
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「CliqueMap: Productionizing an RMA-Based Distributed Caching System」を元にして、Google社内で使用されているインメモリ分散キャッシュシステム「CliqueMap」のアーキテクチャーを紹介します。今回は、システムの可用性とデータの整合性を担保する仕組みを解説します。
CliqueMapのクライアントがサーバーからデータを取得する際の処理の流れは、前回の図2に示した通りですが、実際には、データの整合性に関する追加の処理があります。RDMAでは、メモリー上のデータを読み書きする際の排他制御が行われないため、サーバー上でデータの書き込みが行われている途中にクライアントが同じメモリー領域のデータを読み出した場合、書き込み途中の不完全なデータが読み出される可能性があります。この問題を回避するため、データ領域(Data Region)には、データの実体(キー・バリューペア)に加えて、これらから計算したチェックサムが格納されています。データを読み出したクライアントは、このチェックサムを用いて、読み出したデータが書き込み途中の不完全なものでないことを確認します。チェックサムが一致しない場合は、データが破損しているものと判断して、データの読み出しをリトライします。
また、前回の図1から分かるように、クライアントがデータを読み出す際は、キーの値そのものではなく、キーのハッシュ値を用いてサーバーからデータを取得します。そのため、確率的には非常に低いものの、同一のハッシュ値を持った異なるキーのデータが読み出される場合があり得ます。そのため、クライアントは、データの実体を読み出した後、そこに含まれるキーの値が読み出したいデータのキーに一致していることを確認します。これが一致しない場合は、該当のデータは存在しない(キャッシュミス)ということになります。
なお、ハッシュ値が同一のデータが複数書き込まれた場合は、先に存在するデータは削除されて、後から書き込まれたデータが保存されます。CliqueMapはキャッシュシステムなので、保存データの永続性は保証されない点に注意してください。また、データの書き込みは、RDMAではなく、通常のRPC(APIコール)を通じて行われるため、同時書き込みの排他制御はサーバー上のプロセスによって適切に行われます。
CliqueMapではシステムの可用性を担保するために、同一のデータ(キー・バリューペア)は3箇所のサーバーに複製されます。複製処理はクライアントによって行われるようになっており、クライアントはデータを書き込む際に、明示的に3箇所のサーバーに書き込み処理のリクエストを送ります。別々のクライアントが同一のキーに対して異なるデータを書き込んだ場合は、クライアントが付与するバージョン番号により排他制御が行われます。具体的には、クライアントはタイムスタンプを用いたバージョン番号を付与して書き込みデータを送信して、サーバー側ではバージョン番号が大きいデータを優先的に受け付けます。受け取ったバージョン番号がすでに保存されているデータのバージョン番号より小さい場合は、この書き込みリクエストは破棄されるので、時間的に後から書き込み依頼が発生したデータが必ずサーバー上に残ります。
一方、クライアントがデータを読み出す際は、2箇所から読み出したインデックス情報が一致することを確認します。具体的には、3箇所のサーバーにインデックス情報(バケット)の取得リクエストを送信して、最初に応答が得られたサーバーからデータの実体を取得します。そして、別のサーバーからインデックス情報の応答が得られたタイミングで、最初に取得したインデックスと内容が一致することを確認します(図1)。これらが一致しなかった場合は、該当データの取得に失敗した(キャッシュミスが発生した)ものとして取り扱います。これにより、3箇所のサーバーに格納されたデータが異なるという不整合が発生しても、アクセスするサーバーによって得られるデータが異なるという状況を回避することができます。
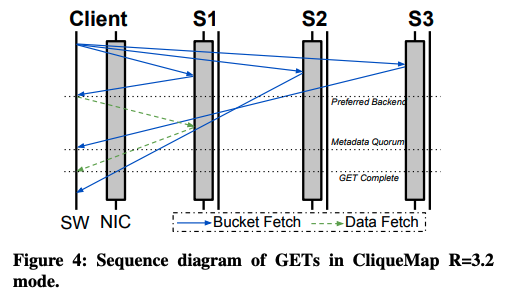
サーバー間でデータの不整合が発生する原因としては、クライアントがデータを書き込む際に一部のサーバーのみで書き込みに失敗する、あるいは、障害で一部のサーバーが停止するといった原因が考えられます。各サーバーは、自身が保持するデータに対して、他の2箇所のサーバーが同じデータを保持していることを定期的に確認します。不整合を発見した際は、新しいバージョン番号を付与したデータを配布して、これを修復する処理を行います。
また、クライアントが図1の処理を実施している途中で、他のクライアントが同じキーのデータを変更する可能性があります。タイミングによっては、書き込み途中の不完全なデータを読み出す可能性がありますが、この場合は前述のチェックサムの確認に失敗して、リトライが行われます。
前回の記事で説明した様に、CliqueMapはデータキャッシュ専用に設計されており、記憶領域が不足した場合などには、既存のエントリーは自動で削除されるという特徴があります。この際、長期間読み出されていないエントリーを優先的に削除するという処理を行いますが、データの読み出しはRDMAによって行われるため、サーバー上のプロセスはどのエントリーが読み出されたかを知ることができません。この問題に対応するため、CliqueMapのクライアントは、どのデータを読み出したかという情報を通常のRPC(APIコール)でサーバー上のプロセスに通知します。読み出しごとに通知するのではなく、定期的にバッチで通知することによりパフォーマンスへの影響を抑えます。このように、すべての通信処理をRDMAで行うのでなく、RDMAによるデータの読み出しと通常のRPC(APIコール)によるサーバー上のプロセスとの連携を組み合わせたハイブリッドな設計がCliqueMapの特徴と言えるでしょう。
今回は、2021年に公開された論文「CliqueMap: Productionizing an RMA-Based Distributed Caching System」を元にして、Google社内で使用されているインメモリ分散キャッシュシステム「CliqueMap」について、システムの可用性とデータの整合性を担保する仕組みを解説しました。次回は、プロダクション環境でのCliqueMapの稼働状況を示すデータを紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































