
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2022年に公開された論文「Understanding Host Interconnect Congestion」を紹介していきます。この論文では、サーバー内部のネットワーク処理速度の分析を行っており、ネットワーク機器の性能が向上する中で、サーバー内部における、NIC(ネットワークインターフェースカード)とメモリー間のデータ転送が新たなボトルネックとなる可能性を指摘しています。
サーバー間のネットワーク通信では、サーバーのメモリー上のデータは、NICを介してネットワークに送出された後、複数のネットワークスイッチを経由して通信先のサーバーに到着し、サーバーのメモリーに書き込まれます。この時の通信速度は、サーバー間にあるネットワーク機器の性能によって決まるものであり、ネットワーク機器の性能向上によりサーバー間のネットワーク通信速度が向上するというのが一般的な考え方です。
しかしながら、ネットワーク機器の通信速度がいくら早くても、サーバー内部における処理速度、たとえば、メモリーとNICの間でデータをやりとりする速度が十分に早くなければ、そこが通信処理のボトルネックになる可能性があります。近年のネットワーク機器の性能向上に伴って、実際にそのような現象が発生しているというのがこの論文の主張です。図1は、Googleのデータセンターで稼働するサーバーから取得した実環境のデータで、横軸がサーバー間のネットワーク帯域の使用率で、縦軸は(パケットを受け取る側の)サーバー内部におけるパケットドロップの発生率を表します。これを見ると、ネットワーク帯域にはまだ余裕があるにも関わらず、サーバー内部でパケットドロップが発生していることがわかります。この論文では、このようなサーバー内部でのパケットドロップの発生原因について詳細な調査を行っています。
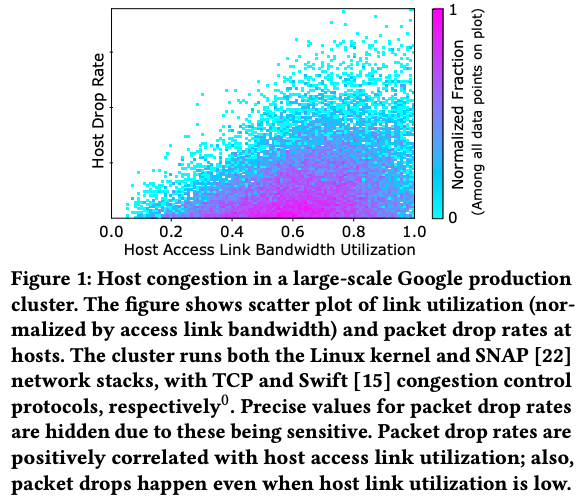
図1 サーバー内部でのパケットドロップの発生を示すデータ(論文より抜粋)
図2は、外部からネットワークパケットを受け取ったサーバーが、そのデータをどのように処理するかを示した図です。まずは、この図に従って、サーバー内部でのパケット処理の流れを確認します。
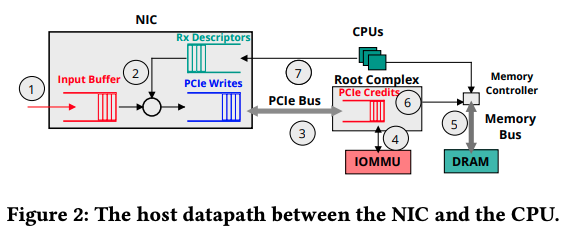
図2 サーバー内部でのパケット転送処理(論文より抜粋)
ネットワークパケットとして受け取ったデータをメモリーに書き込む処理は、主に、PCIeカード上のRoot Complexによって制御されます。この際、CPUによるメモリーアクセスとの競合を防ぐために、Root Complexは、メモリーコントローラーから「PCIe Credits」と呼ばれるアクセスチケットを取得する必要があります。PCIe Creditsが不足した場合、新たなPCIe Creditsが取得できるまで、Root Complexはメモリーへの書き込み処理を中断します。
この前提を踏まえて、図2に従って処理の流れを説明すると、次のようになります。
(1) NICが受け取ったパケットは、まずは、1~2MB程度のサイズのバッファに保存されます。
(2) NICは、パケットを保存するメモリーの仮想アドレスをキューから取得します。(キューの内容は、NICのドライバーによって定期的に追加されます。)
(3) NICは、データ転送リクエストをPCIeカードのRoot Complexに依頼します。このリクエストは、Root Complex上のキューに追加されます。Root Complexは、「PCIe Credits」を取得した後、キューに追加されたリクエストを処理します。
(4) Root Complexは、IOMMUを用いて、書き込み先の仮想アドレスを物理アドレスに変換します。
(5) Root Complexは、メモリーコントローラーを通じて、NIC上にバッファされたデータをメモリーに転送します。
(6) Root Complexは、PCIe Creditsをメモリーコントローラーに返却します。
(7) メモリー上にデータが書き込まれたことがCPUに通知されます。
上記の一連の処理よりも速いスピードでNICにパケットが到達すると、NIC上のバッファがあふれてパケットドロップが発生します。このようなパケットドロップが発生する原因を探るには、上記の処理の中で、特に時間を要するボトルネックを特定する必要があります。
ちなみに、PCIe 3.0の場合、PCIeカード上のデータバスの転送速度は128Gbpsで、100GbpsのNICをサーバーに接続している場合、NICがデータを受け取る速度よりも少し速い程度です。これは、上記の(5)の処理速度にあたるもので、仮にこの部分がもっと高速であれば、他の部分で発生した遅延をここで吸収できる可能性もありますが、そういうわけには行きません。上記の(5)以外の部分で遅延が発生すると、(1)のバッファがあふれて、パケットドロップが発生します。この論文では、IOMMUによる仮想アドレスと物理アドレスの変換にかかる時間((4)の部分の処理)、そして、メモリーコントローラーによるメモリーへのデータ書き込み処理がCPUによるメモリーアクセスと競合することで発生する遅延((3)の部分でPCIe Creditsの取得待ちが発生する時間)を主な原因と想定しています。
ここで、IOMMUによる処理がボトルネックになる理由を簡単に説明しておきます。まず、複数のプロセスが並列に稼働するマルチプロセス対応のOSでは、それぞれのプロセスにメモリーを割り当てる際に、仮想アドレスの仕組みを利用します。OS上で稼働するそれぞれのプロセスは、OSから割り当てられたメモリーの物理アドレスは分かりません。事前に決められた特定範囲の仮想アドレスを用いてメモリーにアクセスすると、OSのカーネルが対応する物理アドレスに変換します。プロセスごとの仮想アドレスと物理アドレスの対応関係は、メモリー上の変換テーブルに保存されています。この変換処理をハードウェアで高速に実行する機能として、メモリ管理ユニット(MMU)が搭載されています。これと同様の機能をNICなどのデバイスに対して提供するのがIOMMUです(図3)。
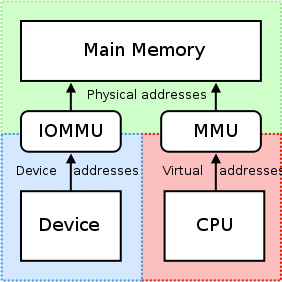
図3 MMUとIOMMUの役割(Wikipediaより転載)
仮想アドレスの仕組みは、プロセスごとにメモリー空間を分けることですので、デバイスから受け取ったデータの管理をOSカーネルが行う場合は、このような仮想アドレスの仕組みを使う必要は無く、IOMMUは不要です。一方、サーバー仮想化を使用する場合、サーバー上で複数のゲストOSのカーネル(ゲストカーネル)が稼働します。そのため、仮想マシンに外部デバイスを接続する際は、ゲストカーネルごとにI/O処理に使用するメモリー空間を分ける必要があります。このため、IOMMUを用いて、デバイスごとに(接続先の仮想マシンに応じた)仮想アドレスを割り当てることになります。
MMU、および、IOMMUは、過去に変換した結果を保存する、IOTLBと呼ばれるキャッシュ領域を持っており、キャッシュにヒットした場合は、メモリー上の変換テーブルを読まずに数ナノ秒程度で結果を返すことができます。一方、キャッシュミスの場合は、メモリー上の変換テーブルを読み行くため、数百ナノ秒から、1マイクロ秒程度の時間がかかります。従って、キャッシュミスが頻繁に発生すると、この部分の処理時間がボトルネックになる可能性があります。
そして、もう一つのボトルネックとして想定されるのが、メモリーコントローラーによるメモリーへのデータ書き込み処理と、CPUによるメモリーアクセスの競合です。先に触れたように、PCIeカード上のデータバスは128Gbpsの帯域を持っていますが、これは、NICからメモリーへのデータ転送だけに使われるものではありません。CPUがメモリーにアクセスする際もこのデータバスを使用するので、サーバー上で大量のメモリーアクセスを行うプロセスが稼働している場合、NICが利用できる帯域は減少して、これがボトルネックになります。
これらは、あくまでも理論上の想定ですが、冒頭の論文では、それぞれについて、詳細なベンチマークを行って、これらの想定が正しいことを検証しています。
2022年に公開された論文「Understanding Host Interconnect Congestion」に基づいて、サーバー上でのネットワークパケット転送処理の仕組み、そして、これがネットワーク通信のボトルネックを発生させている可能性を説明しました。次回は、これらを検証したベンチマークの結果を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































