
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
私事ではありますが、4月から某国立大学で大学院生向けに「クラウド基盤構築」の講義を担当することになりました。もともとは、昨年から社会人向けに実 施していた同名のコースがあったのですが、「同じ内容を大学院生にも提供して欲しい」との依頼を受けて、実現に至りました。
インフラ技術の面白さは、業務の実体験を通して理解する部分も多いですので、大学院生のみなさんに、インフラ技術中心の講義にどれだけ関心を持っていただけるか、少し不安もあります。しかしながら、さまざまな技術要素の的確な組み合わせこそが、あらゆるITインフラ構築の「肝」ですから、まずは、1つ1つの技術要素を丁寧に伝えていきたいと考えています。講義資料は、こちらで公開していますので、興味のある方は参考にしてください。
さて、今回は、HAクラスタの話題です。ご存知の通り、High Availability Cluster、すなわち、「高可用性クラスタ」のことです。アプリケーションが稼働するサーバが障害で停止した際に、他のサーバでアプリケーションの実行を自動的に再開する仕組みを提供します。
HAクラスタの仕組みは古くからありますが、最近は、クラウド上で「高可用性」をどのように実現するべきかということで、HAクラスタとクラウドの関係が話題になることがあるようです。
UnixサーバでのHAクラスタの利用は、1990年代から広がりました。現在、Linuxで利用されるHAクラスタも基本的な仕組みは同じです。最も シンプルな「アクティブ・スタンバイ構成」では、2台の物理サーバを相互監視させることで、一方のサーバが障害で停止すると、もう一方が同じアプリケー ションの実行を引き継ぎます。この時、引き継ぎ前のアプリケーションが処理していたデータが失われては困りますので、アプリケーションが使用するデータは、両方のサーバに接続された「共有ディスク」に配置します。
ところが、その後、サーバ仮想化の利用が広がると、物理サーバの障害によって、その上で稼働する多数の仮想マシンが停止する、という新たな障害パターンが登場しました。サーバ仮想化環境で高可用性を実現するには、どのような方法があるのでしょうか?
1つは、図1の左側にあるように、仮想マシンのゲストOS上で、従来のHAクラスタソフトウェアを稼働する方法です。従来のやり方がそのまま利用できる代わりに、仮想マシンごとにHAクラスタを構成する必要があります。
あるいは、「仮想マシン」そのものを1つのアプリケーションと考えて、引き継ぎ先のサーバで、同じ仮想マシンを起動する方法もあります。図1の右側にあるように、アプリケーションデータの代わりに、ゲストOSのディスクイメージを共有ディスクに配置して、複数サーバで共有する形になります。
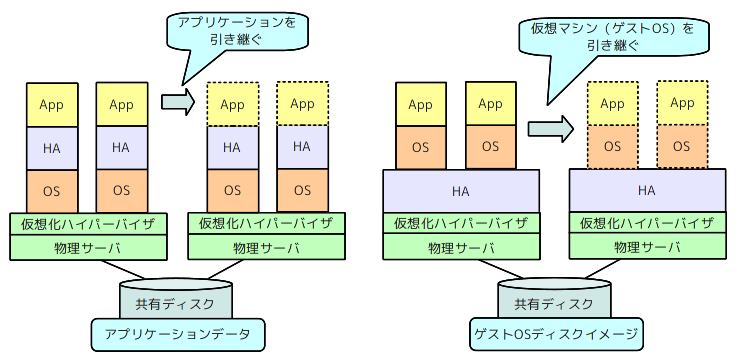
図1 サーバ仮想化環境におけるHAクラスタの2つ方式
それでは、いわゆるIaaS型のクラウドにおいて、仮想マシンの高可用性はどのように実現すればよいのでしょうか? パブリッククラウドサービスの中には、図1(右側)の方法で、仮想マシンの稼働を引き継ぐ仕組みを提供しているものもあります。
あるいは、クラウドの利用者が、独自に高可用性の仕組みを作りこむ場合もあります。外部から仮想マシンの稼働状況を監視しておき、仮想マシンが停止した際に、同じ仮想マシン環境を自動で再構成します。この場合は、「同じ仮想マシンを起動して、アプリケーションを再開させる」という処理を自動化スクリプトで実現する必要があります。
もちろん、それぞれに長所・短所があり、一概にどちらがよいとは言えません。前者の方が単純で便利な気もしますが、このためには、クラウドサービスの提供者側で、共有ディスクを利用したHAクラスタの仕組みを事前に作りこむ必要があります。一方、クラウドサービスの要件によっては、共有ディスクを使用しない構成が望まれる場合もあります。
実は、現在、OpenStackにおいて、これらの中間とも言えそうな仕組みが議論されています(*1)(*2)。この仕組みでは、障害の検知や仮想マシン(インスタンス)の再起動の指示は、利用者(もしくはシステム管理者)がAPIを通じて行います。ただし、再起動したいインスタンスだけ指定すれば、 IPアドレスの再割り当てや、外部ディスクに相当するCinderボリュームの再接続など、停止前と同じ環境を再構成する処理は、OpenStackが面倒を見てくれるというものです。
OS領域のディスクについては、共有ディスクを使用した構成であれば、停止したインスタンスのディスクイメージをそのまま利用して再起動します。あるいは、共有ディスクのない構成であれば、元のインスタンスと同じテンプレートイメージから起動します。CinderボリュームからゲストOSを起動している 場合は、同じボリュームを使って再起動します。
これを利用して、完全な形の高可用性を実現するには、インスタンスの稼働状況を監視しておき、障害発生時には、このAPIからインスタンスの再起動を指示する仕組みが必要です。クラウド上のシステム監視については、現在、さまざなツールの実装が進んでいる状況ですので、今後は、これらの監視ツールと連携していくことになるでしょう。
今回は、クラウドにおける高可用性の実現方法として、OpenStackにおける取り組みの例を紹介しました。特に、Cinderボリュームからの起動を利用すれば、共有ディスクを持たずに、ゲストOSのディスクの内容を引き継ぐことも可能です。
既存の仕組みをそのままクラウドに持ち込むのではなく、クラウド特有の仕組みを活かした構成について議論を進めることで、新しいインフラの世界が実現するという好例となるかも知れません。
さて、次回は、久しぶりにGlusterFSの話題をお届けしたいと思います。最近、HadoopのMapReduce処理に、GlusterFSを組み合わせて利用する話題を耳にすることがあります。しかしながら、簡易的な形であれば、Hadoopを利用せずに、GlusterFSに保存したファイルのMapReduce処理を実現することは可能です。そのようなツールの一例を紹介したいと思います。
*1)「Rebuild for HA」
障害ノード上のインスタンスを別ノードで再起動する機能のブループリントです。
*2)「Evacuate」
上記のブループリントの詳細説明です。
++ CTC教育サービスから一言 ++
このコラムでLinuxや周辺技術の技術概要や面白さが理解できたのではないかと思います。興味と面白さを仕事に変えるには、チューニングやトラブルシューティングの方法を実機を使用して多角的に学ぶことが有効であると考えます。CTC教育サービスでは、Linuxに関する実践力を鍛えられるコースを多数提供しています。興味がある方は以下のページもご覧ください。
CTC教育サービス Linuxのページ
http://www.school.ctc-g.co.jp/linux/

| 筆者書籍紹介 Software Design plusシリーズ 「独習Linux専科」サーバ構築/運用/管理 ――あなたに伝えたい技と知恵と鉄則 本物の基礎を学ぶ!新定番のLinux独習書 中井悦司 著 B5変形判/384ページ 定価3,129円(本体2,980円) ISBN 978-4-7741-5937-9 詳しくはこちら(出版社WEBサイト) |
 |
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































