
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「Resolving Code Review Comments with Machine Learning」に基づいて、大規模言語モデルをコードレビュー支援に適用したGoogle社内の事例を紹介します。大規模言語モデルをソフトウェア開発に利用するさまざまなユースケースが議論されていますが、Google社内では、コードレビューのプロセスに大規模言語モデルによる支援を組み込んでいることがこの論文で報告されています。今回は、このユースケースの概要を紹介します。
はじめに、Google社内でのコードレビューのプロセスを簡単に説明しておきます。まず、第20回の
記事で紹介したように、Google社内では、すべてのプロジェクトのソースコードが単一のリポジトリにまとめて保存されています。それぞれの開発者は、自身の開発用ワークステーションにこのリポジトリのクローン(論理コピー)を作成して、そこでコードの追加・変更作業を行います。その後、特定の目的のために追加・変更したファイル一式をまとめたCL(Change List)を作成して、これに対してコードレビューを実施します。CLは、GitHubにおけるPull Requestに相当するものと考えるとよいでしょう。
そして、第42回の記事で紹介したように、コードレビューの際はオープンソースのレビューツールであるGerritに類似のツール(Critique)を使用します。図1のように、レビュアーは特定の行に対してコメントをつけて、開発者はそのコメントを元にコードを修正するというプロセスを繰り返します。すべてのコメントへの対応が終わってレビューが完了すると、レビュアーは「LGTM(Looks good to me)」をCLに付与します。必要な数のレビュアーからのLGTMが得られたCLは、リポジトリのメインブランチにマージされます。レビュー中に行われたコードの修正は、その都度、スナップショットが取得されるので、Critiqueの画面上で修正の履歴を確認することもできます。
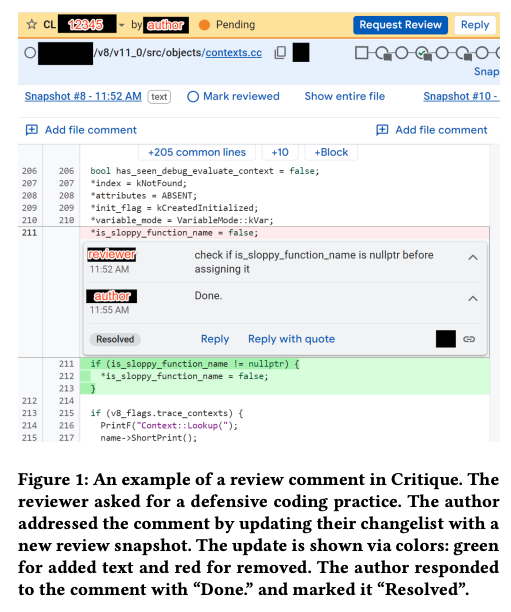
図1 Critiqueによるレビューコメントのやりとりの例(論文より抜粋)
前述のようにレビュープロセスの中では、レビュアーのコメントに応じたコードの修正が求められるわけですが、この部分を大規模言語モデルで支援するというのが基本的なアイデアになります。具体的には、レビュアーのコメントが要求する内容を実現するコードの修正案を大規模言語モデルで自動生成します。図2のように、レビュアーのコメントに対して「Show ML-edit」というボタンが表示されて、これをクリックすると自動生成されたコードの修正案が表示されます。開発者が修正案の内容を確認して、問題ないと判断した場合は、「Apply」をクリックすれば、それを適用することができます。
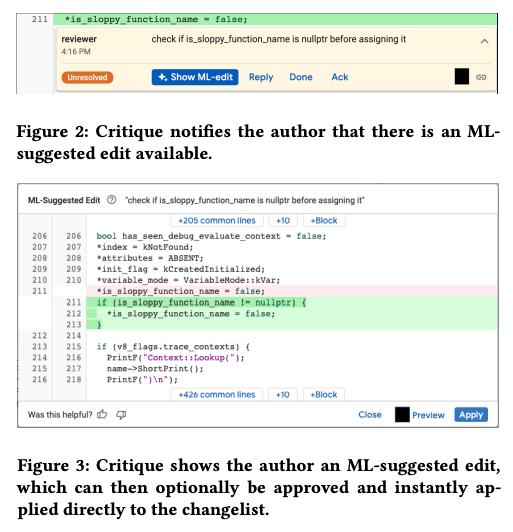
図2 「Show ML-edit」をクリックしてコードの修正案を表示する様子(論文より抜粋)
また、図2の下部には「thumbs-up/thumbs-down」ボタンが表示されています。開発者は、これらのボタンを押して、修正案に対する評価をフィードバックすることができます。開発者が提案された内容を適用しなかった場合でも、提案内容からよりよい修正案を思いつくなどした場合は、「thumbs-up」をクリックすることでポジティブな評価を返す事ができます。次回以降に説明するように、このフィードバック情報は、大規模言語モデルの評価と改善に利用されます。
コードの修正案を生成する大規模言語モデルは、Googleが開発してオープンソースとして公開されているT5Xがベースになります。入力テキストに対して、期待する出力テキストが得られるようにこのモデルを学習するわけですが、ここでは、ソフトウェアの開発に関連した複数のタスクの学習データを使用します。具体的には、次のような内容を含みます。
機械学習モデルは、関連する複数のタスクを同時に学習することで全体的な性能が向上することが知られており、一般に、マルチタスク学習と呼ばれるテクニックになります。上記のマルチタスク学習は、Googleの研究者が開発したDIDACTと呼ばれるフレームワークで行われました。DIDACTの詳細については、次のブログ記事が参考になります。
・Large sequence models for software development activities
このマルチタスク学習に使用する学習データは、Google社内のソフトウェア開発で蓄積された履歴データが元になります。特にレビューコメントから修正案を予測する部分は、図3のようなフォーマットの学習データを使用します。上部の「Input Representation」が入力テキストで、下部の「Example Edit Representation」が期待される出力テキストになります。レビュアーのコメントはコードの特定部分に紐づけられているので、該当部分の直前にコメントとして埋め込まれます。また、入力テキストの先頭部分には「このレビューコメントを修正してください」という指示が追加されています。この際、モデルに入力可能なトークン数の範囲におさまるように、コメント部分を含む一定範囲のコードのみを使用します。対応する出力テキストは、コードの削除部分と追加部分を示したpatch形式で与えられます。

図3 大規模言語モデルの学習に使用するトレーニングデータの例(論文より抜粋)
今回は、2024年に公開された論文「Resolving Code Review Comments with Machine Learning」に基づいて、大規模言語モデルをコードレビュー支援に適用したGoogle社内の事例について、ユースケースの概要を紹介しました。素朴に考えると、本文で説明した学習済みのモデルをレビューツールに組み込めばすぐにでも利用開始できそうですが、実際にはそれほど簡単には行きません。次回は、モデルの精度向上に向けたチューニングについて解説します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































