
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2003年に公開された論文「Web Search for a Planet: The Google Cluster Architecture」を紹介します。これは、17年前に公開されたもので、当時のGoogleのサーバーインフラの情報が提供されています。現在のインフラとは異なる点も多いと想像されますが、論文のタイトルにもあるように「Planet」スケールのサービスを提供するための考え方が示されており、現代的なクラウドシステムのアーキテクチャーをあらためて見直すという意味でも興味深い内容になっています。
この論文の冒頭では、当時の検索システムでは、15,000台以上のコモディティPCが利用されており、次の2つの基本方針をもとにアーキテクチャー設計がなされているとの説明があります。
(1) サーバー専用のハードウェアの代わりにコモディティPCでクラスターを構築して、ソフトウェアで信頼性を確保する。
(2) 高いスループットが得られるように、リクエストの並列処理性能を高める設計を行う。
(1)については「コモディティPC」という表現が印象的ですが、これは安価なPCであれば何でも構わないという意味ではなさそうです。この後で説明するように、当時の検索システムを動かす上で最適なCPUの構造などを分析しており、この言葉の背後には、「自分たちの目的にあったシステム構成を追求する」という合理的な考え方があるようです。(2)については、図1の概要図と共に、検索インデックス、および、検索対象のドキュメントが複数のサーバーに分散配置されていることが説明されています。特に同一のデータを複数のサーバーに複製することで、並列処理の性能を高めるとともに、障害発生時の冗長性を担保している点が強調されています。
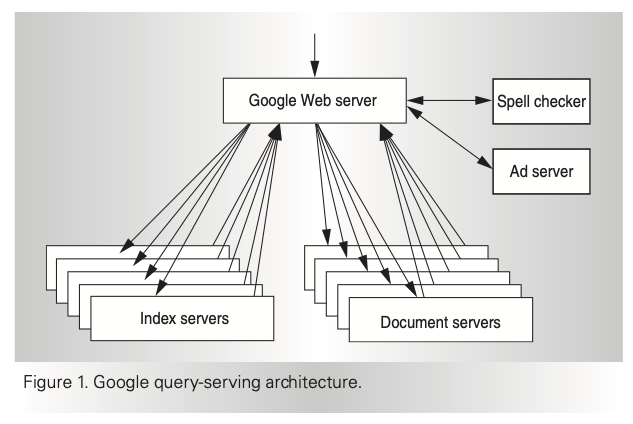
図1 検索システムのアーキテクチャー概要(論文より抜粋)
論文の中では、検索エンジンというサービスの特性がこのような並列処理システムに適していたと説明されています。しかしながら、マイクロサービスを用いた分散型のアーキテクチャーは、現在のクラウドシステムでは一般的になりつつあり、検索エンジンとは特性の異なるサービスもマイクロサービス・アーキテクチャーで実装されています。スケーラビリティの他にも、アジャイル開発との親和性など、マイクロサービスにはいくつかの利点がありますが、当時の並列処理システムの設計から得られた知見が、現在のマイクロサービス・アーキテクチャーへと進化する過程を見直すのも面白いかも知れません。
先ほど触れたように、この論文の中では、アプリケーションの特性に適したCPUの構造が分析されています。論文執筆当時は、サーバーのCPUとしてPentium Ⅲを主に使用しており、これは、1クロックサイクルあたり3個のインストラクションを実行する機能を持ちます。しかしながら、インデックスサーバーでCPU上のインストラクションの実行状況を分析すると、図2の結果が得られたそうです。
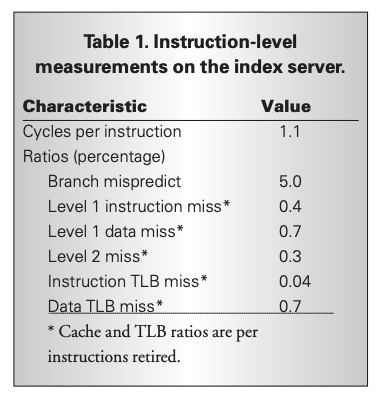
図2 インデックスサーバーでのインストラクション実行状況(論文より抜粋)
「Ratios(percentage)」以下に示された数値は、実行中の命令に対する分岐予測の失敗やキャッシュミスなど、CPUの実行性能を低下させる要因を示すものですが、これらの要因により、平均的なインストラクションの実行数は、1クロックサイクルあたり1.1個に抑えられています。これは、インデックスサーバーでは、検索リクエストに応じてさまざまなタイプのデータを処理する必要があり、分岐予測やデータのキャッシュなど、CPUの実行性能を上げるための機構が働きにくいことが要因と分析されています。当時は、Pentium Ⅲより高性能で、1クロックサイクルあたりのインストラクション実行数がより多い、Pentium 4も提供されていましたが、仮にPentium 4を用いても、上記の要因を考慮すると、実際上はそれほど大きな性能差がでないとの結論が記されています。
このように、サーバーアーキテクチャーの設計においては、アプリケーションの特性に応じた、CPUの構造レベルでの分析までもが行われています。「Planet」スケールのサービスを実現するための合理的で緻密な戦略が感じられるのではないでしょうか。
今回は、2003年に公開された論文「Web Search for a Planet: The Google Cluster Architecture」を紹介しました。当時の検索システムのサーバーアーキテクチャーは、「コモディティPCで大規模な並列処理を行う」と簡単に紹介されることもありますが、その背後にはさまざまな技術的な考察があるようです。論文の中では、メモリーの性能やマルチコアCPUに関する考察、あるいは、複数世代のサーバーが混在する問題についても触れられていますので、興味のある方は、ぜひ論文の方も参照してください。
次回は、また少し話題を変えて、ユーザー端末の構成管理に関する論文を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































