これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2010年に公開された論文「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」に基づいて、Google社内で使用されている分散トレーシングツールDapperを紹介していきます。今回は、Dapperの性能に関する情報と、Dapperを利用したデータ分析ツールを紹介します。
前回の記事で説明した様に、トレーシングツールの導入に伴う性能上のオーバーヘッドを低減することは、Dapperのデザインゴールの1つです。Dapperによるログ収集の機能は、社内標準のRPCフレームワークに組み込まれていますが、軽量で安定した機能を実現するためにコードの実装はシンプルに保たれており、追加されたコードは、Annotation機能を除くと、C++で1000行以下、Javaで800行以下ということです。Annotation機能による追加は、500行程度です。
そして実際のコードの平均実行時間は、2.2GHzのx86サーバーで計測したところ、ツリーの起点となるRoot spanで204ナノ秒、その他のSpanで176ナノ秒、そして、Annotationを追加した場合のオーバーヘッドは70ナノ秒ということです。これをすべてのリクエスト呼び出しに適用した場合、Web検索のように高い性能が要求されるシステムでは、そのオーバーヘッドは無視できない可能性があります。そのため、ログを収集するツリーをランダムにサンプリングすることで、オーバーヘッドを低減しています。
図1は、サンプリングの頻度によるオーバーヘッドの変化を計測したもので、頻度が1/16であれば、計測されるオーバーヘッドは、測定誤差の範囲内に収まっています。また、実際のシステムでは、類似のトレースが大量に生成されるため、分散処理のボトルネックを発見するというトレーシングツールの目的を考えると、さらに頻度を下げることも可能です。これらを総合的に考慮して、現在は、1/1024の頻度でのサンプリングを行っています。
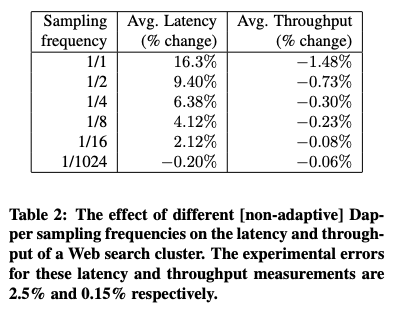
図1 サンプリングの頻度によるオーバーヘッドの変化(論文より抜粋)
このサンプリングにより、アプリケーションがログデータを出力する部分のオーバーヘッドは十分に低減できましたが、収集したデータをBigtableに書き込む部分は、別途、考慮が必要です。上述のサンプリングを行った場合でも、1日あたり1テラバイト以上のログデータが生成されるため、Bigtableに対する書き込みの負荷やデータを長期保存するコストが無視できない可能性があります。そのため、Dapperでは、収集したログデータをBigtableに書き込む部分でも、必要に応じて追加のサンプリングができるようになっています。トレースのツリーごとに割り当てられるTrace IDから0.0~1.0の範囲のハッシュ値を生成して、これが一定の値以下のデータのみをBigtableに保存します。
Bigtableに保存されたデータは、DAPI(Depot API)と呼ばれる専用のAPIから取得できます。トレースIDを指定して特定のデータを取得する他に、MapReduceを用いて、指定期間のデータを集計処理することもできます。また、アプリケーション開発者がトレースデータを解析する場合、特定のサービスに対するデータ、あるいは、その中でも特定のサーバーからの出力データが必要になります。そこで、Bigtableのテーブルに対して、「サービス名、ホスト名、タイムスタンプ」の3つの条件で検索するための複合インデックスが用意されています。
そして、DAPIを用いたさまざまなデータ分析ツールが作られており、アプリケーション開発者やSREは、これらを組み合わせて分析を行います。論文内では、典型例として、次の流れが紹介されています。それぞれのステップ番号は、図2に示された番号に対応します。
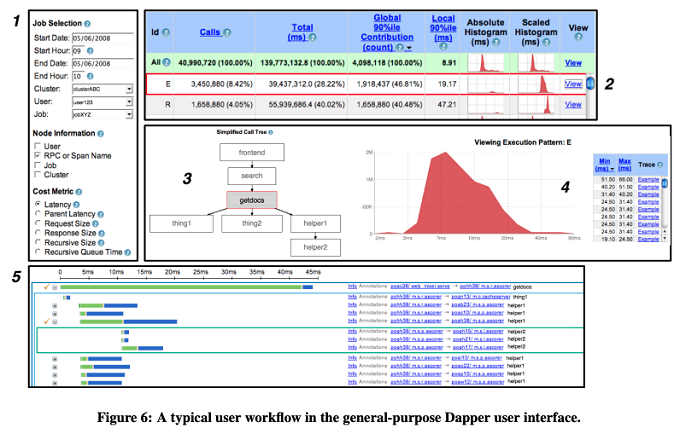
図2 DAPIを用いたデータ分析ツールの例(論文より抜粋)
これらのツールは、Bigtableに保存されたデータを利用しているので、リアルタイムでのトレースデータが見れるわけではありません。前回の記事で説明したように、サービスが生成したログは、Bittableに保存されるまでに一定の処理時間が必要となります。そのため、障害対応など、リアルタイムでのログの確認が必要な場合は、各サーバーのローカルに保存されたデータを直接参照する機能も用意されています。
今回は、2010年に公開された論文「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」に基づいて、Google社内で使用されている分散トレーシングツールDapperについて、性能に関する情報と、Dapperを利用したデータ分析ツールを紹介しました。次回は、Google社内での実際の利用例を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































