
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2006年に公開された論文「Bigtable: A Distributed Storage System for Structured Data」をもとに、分散キーバリューストア「Bigtable」の構造を解説します。前回、Bigtableを構成するサーバーの全体像を紹介した際に、次のような疑問点を指摘しました。
(1) クライアントは、アクセス対象の行を含むTablet、および、該当のTabletを担当するTabletサーバーをどのようにして発見するのか?
(2) マスターサーバーは、Tabletサーバーの障害をどのように検知して、Tabletの再割り当てを行うのか?
(3) Tabletの実体は、「memtable」と「SSTable」によってどのように構成されているのか?
今回は、これらの点について解説を進めていきましょう。
Bigtableで作成したテーブルに含まれる行は、Row Keyの文字列に対して辞書順にソートされており、1つのテーブルを複数のTabletに分割する際は、この順序が保持されます。つまり、1つのTabletは、一定範囲のRow Keyに対応する行を含みます。そして、1つのテーブルに含まれるTabletの位置情報は、Root tablet、および、METADATA tabletと呼ばれる、特別なTabletに記録されます。
これは、図1のようなツリー型の階層構造になっており、Row Keyの範囲ごとに次のTablet(および、それを担当するTabletサーバー)が指定されており、このツリーをたどっていくことで、該当のRow Keyを含むTabletを検索することができます。また、Root tableを担当するTabletサーバーの情報は、分散ロックサービスを提供するChubbyに保存されています。クライアントは、ChubbyからRoot tableの情報を取得した後、自分自身でツリーをたどってTabletの検索を行います。
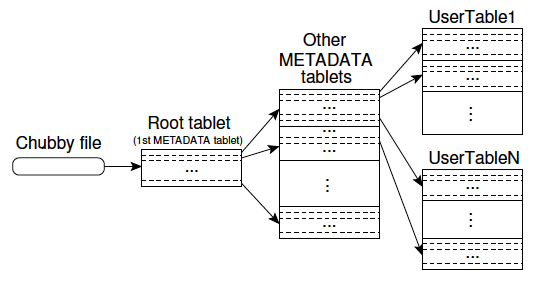
図1 Talbetの位置情報の検索ツリー(論文より抜粋)
この結果からわかるように、クライアントはマスターサーバーにアクセスすることなく、Tabletサーバーの情報を取得して、該当のTabletサーバーに直接にアクセスすることができます。Bigtableのマスターサーバーは、基本的にはクライアントからのアクセスを受けることがないため、処理の負荷はそれほど大きくありません。この後で説明するように、Tabletサーバーの状態を管理することがマスターサーバーの役割になります。万一、マスターサーバーが障害停止した場合でも、クライアントはテーブルへのアクセスを継続することが可能です。なお、クライアントは、Tablet情報の検索結果(Talbetとそれを担当するTabletサーバーの情報)をキャッシュすることで、前述の検索処理の負荷を下げるように設計されています。
Tabletサーバーが起動すると、自身の存在をChubbyに登録した後、マスターサーバーから担当するべきTabletが割り当てられるのを待ちます。新しいテーブルが作成された場合、あるいは、既存のTabletサーバーが障害停止した場合など、マスターサーバーは、リソースに余裕のあるTalbetサーバーに対して、新たなTabletを割り当てます。1つのTabletサーバーは、一般に複数のTabletを担当します。
Tabletサーバーは、自身が担当するTabletに対応する排他ロックをChubbyから取得した上で、Tabletの操作を行いますので、複数のTabletサーバーが誤って同じTabletを操作することはありません。何らかの理由で排他ロックを失ったTabletサーバーは、自発的に再起動して、該当のTabletに対する処理を停止します。
マスターサーバーは、Chubbyに登録された情報から、起動中のTabletサーバーの存在を把握します。それぞれのTabletサーバーに対して、排他ロックの取得状態を定期的に問い合わせることで、Tabletサーバーの状態をチェックします。排他ロックの取得が確認できない場合、該当のTabletサーバーは障害停止しているものと判断して、新しいTabletサーバーにTabletの再割り当てを行います。この際、該当のTabletサーバーの登録をChubbyから削除します。
また、何らかの理由でマスターサーバーが再起動した場合、マスターサーバーは、Chubbyから既存のTabletサーバーの一覧を取得した後に、クライアントと同様の処理によって、すべてのTabletの情報を取得します。つまり、マスターサーバーが障害停止した際の切り替え処理もそれほど難しくはありません。
最後にTabletの物理的な実体を説明します。1つのTabletは、論理的には、一定範囲のRow Keyの行を含む、テーブルの一部分です。そして、Tabletの実体は、GFS上のSSTableとTabletサーバーのメモリー上にあるmemtableから構成されます(図2)。SSTableは、Key-Value形式でデータを保存した読み込み専用のファイルで、その内容を書き換えることはできません。ある時点でのTabletの内容がSSTableに固定的に保存されていると考えてください。
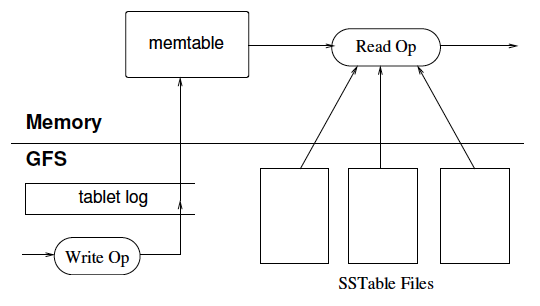
図2 Tabletの実体を構成する要素(論文より抜粋)
その後、Tabletに書き込みが入ると、GFS上の「Tabletログ」に変更内容が追記された後、同じ内容がmemtableにも追加されます。Tabletサーバーは、SSTableの内容とmemtableの内容を結合することで、最新のTabletの内容を把握します。GFS上のファイルに対する書き込みをTabletログに対する追記処理に限定することで、ファイル書き込み処理のオーバーヘッドを低減していることがわかります。さらに補足すると、SSTableの末尾には、SSTable内のKeyに対するインデックス情報が記載されており、Tabletサーバーは、このインデックスをメモリー上に保持します。そのため、SSTableの内容にアクセスする際は、インデックスからファイル上のオフセットを取得することで、必要な情報が書き込まれた位置を特定します。1つのSSTableは、特定のカラムファミリーのデータを保持しており、カラムファミリーのオプション指定により、該当するSSTable全体をメモリーに読み込んでおくことも可能です。
ただし、この処理を長く続けていると、memtable、および、ログファイルが肥大化してくるため、一定のタイミングで「コンパクション」が実施されます。これには、「マイナーコンパクション」と「メジャーコンパクション」の2種類があります(図3)。まず、マイナーコンパクションは、その時点のmemtableの内容を新しいSSTableとしてGFSに書き出して、memtableの内容をクリアするというものです。この処理によって、新しいSSTableが追加されていきます。既存のSSTableの内容はあくまで不変ですので、古い内容を保持したSSTableと新しい変更を保持したSSTableが混在することになります。そして、このような混在を解消するのが、「メジャーコンパクション」です。こちらは、複数のSSTableの内容を結合して、古い内容を削除した上で、新しいSSTableにまとめ直します。
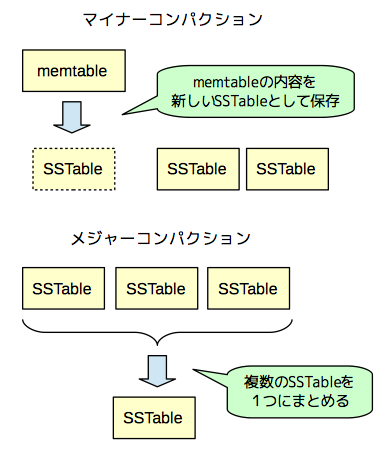
図3 マイナーコンパクションとメジャーコンパクション
ちなみに、Tabletサーバーが障害停止した場合、memtableの内容は失われますが、同じ内容がTabletログにも保存されているので、データが失われることはありません。新しく該当のTabletを割り当てられたTabletサーバーは、GFSに保存されたTabletログとSSTableを用いて、もとのTabletサーバーと同じ状態を再現することが可能です。
この他には、Tablet全体のデータ量が大きくなった際に、1つのTabletを2つに分割する、あるいは、データが削除されて小さくなったTabletに対して、2つのTabletを1つに結合するといった処理が実行されることもあります。特に面白いのが、Tabletを分割する際の動作です。それぞれのTablet用に、SSTableを分割するという処理は行われません。SSTableの内容は不変ですので、それぞれのTabletが同じSSTableを共有して、必要な部分のみを参照するという動作を行います。その後、メジャーコンパクションのタイミングで、それぞれのTablet用のSSTableが生成されます。
今回は、Bigtableの内部構造について解説を行いました。冒頭の論文では、この他にも次のような機能について解説が行われており、性能向上に向けたさまざまなこだわりが感じられます。
論文には、性能測定のベンチマーク結果も記載されています。その他には、Google Analytics、Google Earchなど、実際のアプリケーションにおける利用例も紹介されていますので、GCPでCloud Bigtableを利用する際のデータ設計の参考にもなるでしょう。
次回からは、Bigtableとはまた異なる種類のデータストアとなる、「Megastore」を紹介していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































