
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、久しぶりにGlusterFSの話題をお届けします。実は、この話題には裏話があります。本コラムの第3回にも登場した「GlusterFS Community Manager」のJohn Markから、突然、次のようなメールが届いたのです。――「日本でpmuxっていう面白そうなツールを作っている人がいるみたいだね。5月末のLinuxCon Japan 2013の際に日本に行くんだけど、よかったら紹介してくれない?」
思わずPCに向かって、「知らんがな・・・」と呟いてしまいましたが、世間は狭いもので、よくよく調べてみると筆者の「知り合いの知り合い」がpmuxの作者ということが分かりました。さっそく連絡を取って、pmuxについて教えてもらったのですが、GlusterFSの分散ファイルシステムを利用してMapReduceの処理を実装したもので、なかなか興味深いツールであることが分かりました。
今回は、MapReduceの基礎を説明した上で、GlusterFSがどのようにMapReduceに活用できるのか、なるべく平易に解説してみたいと思います。
MapReduceは、2004年に米Google社のエンジニアが論文で公開した、分散データ処理の手法です。手法そのものは驚くほど単純で、多数のレコードからなるデータに対して、つぎの3つのステップで処理を実施します。
Map処理とReduce処理において、具体的にどのような処理をするかは、利用者が定義します。よくある例ですが、「ワードカウント」の場合は次のようになります。1万ページの書籍について、1ページの文書を1レコードと考えます。
この時、Map処理とReduce処理は、複数のサーバで並列に処理できるところがミソになります(図1)。1万ページの書籍に対して、1万台のサーバがあれば、Map処理(ページごとの単語数のカウント)については、1台あたり1ページの処理で済みます。また、Map処理の結果、得られた「単語」の種類が5000語であれば、Reduce処理(「単語」ごとの「出現回数」の合計)は、5000台のサーバで並列処理すれば、1台あたり1つの単語を処理するだけです。
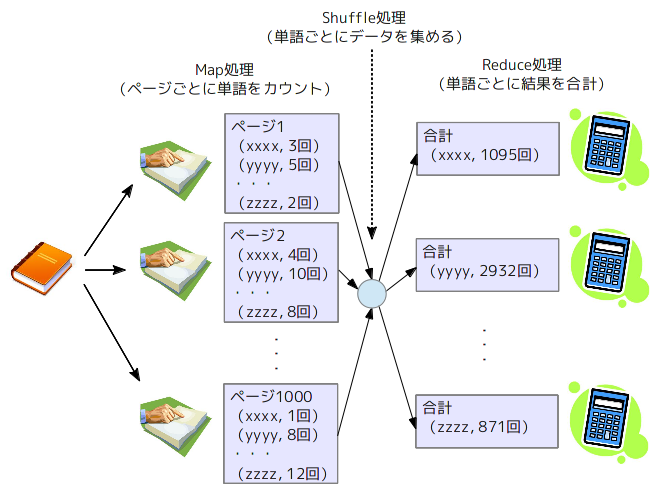
図1 MapReduceによる「ワードカウント」の流れ
世の中のすべてのデータ処理がこのパターンに当てはまるとは限りませんが、ネットワーク通信量のグラフ化やアクセスログの集計などには最適で、データセンタのネットワーク担当者やWebシステムのシステム管理者の間では標準的なツールになっているようです。
多数のサーバでMapReduce処理を実施する場合、処理対象のデータをどのように大量のサーバに配布するかを考える必要があります。MapReduceと言えば、オープンソースのHadoopが有名ですが、Hadoopの場合は、HDFS(Hadoop Distributed File System)という専用の分散ファイルシステムを利用します。HDFSに保存したファイルは、一定サイズのブロックに分割されて、ブロック単位で複数ノードに分散配置されます(*1)。
一方、GlusterFSの場合は、ファイル名のハッシュ値によって、ファイル単位で複数ノード(ストレージノード)に分散配置されます。そこで、pmuxでは、クライアント上で、あらかじめ処理対象のデータを複数ファイルに分割してGlusterFSのボリュームに保存します。これにより、自動的に複数ノードのローカルディスクに対して、データが分散配置されることになります(図2)。あとは、各ストレージノードにおいて、ローカルディスクに保存されたファイルを用いてMap処理を実施します。
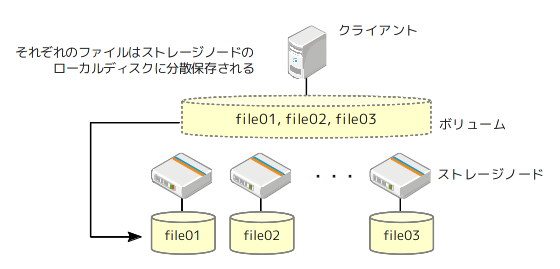
図2 GlusterFSにおけるファイルの分散配置
各ストレージノードでGlusterFSのファイルシステムをマウントすれば、ボリューム内のすべてのファイルにアクセスすることができますが、処理性能を上げるために、あくまでローカルに保存されたファイルを利用します。Map処理の結果は、Keyの値ごとに同じサーバに集められて、そこでReduce処理が実施されます。
ただし、pmuxでは、Map処理で得られたデータをKeyの値ごとに同じサーバに集める部分(Shuffle処理)は、pmux自身がネットワーク転送処理を行なっています。特にGlusterFSの機能を活用しているわけではありません。
ここで、筆者の頭に浮かんだのは、「この部分についても、GlusterFSの仕組みが活用できるのでは?」という疑問でした。一例として、Map処理の結果をGlusterFSのファイルシステム上のファイルに書き込んでいく方法が考えられます。Keyの値ごとにファイル名を決めて、同じKeyのデータは同じファイルに追記していけば、同じKeyのデータがまとめて1つのサーバに保存されます。あとは、このサーバでReduce処理を実施します。
――思いついたらすぐに試してみたくなるのが、エンジニアの性分です。pmuxをいきなり改変するのは大変ですので、まずは、アイデアの有効性を確認するために、スクラッチでプロトタイプを作成してみました。「簡易版(Simplified)pmux」ということで、spmuxと名付けました。
ちなみに、本家pmuxでは、MessagePack-RPCによる非同期通信を用いて、ジョブスケジューリングなどの処理を行なっています。一方、spmuxでは、全ノードに一斉にジョブを投げて、各ノードがローカルにあるファイルを処理するという単純化を図っています。レプリケーション構成で複数ノードに同じファイルがある場合は、GlutsterFSのファイルロック機能を利用して、特定ノードだけが処理を行う仕組みを入れてあります。
pmuxの作者にspmuxを紹介したところ、最後に触れたジョブスケジューリングを単純化するアイデアが気に入ったようで、pmuxにも適用できないか検討してみたいとのことでした。筆者も時間をみつけて、pmuxのコードを読んでみようかと目論んでいます。
次回は、GlusterFSに関連する話題をもう1つお届けします。分散型のSambaファイルサーバを構成するCTDBというツールをGlusterFSと組み合わせる手法です。冒頭のJohn Markのメールにあった、「LinuxCon Japan 2013」で発表する予定のネタなのですが、本コラムの読者の皆様には、一足先に紹介してみたいと思います。
*1)「大規模データの新たな価値を生み出す「Hadoop」(解説編)」
少し古い記事ですが、Hadoopの仕組みについて分かりやすく解説されています。
++ CTC教育サービスから一言 ++
このコラムでLinuxや周辺技術の技術概要や面白さが理解できたのではないかと思います。興味と面白さを仕事に変えるには、チューニングやトラブルシューティングの方法を実機を使用して多角的に学ぶことが有効であると考えます。CTC教育サービスでは、Linuxに関する実践力を鍛えられるコースを多数提供しています。興味がある方は以下のページもご覧ください。
CTC教育サービス Linuxのページ
http://www.school.ctc-g.co.jp/linux/

| 筆者書籍紹介 Software Design plusシリーズ 「独習Linux専科」サーバ構築/運用/管理 ――あなたに伝えたい技と知恵と鉄則 本物の基礎を学ぶ!新定番のLinux独習書 中井悦司 著 B5変形判/384ページ 定価3,129円(本体2,980円) ISBN 978-4-7741-5937-9 詳しくはこちら(出版社WEBサイト) |
 |
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































