
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2020年に公開された論文「Autopilot: Workload Autoscaling at Google Scale」を元にして、Googleのデータセンターのクラスター管理システム(Borg)で用いられる、オートスケーリングの仕組み(Autopilot)を紹介していきます。今回はまず、垂直スケーリングに用いられる、リソース使用量の予測モデル(統計モデル)を解説します。
前回の記事では、Googleのデータセンターでは、独自のクラスター管理システム(Borg)により、さまざまなジョブ(アプリケーション)をコンテナでデプロイしている事を説明しました。1つのジョブに対して、複数の「Task」が起動しますが、この際、1つのTaskに割り当てるCPU時間とメモリー容量の上限(垂直スケーリング)、および、Taskの数(水平スケーリング)を設定することができます。Autopilotは、稼働中のジョブに対して、これまでのリソース使用状況に基づいて、これらの設定値を自動調整する機能を提供します。全体の構成は、図1のようになります。
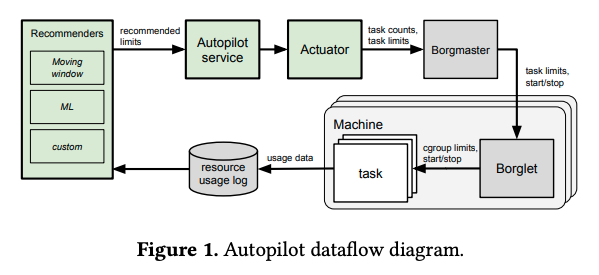
図1 AutopilotとBorgの連携(論文より抜粋)
この図から分かるように、Autopilotは、Borgそのものに組み込まれているわけではありません。Borgが出力するログデータを元に「Recommenders」が適切な設定値を提案した後に、BorgのAPIを通じて設定値を反映する処理を定期的に実行します。冒頭の論文では、Recommenderが適切な設定値を計算するアルゴリズムが解説されています。
垂直スケーリングについては、1つのTaskが使用するリソース量について、過去のリソース使用量からこの後の使用量を予測し、それを設定値として提案します。たとえば、過去の一定期間の平均値を計算して予測値にするといった、単純な統計値による予測が考えられます。あるいは、安全策をとるのであれば、過去の一定期間における最大値を予測値として採用する方法もあるでしょう。Autopilotでは、このようないくつかの計算方法がモデルとして用意されており、ジョブの特性に応じてモデルを選択することができます。ここでは、これを「統計モデル方式」と呼びます。
また、それぞれの統計モデルには、この後で説明する「データの重み付け」など、チューニング可能なパラメーターが含まれています。Autopilotには、「機械学習方式」のReommenderも用意されており、こちらは、使用する統計モデルの選択、および、そこに含まれるパラメーターの値を機械学習で決定することができます。機械学習アルゴリズムの詳細は論文に譲りますが、大雑把に言うと、「割り当てたけれど使用されなかった無駄なリソース量を減らす」、そして、「Taskに割り当てたリソースが不足しないようにする」という相反するゴールに対して、両方のバランスが取れたモデルの選択とパラメーター値の決定を行います。
ここでは、論文内で解説されている「統計モデル方式」について、その概要を説明します。それぞれ、過去データから予測値を計算するわけですが、単純に一定期間のデータを切り出すわけではありません。より古いデータになるほど指数関数的に重みが小さくなるようにして、直近のデータを重要視した計算を行います。具体的には、CPU使用量については12時間前のデータの重みが1/2、メモリー使用量については48時間前のデータの重みが1/2となるように計算します。これは、メモリー使用量よりも、CPU使用量の方が時間的な変化が大きいという前提によるものです。
また、使用できる統計モデルには、大きく次の3種類があります。「jパーセンタイル補正方式」の具体的な計算式については、論文を参照してください。
・最大値方式:上述の「重み付け」は用いずに、指定期間における最大値を予測値とします。
・重み平均方式:上述の重み付けによる平均値を予測値とします。
・jパーセンタイル補正方式:平均値を一般化した計算方式で、90パーセンタイルや95パーセンタイルに相当する値を求めて予測値とします。
そして、ジョブの種類に応じて、CPUの予測値計算、メモリーの予測値計算のそれぞれについて、上述のいずれかの方式を選択します。たとえば、バッチジョブの場合は、CPUの予測値計算は「重み平均方式」を利用します。バッチジョブの場合、CPUリソースが一時的に不足してもその時点での処理速度が落ちるだけで、ジョブ全体の完了時間(スループット)には大きな影響がないと考えられるからです。一方、レイテンシーを保証する必要があるリアルタイム処理のジョブについては、「jパーセンタイル補正方式」を用いた上で、ジョブの優先度に応じて、90パーセンタイルや95パーセンタイルなどを選択します。メモリーの予測値計算についても同様で、一般のジョブには「jパーセンタイル補正方式」を用いますが、メモリー不足を確実に避ける必要がある場合は、「最大値方式」を用います。最後に、これらの予測値に10〜15%の安全マージンを加えたものを実際の設定値として採用します。
今回は、2020年に公開された論文「Autopilot: Workload Autoscaling at Google Scale」に基づいて、Borgと連携したオートスケールの仕組み、特に、垂直スケーリングの「統計モデル方式」を紹介しました。次回は、Taskの数を増減する水平スケーリングの仕組み、そして、Autopilotの効果を計測したデータを紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































