
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2003年に発表された論文「The Google File System」から、Google File System(GFS)を紹介します。GFSは、数千台規模のクライアントがアクセスする分散型の共有ファイルシステムを実現するソフトウェアで、2003年に発表されたこの論文において、Google社内の開発、データ分析、そして、実サービス環境で使用されていることが公表されました。
GFSの特徴は、Google社内における共有ファイルの利用パターンに特化して設計されている点にあります。特定の目的を実現するために、できるだけシンプルで、そして、高性能なシステムを根本から設計するという点で、システム設計の考え方を学ぶ上でも参考になります。それほど難しい内容ではありませんので、ぜひ一度、論文そのものにも目を通してみることをお勧めします。
なお、論文の中では、ディスク容量やネットワーク速度など、性能に関わる具体的な数値も記載されていますが、これはあくまで、2003年当時(つまり、10年以上前)の数値である点には注意が必要です(*1)。
GFSが特化する「Google社内における共有ファイルの利用パターン」とは、どのようなものでしょうか? 論文の中では、次のような点が説明されています。
このようなファイルアクセスを行う例としては、サーバー間での大容量データの受け渡し、あるいは、データ集計のストリーミング処理(多数のサーバーが並列処理した結果を1つのファイルに書き出しながら、それを別のサーバーが読み出していく)が挙げられています(図1)。GFSは、これら以外の処理(小さなサイズのファイルの保存、ランダムな書き込み処理など)にも対応はしていますが、性能面では考慮の対象外とされています。
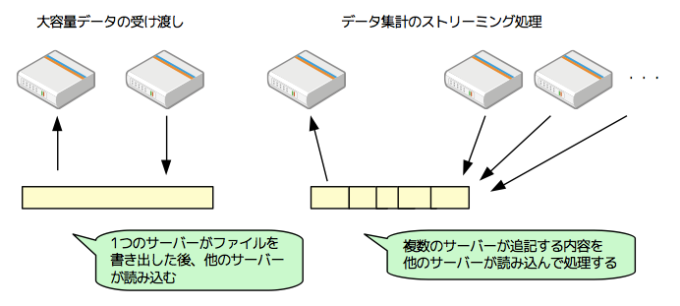
図1 共有ファイルシステムの利用例
GFSの全体的なサーバー構成は、図2のようになります。1つのファイルは、64MBの「チャンク」に分割されて、それぞれのチャンクは、多数の「チャンクサーバー」に分散保存されます。個々のチャンクは、Linux上の通常のファイルとして保存されており、冗長化のために1つのチャンクは、複数のチャンクサーバー(デフォルトでは3箇所)に保存されます。また、ファイルシステム全体のディレクトリー構成(ネームスペース)は、「マスターサーバー」のメモリー上で管理されます。ファイルの追加や削除が行われた場合、マスターサーバーは、ディスク上のジャーナルログに変更を書き込んだ上で、メモリー上の情報を書き換えます。これにより、マスターサーバーが障害停止した際にネームスペースの情報が失われることを防止しています。
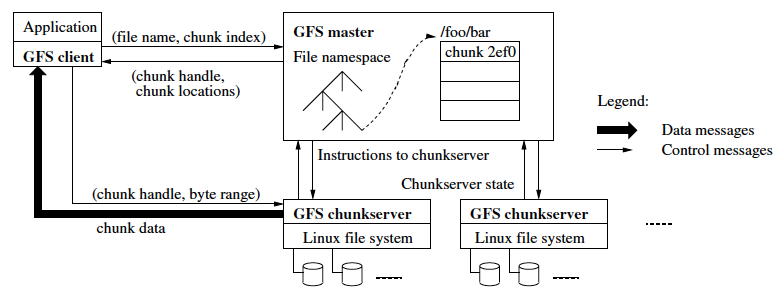
図2 GFSのアーキテクチャー(論文より抜粋)
また、個々のファイルを構成するチャンクには、ユニークなIDが振られており、どのIDのチャンクが、どのチャンクサーバーに保存されているかという対応関係も、マスターサーバーのメモリー上で管理されます。ただし、この情報は、マスターサーバー上のディスクに永続化されるわけではありません。チャンクサーバーは、自発的にマスターサーバーにコンタクトして、自身が保存するチャンクIDの一覧をマスターサーバーに提供するようになっています。また、マスターサーバーは、チャンクサーバーと定期的にハートビートを取り合っており、応答が無くなったチャンクサーバーの情報はメモリーから削除します。これにより、マスターサーバー側でチャンクサーバーの一覧を集中管理する必要がなくなり、障害停止したチャンクサーバーを交換したり、あるいは、既存のチャンクサーバーのIPアドレスを変更するなどの処理が容易になります。
クライアントがファイルにアクセスする際は、マスターサーバーからアクセス対象部分のチャンクを保存しているチャンクサーバーの情報を取得して、クライアントからチャンクサーバーに直接にアクセスを行います。この部分の処理は、ユーザー空間で動作するクライアントライブラリーが用意されており、GFSを使用するアプリケーションは、ライブラリー関数を用いてファイルへのアクセス処理を行います。このような、(通常のファイルシステムとしてマウントするわけではない)アプリケーションからのアクセスに特化した設計は、クラウドサービスとして提供されるオブジェクトストレージでは一般的な考え方です。社内のシステム環境をいちはやくクラウド化してきた、Googleならではの発想が垣間見える部分かも知れません。
今回は、Google File System(GFS)が対象とするファイルアクセスのパターン、そして、システム全体のアーキテクチャーの概要を紹介しました。ただし、これだけでは、GFSが高い性能を発揮する理由がよくわからないかも知れません。次回は、前述のアクセスパターンに対して高いスループットを実現するファイルアクセス処理の仕組み、そして、データの信頼性を担保する仕組みを解説したいと思います。
*1 2010年に開催された「Google Faculty Summit」では、GFSの後継となる新しいファイルシステム「Colossus」を使用していることが紹介されています。「Storage Architecture and Challenges at Google Faculty Summit 2010」
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































