
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Acquisition of Chess Knowledge in AlphaZero」を元にして、強化学習を適用したニューラルネットワークの「学習内容」を分析するという研究事例を紹介します。今回は、学習済みのニューラルネットワークは「人間のプレイヤーと同じ考え方を持っているのか」という点の分析になります。
学習済みの機械学習モデルが「人間のプレイヤーと同じ考え方」を持つかどうかを分析するには、まずは、「人間のプレイヤーの考え方」をモデル化する必要があります。冒頭の論文では、「Stockfish(ストックフィッシュ)の評価関数」をそのモデルとして利用しています。これは、Stockfishと呼ばれるオープンソースのチェスエンジンで採用されているもので、与えられたチェスの盤面に対して、一定のルールで複数の「スコア」を計算して、そのスコアを元にして、その盤面の価値(その盤面が自分にとってどの程度有利かを表す数値)を計算します。スコアは、「material(それぞれの駒の位置)」「imbalance(持ち駒の差異)」「mobility(駒の動きやすさ)」「king_safety(キングの安全性)」などの要素を個別に点数化したもので、人間のプレイヤーが盤面から読み取る一般的な情報に対応しています。
次に、学習済みの機械学習モデルがこれと同じ考え方、すなわち、同じ情報を予測に利用しているかを調べます。具体的には、前回の記事で説明したように、ニューラルネットワークを構成する各ブロックが出力する特徴量が同じ情報を含んでいるかを分析します。たとえば、ある特徴量が上述のスコアの1つに一致する、つまり、あらゆる盤面に対して、ある特徴量の値と上述のスコアの1つが一致したとします。この場合、この機械学習モデルは、与えられた盤面から該当のスコアを計算する方法を学んでおり、人間のプレイヤーと同じ判断ルールの1つを身につけたと言えるでしょう。実際には、特定の特徴量が特定のスコアに完全にマッチするとは考えづらいため、この論文では、あるブロックから出力される特徴量全体の一次関数で特定のスコアが計算できるかどうかを確認しています。つまり、特定のブロックから出力される特徴量を用いた線形回帰モデルで、それぞれのスコアがどこまで再現できるかを確認しようというわけです。盤面の状態と対応するスコアを学習データ、および、テストデータとして用意しておき、学習データで線形回帰モデルを学習した後に、テストデータに対する予測精度を評価します。なお、複数の特徴量を組み合わせて複雑な計算処理を行えば、原理的には、どのようなスコアでも正確に再現できる可能性があります。ここでは、単純な線形回帰モデルで再現できることを持って、特徴量が該当のスコアをダイレクトに表現しており、この機械学習モデルは、該当のスコアを予測のための情報として利用しているものと判断しています。
Stockfishの評価関数では、100種類近いスコアが定義されており、冒頭の論文では、20層のブロックについて、それぞれのブロックが出力する特徴量からそれぞれのスコアが再現できるかを検証しています。ここでは、これらの中から特徴的な2つの結果を抜粋して紹介します(図1)。
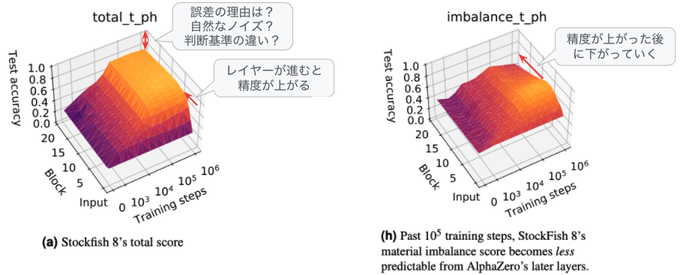
図1 特徴量によるスコアの再現結果(論文の図にコメントを追加)
図1の左は、代表的なスコアを合計した「総合スコア」に対する結果になります。左側の軸は20層あるブロックを表しており、右側の軸は強化学習による学習処理が進むにつれて結果がどのように変化するかを表します。この図からは、学習処理が進むにつれてスコアの再現精度(縦軸の値)が上がっていく事、そして、より後段のブロックに行くほど再現精度が高くなることがわかります。多層ニューラルネットワークでは、複数の層を経由する事でより複雑な計算処理を行うわけですので、直感にもマッチする結果と言えるでしょう。
一方、図1の右は、少し異なる傾向を示しています。これは、先手と後手の持ち駒の差異を元に評価したスコアですが、前段から後段へとブロックが進んでいくと、ある段数を境にして再現精度が下がっています。これは、ある段数のブロックで該当の情報を抽出した後に、それより後ろのブロックでは、この情報と他の情報を組み合わせたさらに複雑な計算処理を行っているものと考えられます。人間のプレイヤーが盤面の状況を判断する場合でも、持ち駒の差異は重要な情報ですが、これだけで優劣を判断するということはないでしょう。そのような意味でも、人間のプレイヤーに近い判断を行っているものと想像することができます。論文の付録には、これら以外にもさまざまなスコアに対する結果がまとめられています。
図1の左では、ブロックの段数が進むにつれて再現精度が上がっていますが、それでも100%の精度を達成しているわけではありません。この例では、再現精度は70%程度に留まっています。それでは、残った30%の誤差にはどのような意味があるのでしょうか? 単純に考えれば、該当のスコアの正確な再現に失敗しているというだけですが、もしかしたら、この機械学習モデルは、人間とは異なる評価基準を持っており、評価基準の違いが誤差として現れているのかも知れません。このような疑問に答えるために、冒頭の論文では、線形回帰モデルによる予測値が特に大きく外れる盤面を分析しています(図2)。
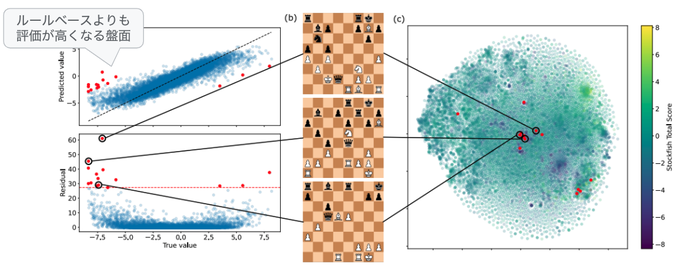
図2 線形モデルによる予測値が大きく外れる盤面の分析(論文の図にコメントを追加)
図2の左上のグラフは、横軸が実際の「総合スコア」、縦軸が線形回帰モデルによる予測値になっており、さまざまな盤面について対応する点をプロットしたものになります。線形回帰モデルの予測が正しければ、すべてのデータは斜め方向の破線の上に乗るはずですが、実際には上下にばらついており、これが予測誤差になります。特に左上部分にある赤色の点で示したデータは、線形回帰モデルによる評価が実際のスコアよりも極端に大きくなっているデータを表しています。一方、図2の右にある図は、予測に用いた特徴量をt-SNEと呼ばれるアルゴリズムでクラスタリングした結果を表します。さきほどの「線形回帰モデルによる評価が実際のスコアよりも極端に大きいデータ」をクラスタリングした図にマッピングすると、互いに近い位置に集まっています。つまり、これらのデータには何らかの類似性があり、この線形回帰モデルは、これらの類似したデータに対して「人間の評価基準よりも高い評価」を与えているということになります。言い換えると、これらのデータに対する予測結果は、単純な誤りというわけではなく、Stockfishの評価関数とは異なる独自の評価基準を与えている可能性が考えられます。
今回は、2021年に公開された論文「Acquisition of Chess Knowledge in AlphaZero」を元にして、強化学習を適用したニューラルネットワークの「学習内容」に関する研究事例に関して、学習済みのニューラルネットワークは「人間のプレイヤーと同じ考え方を持っているのか」という点の分析結果の一部を紹介しました。論文の中では、この他にもさまざまな分析が行われていますので、興味のある方は、ぜひ論文の方も参照してください。次回は、「人間のプレイヤーとは異なる独自の視点」に関する分析結果を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































