
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2022年に公開された論文「CacheSack: Admission Optimization for Datacenter Flash Caches」を元にして、Googleのデータセンターで使用されている、フラッシュディスクによるファイルキャッシュシステムを紹介します。この論文では、数理最適化を用いてキャッシングポリシーを選択するアルゴリズムが紹介されており、ITシステムにおける数理最適化の応用例としても興味深い内容です。今回は、最適化の対象となるファイルキャッシュシステムのアーキテクチャーを説明します。
Googleのデータセンターでは、Colossusと呼ばれる分散ファイルシステムが標準的に利用されています。冒頭の論文によると、近年のColossusの利用状況において、読み込み性能を保つために必要なコストの増大が課題となっていたそうです。技術の発達によりハードディスク1本あたりの保存容量が急速に増加する一方、IO性能、とりわけ、読み込み速度はそれに見合うだけの性能の向上が得られていません。高速にデータを読み出すには、複数のディスクにデータを分散保存して、読み込みの並列度を上げるという工夫が必要になります。その結果として、ハードディスクの空き容量に関わらず、読み込み速度を確保するために多数のハードディスクが必要になるという状況が生まれます。
この問題を改善するために導入されたのが、「Colossus Flash Cache」と呼ばれる、SSDを利用したファイルキャッシュのシステムです。Colossusのユーザーは、必要に応じて、SSDをバックエンドとするフラッシュサーバー上のキャッシュ領域を確保しておき、読み込みキャッシュとして利用することができます。この仕組みは、Colossusのクライアントに組み込まれており、キャッシュを有効化したファイルにアクセスすると、図1の処理が自動的に行われます。
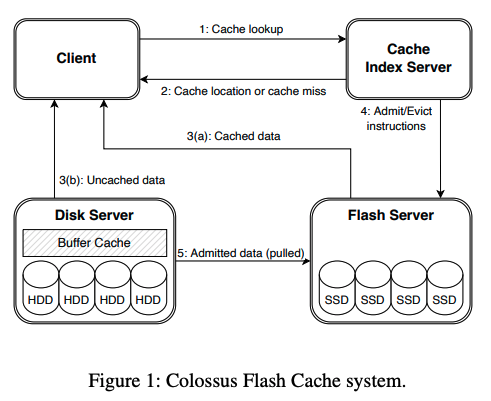
図1 Colossus Flash Cacheのアーキテクチャー(論文より抜粋)
処理の流れは次のようになります。クライアントは、まずはじめに、インデックスサーバーにアクセスして、読み込み対象のファイルがキャッシュされているかを確認します。キャッシュヒット、すなわち、すでにキャッシュされている場合は、インデックスサーバーから取得した情報を元にして、フラッシュサーバーのキャッシュ領域からデータを読み出します。キャッシュミス、すなわち、キャッシュされていない場合は、クライアントは、通常通りにColossusからデータを読み出しますが、この時、インデックスサーバーは、該当ファイルをキャッシュするかどうかの判断を行い、キャッシュが許可されると、フラッシュサーバーは、該当のファイルをColossusからキャッシュ領域にコピーします。このようにして、頻繁に読み込みが行われるファイルについては、SSDにキャッシュを保存することで、ハードディスクの本数を増やさずに必要な読み込み速度を保つ事ができるというわけです。
前述のファイルキャッシュシステムは、仕組みとしては比較的シンプルですが、実装においては、SSDに固有の課題に対処する必要があります。その1つが、ライトアンプリフィケーションの抑制です。SSDに用いられるフラッシュメモリは、数10KBから数100KBのブロック単位での書き換えが必要になります。したがって、新しいファイルを書き込む場合、書き込み対象のブロックを消去した後に、あらためてブロック全体を書き込む必要があります。このため、小さなファイルの書き込みや消去が多いと、必要以上の書き込み処理が発生して、フラッシュメモリの寿命を縮めてしまいます。これが一般にライトアンプリフィケーションと呼ばれる問題です。一方、一般的なファイルキャッシュでは、キャッシュ容量が一杯になると、LRU(Least Recently Used)と呼ばれるアルゴリズムにより、アクセス頻度が低いファイルを選択してキャッシュから削除します。結果として、複数ブロックに散らばったファイルを削除することになり、前述のライトアンプリフィケーションが発生します。
この問題を回避するシンプルな方法としては、LRUではなく、FIFO(First In First Out)のアルゴリズムを用いるという方法があります。図2のように、キャッシュを管理するキューを用意しておき、新しくキャッシュするデータは同一のブロックにまとめて書き込み、キューの先頭にその情報を追加します。そして、キューの末尾に到達したブロックのデータをひとまとめに削除対象とすれば、キャッシュからのデータ削除は該当ブロックの消去のみで完了します。ただし、この場合、アクセス頻度が高いファイルもキャッシュから削除されるため、キャッシュの利用効率が下がります。
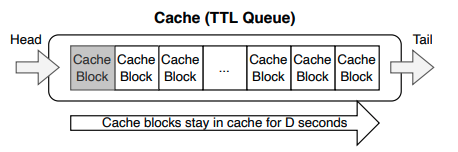
図2 FIFOキューによるキャッシュの管理(論文より抜粋)
そこで、Colossus Flash Cacheでは、FIFOキューによるキャッシュの管理を行いながら、擬似的にLRUのアルゴリズムを再現するという方法を用います。具体的には、FIFOで削除対象となったファイルの中で、アクスセス頻度が高い上位28%のファイルをその場で再キャッシュして、FIFOキューの先頭に戻します。これにより、FIFOキューを用いながら、アクセス頻度の高いファイルをキャッシュ上に残すLRUのアルゴリズムを擬似的に再現します。28%という値は、ファイルの再書き込みに伴うライトアンプリフィケーションのコストとキャッシュの利用効率のバランスを取るようにシミュレーションデータを用いて決定したという事です。
そして、もう1つの課題がキャッシュ対象のファイルを選択するポリシーの設定です。仮に、キャッシュ領域の容量が無制限にあるとすれば、すべてのファイルをキャッシュ対象にするのが最も効率的と言えます。しかしながら、キャッシュシステムに使用するSSDのコストを考えると、それは現実的ではありません。利用可能なSSDの容量の範囲内において、ハードディスクへのアクセス数をできるだけ少なくするように、キャッシュ対象のファイルを選択するアルゴリズムが必要になります。この部分が冒頭の論文のメインテーマとなります。
今回は、2022年に公開された論文「CacheSack: Admission Optimization for Datacenter Flash Caches」を元にして、Googleのデータセンターで使用されている、フラッシュディスクによるファイルキャッシュシステムについて、アーキテクチャーの概要を説明しました。次回は、キャッシュ対象のファイルを選択するアルゴリズムについて、解説を進めていきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































