
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「Load is not what you should balance: Introducing Prequal」に基づいて、GoogleのコンテナインフラであるBorg環境の特性に対応した、新しいロードバランシングの仕組みである「Prequal」を紹介していきます。今回は、Borg環境における、従来のロードバランサーの課題を説明します。
従来のロードバランサーは、サーバーのCPU使用率に基づいてリクエストの転送先を決定しました。CPU使用率が低いサーバーを選択してリクエストを転送するという方式です。しかしながら、これはBorg環境では最適と言える方式ではありませんでした。この理由を説明するために、Borgの実行環境について簡単に復習しておきます。
BorgはGoogleのデータセンターで用いられているコンテナ管理システムで、オープンソースのKubernetesに類似した機能を提供します。Kubernetesの環境では、「Deployment」リソースを定義すると、そこで指定されたコンテナイメージを用いて、同一の機能を提供する複数のPodが起動します。これに対応して、Borgの環境では、マスターサーバーに「Job」の作成要求を出すと、そこで指定されたアプリケーションバイナリーから(同一の機能を提供する)複数のコンテナが「Task」として起動します。Kubernetesの環境では、それぞれのPodが利用するCPU時間とメモリー容量について上限を設定することができますが、Borgの環境でも同様の設定が行われます。
この際、CPU使用率については、割り当てを超えた使用を許可するオーバーコミットの設定がなされます。つまり、同一のサーバーで稼働する他のコンテナが割り当て分のCPU時間を使い切っておらず、サーバー全体としてCPUの使用量に余裕があれば、一部のコンテナが割り当てを超えてCPUを使用することができます。図1は、割り当てを超えてCPUを使用する様子を示す実際のデータになります。
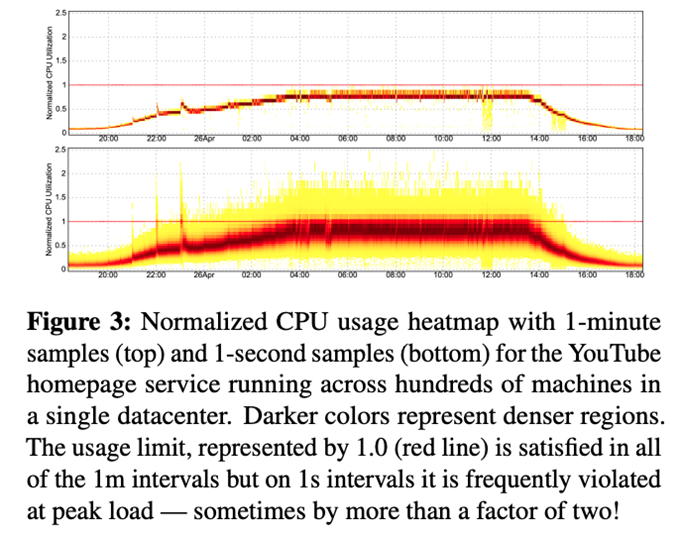
図1 YouTubeのトップページを提供するコンテナのCPU使用率(論文より抜粋)
これは、YouTubeのトップページを表示するタスクが稼働するコンテナ群の例ですが、上のグラフは、1分ごとの平均使用率、そして、下のグラフは1秒ごとの平均使用率を表します。縦軸の値は、Borgによって割り当てられた使用量が1になるように正規化されています。数百のコンテナのデータを1つのグラフにまとめたもので、色の濃い部分はその値を取るコンテナの数が多い事を表します。1分ごとの平均使用率をみると、割り当て量を超える部分はありませんが、1秒ごとの平均使用率をみると、ピーク時間帯において、一定割合のコンテナが定常的に割り当て量を超えてCPUを使用しています。つまり、CPU使用量において、秒単位のスパイクが定常的に発生していることがわかります。
それでは、この状況がロードバランサーの課題とどのように関係するのでしょうか? 先ほど説明したように、従来のロードバランサーは、CPU使用率が低いコンテナを優先的に選択します。このためには、コンテナごとのCPU使用率をリアルタイムに測定する必要がありますが、測定処理そのものがコンテナに負荷を与えないように注意する必要があります。そのため、データ収集は通常1分以上の単位で行われます。
ここで、先ほどの図1の状況が問題となります。1分単位のデータ収集では、秒単位のスパイクを捉えることができません。図1の下のグラフをみると、一定割合のコンテナで定常的にスパイクが発生しており、ロードバランサーがCPU使用量に余裕があると判断してコンテナにリクエストを転送したとしても、該当リクエストの処理中に一定の確率でそのコンテナ上でスパイクが発生します。この際、該当コンテナが稼働するサーバーのCPU使用量に余裕があれば、オーバーコミットが機能するので問題ありませんが、そうでなければ、このリクエストはCPUリソースの不足によって、処理に遅延が発生します。
Borgの環境では、さまざまなサービスのタスクが同一のサーバーに混在していますので、該当サーバーのCPU使用率に余裕があるかどうかは、まったく無関係のサービスの稼働状況に依存しており、この部分は該当サービスの担当チーム(この例の場合は、YouTubeチーム)がコントロールすることはできません。図2は、この状況を示した図で、「antagonist A, B, ...」は他のサービスのタスクを表します。
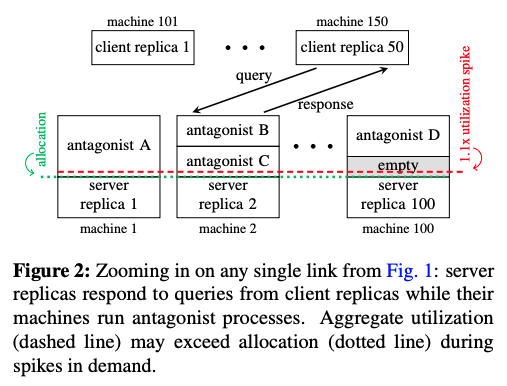
図2 CPU使用量のスパイクに対応できる場合とそうでない場合(論文より抜粋)
図のmachine 100は、サーバーのCPU使用量に空きがあるので、replica 100は事前に割り当てられたCPU使用量(緑のライン)を超えてスパイクを処理することができます。一方、machine 1、machine 2はサーバーのCPU使用量に空きがなく、replica 1、replica 2にスパイクが発生すると、CPUの待ち時間が発生して、処理遅延が生じることになります。
つまり、CPUのオーバーコミットを前提とした環境においては、従来のロードバランサーでは、コントロール不能な処理遅延が必ず発生します。そして、YouTubeのトップページのように膨大なユーザーがアクセスするサービスでは、ごく一部のタスクの処理が遅延するだけでも、多数のユーザーに影響を与えることになります。このような処理時間のロングテールをうまく扱う仕組みが必要となります。
冒頭の論文では、この問題を解決する仕組みとして、CPU使用率ではなく、「リクエスト処理時間」と「処理中のリクエスト数」を指標とするロードバランサーの仕組みが解説されています。このシステムは、YouTubeのサービスで2年以上の実績があるもので、実際の導入効果などもあわせて紹介されています。
今回は、2024年に公開された論文「Load is not what you should balance: Introducing Prequal」に基づいて、Borg環境における従来のロードバランサーの課題を説明しました。次回は、この課題に対応した新しいロードバランサー「Prequal」のアーキテクチャーを解説します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































