
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2025年に公開された論文「Necro-reaper: Pruning away Dead Memory Traffic in Warehouse-Scale Computers」に基づいて、Googleの研究者が考案した、CPUのキャッシュメモリの処理効率を上げる仕組み「Necro-reaper」を解説していきます。今回は、Necro-reaperの基本的なアイデアを説明します。
大規模な分散コンピューティングシステムでは、CPU、メモリ、ディスクなどのコンピューティングリソースを効率的に使用することが重要です。そのため、これらのリソースの使用状況を詳細にモニタリングしており、「第83回 Borgクラスター稼働状況の最新データ」では、Borgが管理するサーバー群のCPU、および、メモリ使用状況のレポートが紹介されています。また、最近の分析によると、Googleのデータセンターのように大規模なコンピューティング環境では、CPUとメモリの間のデータ転送速度が主要なボトルネックになりつつあることが指摘されています。このような環境では、大容量データを取り扱うことが多く、CPUのキャッシュメモリの容量を超えるデータを頻繁に読み込む必要があるため、メインメモリとキャッシュメモリの間のデータ転送が頻繁に発生して、この部分がボトルネックになることが多いということです。冒頭の論文では、このような状況を少しでも改善するために、CPUの命令セットを拡張して、メインメモリとキャッシュメモリの間の無駄なデータ転送を削減する方法を提案しています。
「無駄なデータ転送」が発生する例として、C言語で書かれた図1のコードを考えます。

図1 不要なメモリーアクセスが発生するコードの例(論文より抜粋)
1行目でメモリ領域(ヒープメモリ)を確保して、2行目で該当領域に変数valの値を書き込んでいます。C言語の仕様として、ヒープメモリとして確保した直後のメモリの値は不定になるので、この値を読み出すことは許されず、この例のように、必ず、新しい値で書き換える必要があります。しかしながら、これはあくまでC言語の仕様の話であり、CPUレベルのインストラクションでは、確保したメモリの値を読み出す処理が禁止されるわけではありません。そのため、上記のコードが実行されると、CPUレベルでは、一度、書き換えられる前のメインメモリの値をキャッシュメモリに転送した後、キャッシュメモリの値を変数valの値で書き換えるという処理が行われます。この場合、メインメモリからキャッシュメモリへのデータ転送は、プログラムの動作上は意味のない無駄な処理になります。
あるいは、4行目で確保したヒープメモリを解放した後に、5行目で該当データを保持していたキャッシュメモリを解放しています。5行目の処理によって、このキャッシュメモリは他のメモリ領域のキャッシュとして、再度、利用可能になります。この時、C言語の仕様上、解放されたメモリの内容は不定になるので、解放されたメモリの実際の値がどのようになっているかは関係ありません。しかしながら、これもまたC言語の仕様としての話であり、CPUレベルのインストラクションでは、5行目でキャッシュメモリを解放した際は、この時点でのキャッシュメモリの内容をメインメモリに書き戻す処理が行われます。この書き戻し処理もまた、プログラムの動作上は意味のない無駄な処理になります。図2は、メインメモリとキャッシュメモリの間のデータ転送のパターンをまとめたものですが、図の中の「savable」と書かれた部分がこれらの無駄な処理に該当します。
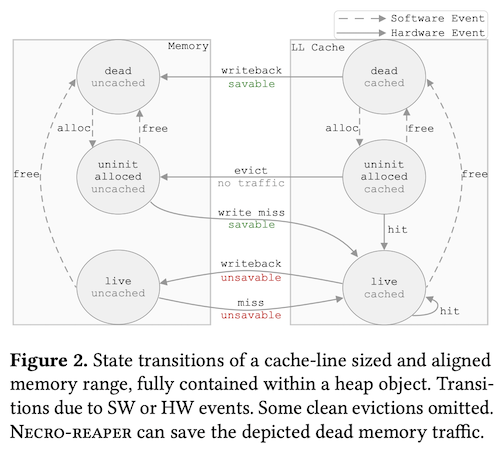
図2 メインメモリとキャッシュメモリの間のデータ転送(論文より抜粋)
そこで、CPUに新しいインストラクションを追加して、これらの課題を解決しようというのが、Necro-reaperの基本的なアイデアです。具体的には、次の2種類のインストラクションを追加します。
(1) Cache Line Installation:メインメモリの特定のアドレス範囲をキャッシュメモリに割り当てるが、メインメモリのデータはキャッシュメモリには転送しない。
(2) Cache Line Invalidation:メインメモリのアドレス範囲に対するキャッシュメモリの割り当てを解放するが、キャッシュメモリのデータはメインメモリに書き戻さない。
(1)のインストラクションを実行すると、CPUは、キャッシュメモリを介してメインメモリの特定のアドレス範囲にアクセスできるようになりますが、初期状態では、キャッシュメモリの内容は、対応するメインメモリの内容とは一致しません。必ず、メモリへの書き込み処理から開始する必要があります。また、(2)のインストラクションを実行すると、キャッシュメモリ上に書き込まれたデータは完全に破棄されます。該当のデータを再利用することは許されません。したがって、これらのインストラクションは、C言語の仕様に応じて、(図1のコードであれば、1~2行目、および、3~4行目など)ヒープメモリの確保/解放に対応した、適切な場合のみに使用する必要があります。Necro-reaperでは、専用のC言語コンパイラを用いて、これらのインストラクションを適切に利用するバイナリコードを生成します。
さらにまた、ヒープメモリとして確保したメモリ領域のすべてにキャッシュメモリを割り当てるのではなく、実際に書き込まれるデータ量の予測に応じて割り当てるキャッシュメモリの量を設定する、あるいは、ヒープメモリを解放する際に、該当のアドレス範囲が、この後すぐに新たなヒープメモリとして割り当てられる可能性が高い場合は、キャッシュメモリの割り当てをあえて解放せずに残しておくなど、キャッシュメモリの利用効率を上げるための最適化も考えられます。このように、Necro-reaperでは、新しいインストラクションを追加したCPUと、これらのインストラクションを効率的に活用するコンパイラの組み合わせで、メモリアクセスのボトルネックの削減を目指します。
今回は、2025年に公開された論文「Necro-reaper: Pruning away Dead Memory Traffic in Warehouse-Scale Computers」に基づいて、CPUのキャッシュメモリの処理効率を上げる仕組み「Necro-reaper」の基本的なアイデアを説明しました。次回は、コンパイラによる最適化処理の詳細を解説していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































