これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2023年に公開された論文「Firestore: The NoSQL Serverless Database for the Application Developer」に基づいて、Google Cloudで提供されるNoSQLデータベースサービス「Firestore」のアーキテクチャーを解説していきます。今回は、内部アーキテクチャーを理解する前提となる、Firestoreのデータモデルについて説明した上で、Firestoreのアーキテクチャーの全体像を紹介します。
Firestoreでは、「ドキュメント」の単位でデータを保存します。1つのドキュメントは、「restaurants/one/ratings/2」のように「/」区切りのドキュメントパスで指定されて、最後の「/」より前の部分は、複数のドキュメントをまとめる「コレクション」として機能します。つまり、「restaurants/one/ratings/2」は、コレクション「restaurants/one/ratings」に属する「2」という名前のドキュメントになります。この際、「restaurants/one」など、親パスをドキュメントパスとするドキュメントを持つこともできます。この場合、「restaurants/one」はドキュメントを指し示すと同時に、そのドキュメントを親とするサブコレクションを表すことになります。イメージとしては、図1のように、はじめにコレクションのツリーが定義されており、ツリーの各ノードに、同じドキュメントパスで指定されるドキュメントが用意されると考えるとよいでしょう。この際、すべてのノードが対応するドキュメントを持つ必要はありません。
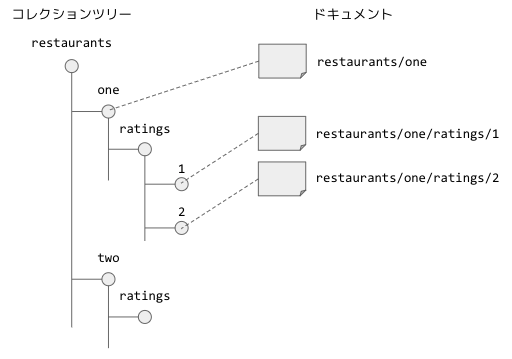
図1 コレクションツリーとドキュメントの関係
それぞれのドキュメントの内容は、キー・バリューペアの集合(map型データ)になります。バリューとして、再度、map型やlist型を用いることで、階層的なデータ構造を持つこともできます。図2は、ドキュメント「restaurants/one/ratings/2」の内容の例になります。

図2 ドキュメントに格納されたデータの例(論文より抜粋)
ここでは、キー「details」に対応するバリューとして、map型のデータが格納されていますが、このような階層構造は、コレクションツリーを用いて表現することもできます。具体的には、detailsの内容をドキュメント「restaurants/one/ratings/2」に保存するのではなく、「/restaurants/one/ratings/2/details」というドキュメントを別途用意して、そちらに保存します。これら2つの方法は、どの範囲のデータをひとまとめに読み書きしたいかで使い分けることになります。Firestoreにおけるデータの読み書きはドキュメント単位で行われるので、図2のようにdetailsをドキュメント「restaurants/one/ratings/2」に含めた場合、このドキュメントを取得すると、detailsの内容も必ず含まれることになります。
また、Firestoreでは、格納したデータに対する検索は、すべて、インデックスを用いて行われます。キー・バリューペアのそれぞれのキーについて、検索用の1次インデックスが自動的に用意される他に、複数のキーを組み合わせた2次インデックスを定義することができます。逆に言うと、複数のキーを組み合わせた検索を実行するには、適切な2次インデックスを必ず定義しておく必要があります。
さらに、それぞれのドキュメントには暗黙のタイムスタンプが付与されており、特定の時刻における(その時点での強い整合性を持った)スナップショットから検索することができます。特にリアルタイムクエリーを実行した場合は、データの更新に応じて、複数の時刻のスナップショットにおける検索結果が順次得られることになります。図3の例では、t=10, 13, 19の3種類の時刻のデータが得られています。{・・・} 内のデータが1つのドキュメントに対応しており、末尾の@で表された値は、そのドキュメントのタイムスタンプです。t=10, 13, 19のそれぞれの時刻における最新のタイムスタンプのドキュメントが返却されることになります。

図3 リアルタイムクエリーに対する応答の例(論文より抜粋)
前回の記事で説明したように、Firestoreのデータを格納するバックエンドは、分散データベースのSpannerです。そのアーキテクチャーの全体像は図4のようになります。フロントエンド、バックエンド、メタデータキャッシュ、リアルタイムキャッシュなどのコンポーネントは、すべて複数のタスクが並列稼働する分散型のシステムになっています。
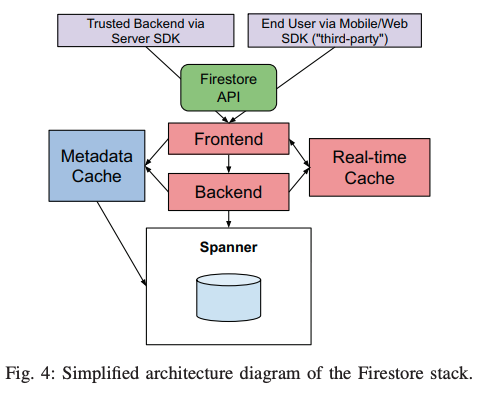
図4 Firestoreのアーキテクチャーの全体像(論文より抜粋)
この一連のシステムは複数のリージョンにデプロイされており、Firestoreのデータベースを作成する際に、使用するリージョンを選択することができます。また、Firestoreは、モバイルデバイスで稼働するクライアントアプリケーションからのアクセスにも対応していますが、これらからのAPIリクエストは、Googleのグローバルネットワークによって該当リージョンのフロントエンドにルーティングされます。その後、バックエンドの処理を経て、Spannerにデータが格納されます。この際、Spanner上には、EntitiesテーブルとIndexEntriesテーブルの2つのテーブルが用意されており、これらのテーブルに、それぞれ、実データとインデックス情報が保存されます。実データについては、1つのドキュメントは、Entitiesテーブルの1つの行(レコード)として保存されます。ドキュメントに含まれるキー・バリューペア全体をProtocolBufferにシリアライズして、1つの列に保存するというシンプルな構造になります。
ドキュメントの内容をシリアライズすると、検索処理が困難になると考えるかも知れませんが、前述のように、Firestoreの検索処理は、すべてインデックスを用いて行われるので問題ありません。IndexEntriesテーブルに保存されたインデックス情報から、検索条件にマッチするドキュメントを特定した後に、該当のドキュメントをEntitiesテーブルから取り出します。
2023年に公開された論文「Firestore: The NoSQL Serverless Database for the Application Developer」に基づいて、Google Cloudで提供されるNoSQLデータベースサービス「Firestore」のデータモデルとアーキテクチャーの全体像を紹介しました。次回は、データの検索・書き込みの詳細について説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































