
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回のコラムでは、分散型ロードバランサー「Maglev」を理解する準備として、一般的なロードバランサーの動作を解説した上で、「分散処理を実現する上での課題」を説明しました。Maglevは、これらの課題をどのように解決しているのでしょうか? 公開論文「Maglev: A Fast and Reliable Software Network Load Balancer」に基づいて、その仕組みをひも解いていきましょう。
前回あげた課題は、コネクショントラッキングとDSR(Direct Server Return)に関連するものでした。まず、DSRの課題から説明すると、DSRの構成でロードバランサーから転送先のWebサーバーにパケットを送信する際は、L2レイヤーでの転送が必要になります。小規模な環境では、すべてのWebサーバーを同一のサブネットに配置すれば、L2レイヤーでの転送が可能ですが、複数のデータセンターにまたがって負荷分散するような際は、これは現実的な構成ではありません。
Maglevにおけるこの問題の解決方法は、実は意外とシンプルです。先ほどの論文によると、GREトンネルによるオーバーレイネットワークを用いて、L3ネットワーク上でL2接続を実現しているそうです。ちなみに、この論文では、Googleが実サービス環境でMaglevの使用を開始したのは、2008年からと説明しています。最近では、SDN、あるいは、ネットワーク仮想化の考え方が広まるにつれて、オーバーレイネットワークもそれほどめずらしいものではなくなりました。その一方で、Googleでは、2008年の段階でオーバーレイネットワークを実活用していたというのは、興味深い事実ではないでしょうか。
次は、コネクショントラッキングの説明です。コネクショントラッキングでは、5tuple、すなわち、IPパケットのヘッダーに含まれる「プロトコル番号(TCP/UDP/ICMPなど)、送信元IP、送信元ポート番号、宛先IP、宛先ポート番号」の組から、転送先のWebサーバーを一意に決定する必要がありました。この際、5tupleと転送先Webサーバーの対応は、すべてのMaglevサーバーで同一に保つ必要があります。これが必要な理由を図1の全体像を用いて説明していきます。
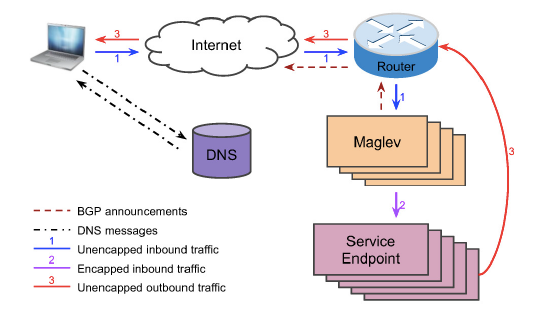
図1 Maglevの全体構成(論文より抜粋)
前回説明したように、クライアントはDNSサーバーから接続先の代表IPアドレスを取得して、インターネット経由でMaglevが稼働するデータセンターへとパケットを送信します。データセンター内では、ネットワークルーターから複数のMaglevサーバーへとパケットが振り分けられますが、この部分は、ルーターが提供するECMP(Equal Cost Multi Path)の機能で行われます。ただし、ECMPの機能の詳細は、使用するルーターによって異なります。高機能なルーターであれば、単純にラウンドロビンでパケットを振り分けるのではなく、同一の5tupleを持つパケットを同じMaglevサーバーに転送するということも可能です。もしも、ECMPによってこれが保証されるのであれば、前述の課題はなくなります。とはいえ、現実には、ECMPの完全性を期待するわけにはいきません。先の論文では、メンテナンスに伴うルーターの切り替え処理などで、振り分け先が変わる可能性を指摘しています。
そこで、Maglevでは、どのパケットがどのMaglevサーバーに届いたとしても、同一の5tupleを持つパケットは、必ず同じWebサーバーに転送されるように、「コンシステントハッシング」を使用します。これは、5tupleの値を元に、一定のアルゴリズムを用いて、転送先Webサーバーを計算する手法です。すべてのMaglevサーバーが同一のアルゴリズムを用いることで、5tupleと転送先Webサーバーの組み合わせを共通化することが可能になります。―― というと、簡単な話のようにも思われますが、ここで大切になるのは、転送先のWebサーバーが増減した場合の対応です。
たとえば、Maglevサーバーは、転送先のWebサーバーのヘルスチェックを行い、特定のWebサーバーが障害停止した際に、パケットの転送対象から除外します。この際、停止したWebサーバー宛のパケットを他のWebサーバーに単純に再割当てした場合、再割当て先のWebサーバーの負荷が他よりも高くなってしまいます。大規模な環境であればあるほど、パケットを均等に分散して、すべてのサーバーの性能を無駄なく使い切ることが重要になります。そのため、残ったWebサーバーに対して均等にパケットが再配分されるように、先ほどのアルゴリズムを更新する必要があります。
ただし、ここで、Webサーバー群全体への割り当てを不用意に更新すると、既存の通信に影響が発生します。障害が発生したWebサーバー宛のパケットは、一旦、コネクションをリセットして、新たに他のWebサーバーに割り当てる他ありませんが、稼働中のWebサーバーの通信に対して、同じことが発生するのは好ましいことではありません。そのために、「残ったWebサーバーに均等にパケットを配分しつつ、既存の接続先については、接続先の変更を最小限に抑える」というアルゴリズムが必要になります。Maglevでは、「Maglevハッシング」と呼ばれる独自のアルゴリズムでこれを実現しています。
アルゴリズムの中身はそれほど複雑なものではありませんので、詳細は論文に譲ることにして、ここでは、具体的な計算例を紹介しておきます。図2の「Before」では、5tupleの値からハッシュ値を計算して、パケットを0〜6の7種類のグループに分けた後に、各グループのパケットをB0〜B2の3つのWebサーバーに振り分けています。そして、「After」は、WebサーバーB1が障害停止した後の振り分け先になります。これを見ると、障害の発生前後において、7つのグループはすべてのWebサーバーに(端数を除いて)均等に振り分けられています。その一方で、転送先のWebサーバーが変更されているのは、(障害が発生したB1に属するグループを除けば)グループ6だけになります。このような計算処理を実現するアルゴリズムが、Maglevハッシングです。論文の中では、他のアルゴリズムと比較して、バックエンドのWebサーバーの台数によらず、より均等で、安定的な負荷分散を実現するという計算結果が紹介されています。
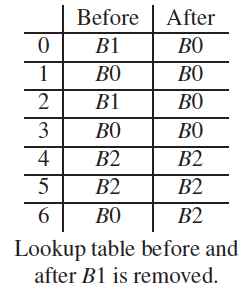
図2 Maglevハッシングによる割り当て先の変更例(論文より抜粋)
DSRとコネクショントラッキングへの対応以外にも、Maglevにはいくつかの特徴があります。その中でも、特に驚かされるのが「ユーザープロセスで直接にネットワークパケットを処理する」という実装です。通常、Linuxでは、Linuxカーネルのネットワークレイヤーによって、ネットワークパケットの処理を行います。しかしながら、Linuxカーネルのネットワーク機能は、高機能で便利な反面、特定のネットワーク処理に特化してチューニングされているわけではありません。Maglevでは、Linuxサーバーを用いて高性能なロードバランサーを実現するために、ユーザープロセスがNICから直接にパケットを受け取り、ロードバランサーの処理に特化した高速なパケット処理を実現しています。
―― 「ユーザー空間でパケットを処理する仕組みといえば、Intel DPDKだよね?」という声が聞こえてきそうですが(*1)、Maglevは2008年から実稼働しているという事実を思い出せば、驚きの理由がお分かりいただけると思います。論文の中では、複数のユーザープロセスが連携して、効率的にパケット処理を実現する仕組みについても解説がなされています。
今回は、分散型のロードバランサーを実現する「Maglev」について、GREトンネル、Maglevハッシング、そして、ユーザー空間でのパケット処理という観点で、その技術的な特徴を紹介しました。次回は、Hadoopの分散データストア「HDFS」の基礎ともなった、「Google File System(GFS)」を紹介したいと思います。
*1 Intel DPDKについては、筆者のコラム記事「第53回 NFVとIntel DPDK(前編)」を参考にしてください。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































