これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2017年に開催されたSREcon17 Asia/Australiaでの講演「SRE Your gRPC--Building Reliable Distributed Systems」をもとにして、マイクロサービス型のアプリケーションにおけるgRPCの役割を解説します。この講演では、複数のマイクロサービスを組み合わせた、分散アーキテクチャーのアプリケーションを安定運用するためのガイドが示されており、gRPCを用いたサンプルコードによる解説が加えられています。ここでは特に、マイクロサービス・システムの安定稼働という観点から、gRPCの活用法を紹介したいと思います。
Googleにおけるアプリケーション開発では、スケーラブルなマイクロサービス型のアーキテクチャーが基本となっており、サービス間の通信処理を担うコンポーネントとして、Stubbyと呼ばれる独自のRPCライブラリーが利用されてきました。gRPCは、このライブラリーをオープンソースとして再実装したもので、さまざまなプログラミング言語で使用することができます。
マイクロサービスの呼び出しには、REST APIもよく利用されますが、REST APIが既存のHTTP(S)プロトコルをそのまま利用しているのに対して、gRPCでは、HTTP/2プロトコルをベースとして、マイクロサービスの連携に必要なさまざまな機能が実装されています。具体的には、アプリケーションレイヤーでのフロー制御、多段階にわたるサービス呼び出しの連携、ロードバランスとフェイルオーバー、双方向のストリーミング通信などがあります。詳細については、gRPCのホームページの説明が参考になるでしょう。
冒頭の講演では、マイクロサービス・アーキテクチャーのアプリケーションを安定運用するためのガイドとして、次の6つの項目が上げられています。今回は、前半の3つについて、説明していきます。
まずはじめの「Everything is (secretly) a stack.」は、コンポーネント間のインターフェースについて説明しています。マイクロサービス・アーキテクチャーでは、一般に、1つのサービスは複数のコンポーネントから利用されます。図1(上)では、「Translator」(翻訳サービス)を複数の外部システムが呼び出す様子が示されていますが、実際には、図1(下)のように、それぞれのコンポーネントの内部に、さらに多層のコンポーネントを内包した複雑な構造が隠されています。この時、サービスの呼び出し方法をgRPCなどを用いて標準化しておき、サービス内部の実装を外部コンポーネントに対して隠蔽することがマイクロサービス設計の基本となります。これにより、外部のコンポーネントに影響を与えずに、内部の実装を変更することが可能になります。
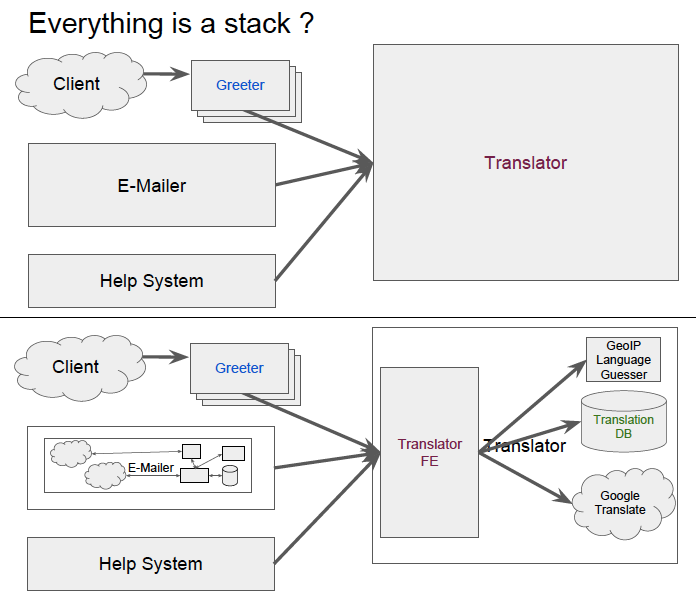
図1 複数コンポーネントによるサービスの呼び出し(講演資料より抜粋)
ただし、現実のサービス環境では、あるサービスが外部に提供する機能そのものをアップデートしていく必要もあります。この際、外部から見えるサービス仕様の変更が外部コンポーネント(クライアント)に及ぼす影響を最小化するための工夫が必要となります。gRPCでやり取りするメッセージでは、Protocol Buffers(プロトコルバッファ)が標準的なフォーマットとして利用されますが、冒頭の講演では、図2の例を用いて、そのような工夫の一例を紹介していました。

図2 サービスの機能を更新する例(講演資料より抜粋)
1つ目の例は、翻訳文のタイプ指定オプションを「RUDE」から「SLANG」に変更するものです。既存の「RUDE」をいきなり「SLANG」に変更するのではなく、新しいオプションとして「SLANG」を追加した上で、既存の「RUDE」にdeprecated指定を追加しています。クライアントライブラリが対応している場合、この指定を持ったフィールドをライブラリから使用すると、コンパイル時に警告が表示されて、使用の停止が促されます。2つ目の例は、既存のフィールド(language)を廃止する例です。この場合も、該当のフィールドをただ削除するのではなく、reserved指定を行っています。これは、将来、同じフィールドが誤って再利用されることを防止する機能です。同じフィールドが別の目的に使用されてしまうと、古いバージョンのクライアントがこのフィールドを用いた際に、予想外の動作が起きる可能性があります。そのような問題の発生を事前に防止しているというわけです。
次の「Sharing is caring.」は負荷分散の手法に関する説明です。ここでは、アクセスの偏りをさけつつ、大量のサーバーに対して、最適にアクセスを分散するための考え方が紹介されています。この部分については、gRPCとの直接の関連はありませんので、詳細については、冒頭の講演資料を参照してください。
3つ目の「Fail early.」は、サービス呼び出しに対して、Deadline(時間制限)を設けるという考え方です。図3の例では、左端のクライアントが「Greeter」アプリケーションにアクセスすると、内部的に「Translator FE」(翻訳サービス・フロントエンド)を呼び出して、それがさらに「Translation DB」を呼び出すという階層構造になっています。この時、翻訳サービスに対する応答時間の要求は、アプリケーションによって異なります。アプリケーションによっては、クライアントを長時間待たせるよりは、早めにエラーメッセージを表示した方がよい場合もあるでしょう。
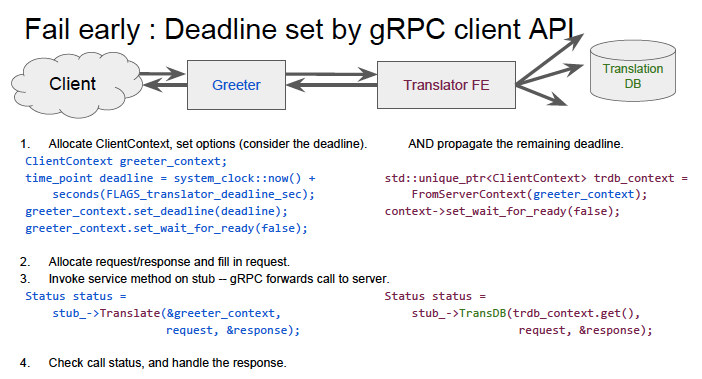
図3 サービス呼び出しのDeadlineを設定する例(講演資料より抜粋)
gRPCでは、サービスを呼び出す側でDeadline(処理完了時刻)を指定することができるようになっており、指定時刻までにサービスからの応答が得られない場合は、タイムアウトを発生します。図3のような階層的な呼び出し構造を持つ環境では、呼び出し側でセットしたDeadlineの指定値を受け取って、それをさらに、次の階層を呼び出す際のDeadlineに指定するといった処理も可能です。これにより、Greeterアプリケーション側でタイムアウトが発生した際に、バックエンドのTranslation FE側も同時にタイムアウトするといった動作が実現できます。また、gRPCでは、通信を行う双方の稼動状態が「チャネルの状態」として管理されています。サーバー側のチャネルの状態が正常でない場合、呼び出し側は、Deadlineを待たずに即座にエラーを受け取ることができるので、サーバー障害時に無駄な待ち時間が発生しなくなります。
ちなみに、先ほど、GreeterアプリケーションがTranslator FEからの応答が遅いためにタイムアウトし、クライアントにエラーを返したとする時、Tranlator FE側でもタイムアウトさせることができると説明しました。これは、常に正しい振る舞いと言えるでしょうか? ―― 実は、これが正しい振る舞いかどうかは、システム環境によって変わります。一般には、バックエンド側でこれ以上処理を継続する意味はないので、Translator FEの処理も中断することが妥当と考えられます。しかしながら、Translator FEが処理結果をキャッシュする機能を持っており、さらに、類似の処理依頼が頻繁に送られてくる環境であればどうでしょう。この場合、あえて処理を完了させて、結果をキャッシュしておけば、次回の呼び出し時に、再度、はじめから処理をやり直す必要がなくなります。あくまでも、アプリケーションやサービスの特性に応じて、適切な振る舞いを決定していくことが重要というわけです。
今回は、SREcon17の講演資料をもとにして、マイクロサービス・アーキテクチャーの設計において、gRPCの機能がどのように役立つのか、主に2つの観点で説明しました。次回は、残りの3つの観点について、説明を続けたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































