。 それは一度クラスをオープンしたら、その影響は全ソースコードに影響する点です。 巨大プロジェクトの"どこか"で既存のクラスやメソッドが拡張・変更されていた場合、プログラマはその影響をきちんとコントロールできるのでしょうか?
Refinementsはオープン・クラスの利点を享受しつつ、影響範囲を制限する目的で導入されました。 実際にRefinementsの利用方法を見てみます。(*2)
# Refinements [:a, :b, :c, :d, :e].each_odd do |e| puts e end #=> NoMethodError module ExtArray refine Array do def each_odd each_with_index do |e, i| next if i % 2 == 0 yield e end end end end # 宣言しただけでは利用不可能 [:a, :b, :c, :d, :e].each_odd do |e| puts e end #=> NoMethodError # usingした後から有効化される using ExtArray [:a, :b, :c, :d, :e].each_odd do |e| puts e end #=> b #=> d
まずはmoduleを一つ用意し、その中でrefineを呼び出します。 refineの引数にはオープンしたいクラスを指定し、ブロックの中に内容を書きます。 今回は#each_oddを定義しました。
まだこのままでは追加されたメソッドArray#each_oddを利用することはできません。 実際に利用するにはusingを利用して予め定義しておいたモジュールを指定します。 例のように、#each_oddを利用できるようになります。 usingによる拡張の影響範囲は、ファイルの場合、記述した箇所からファイル末尾までとなります。 複数のファイルをまたぐことはないため、オープン・クラスの場合とは違い、影響範囲を最小限に抑えられます。 このため、今後はオープン・クラスよりもrefinementの利用の方が推奨されると考えられます。
前回・今回と2回に渡り、「Ruby技術者認定試験に合格しよう! ゴールド編」をお送りしました。 試験範囲の中でも重要なオブジェクト指向の理解(前回)と、比較的新しい文法(今回)を取り上げました。 ぜひ、お手元の環境にRuby 2.1を用意して、実際にコードを打ちながら理解していってほしいと思います。 ゴールド試験の試験範囲を学習することで、より深化したプログラミングができるようになるはずです!
それでは、Enjoy Ruby!
*1:「Ruby 2.3.0 リリース」
https://www.ruby-lang.org/ja/news/2015/12/25/ruby-2-3-0-released/
*2:Refinementを試すときには、ファイル上に記述した上で実行してください。 irbを使った場合にはサンプルコードはうまく動作しません。
*3:Procとその派生の挙動の説明としてはこちらが参考になります。
http://docs.ruby-lang.org/ja/2.1.0/method/Kernel/m/proc.html
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes






























