
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回から2回に分けて、2006年に公開された論文「Bigtable: A Distributed Storage System for Structured Data」をもとに、分散キーバリューストア「Bigtable」の構造を解説します。ご存知の方も多いかも知れませんが、オープンソースのNoSQLデータベースであるHBaseは、Bigtableをモデルに設計されており、ユーザーから見た利用方法には高い類似性があります。(実際、Google Cloud Platformで提供されるCloud Bigtableでは、HBase互換APIが提供されています。)
それでは、内部の実装については、どのような類似性、あるいは、違いがあるのでしょうか? HBaseのアーキテクチャーについては、さまざまな解説記事が公開されていますので、そちらを参照していただくことにして、ここでは、Bigtableの内部構造をじっくりと紹介したいと思います。
はじめに、Bigtableのデータモデル、すなわち、ユーザーから見た際のデータの格納・検索方法について簡単に説明します。Bigtableでは、1つのテーブルに対して、行単位でデータの読み書きを行います。1つの行の中には、複数の「カラムファミリー」があり、それぞれのカラムファミリーの中には、複数の「カラム」があります。したがって、行を特定する「Row Key」に加えて、カラムファミリー名、および、カラム名を指定すると、1つのデータにたどり着きます。Row Key、カラムファミリー名、カラム名、そして、保存データはすべて文字列として取り扱われます。数値やバイナリデータを保存する場合は、クライアント側で事前に文字列にエンコードしておきます。
図1は、論文で紹介されているテーブル構造の例です。これは、検索エンジンのクローラーが、インターネット上の各種Webサイトから取得したHTMLファイルをBigtableに保存する例です。Row Keyは、WebサイトのURLで、カラムファミリー「contents」には、HTMLファイルが保存されています。一般には、1つのカラムファミリー内に複数のカラムが用意されますが、ここでは、無名のカラムを1つだけ使用しています。また、カラムファミリー「anchor」には、このURLに対してリンクを貼っている他のWebサイトの情報が保存されます。カラム名は、リンクを貼っている他のWebサイトのURLで、カラム内のデータは、リンク部分の文字列です。
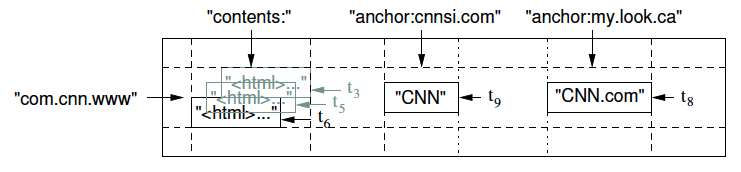
図1 Bigtableのテーブル構造(論文より抜粋)
Bigtableでは、Row Keyで指定した行内において、特定の条件を満たすデータを検索することが可能です。ただし、複数の行にまたがった検索はできません。つまり、テーブル全体から、特定の条件を満たすデータを検索するといった処理はできません。これでは、とても「データベース」とは呼べないと思う知れませんが、Bigtableの場合、1つの行が1つの「小さなデータベース」になっていると考えるとよいでしょう。特に、カラムファミリーはテーブル作成時に指定する必要がありますが、カラムファミリー内のカラムは、データ保存時に動的に追加することが可能です。この点がBigtableを活用する際のポイントになります。(カラムファミリーを後から追加することも可能ですが、テーブル作成時に確定させる使い方が基本となります。)
たとえば、論文の中では、他の例として、「Personalized Searchサービス」での使用例が紹介されています。これは、ユーザーのプロファイル情報や過去の検索履歴に基づいて、検索結果をカスタマイズするサービスです。図2のように、1つの行に1つのユーザーの情報を保存するようになっており、ユーザーIDをRow Keyに指定することで、該当ユーザーの行が特定されます。さらに、プロファイル情報を保存するカラムファミリーと検索履歴を保存するカラムファミリーがあります。検索履歴については、ユーザーが検索を行う度に新しいカラムが追加されていきます。なお、具体的なカラムファミリー名やカラム名については、論文には記載されていません。図2では、例として、単純な通し番号を検索履歴のカラム名に採用していますが、これは筆者の想像によるものです。
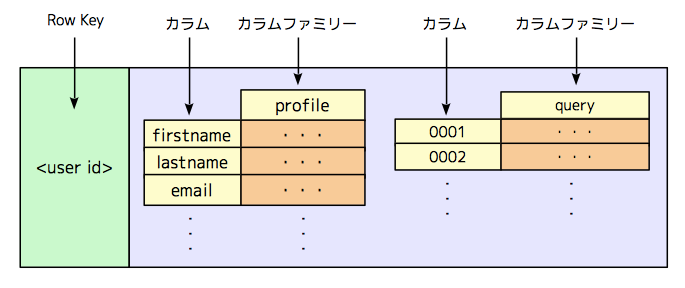
図2 Bigtableの行の設計例
複数行にまたがる処理として、唯一可能なのは、Row Keyの範囲を指定して、該当範囲の行のデータを順番に取り出す処理になります。さきほどの図1の例では、Row Keyとして、WebサイトのURLが使用されていますが、この際、「com.example.www/inde.html」のようにサイト名部分(www.example.com)を逆順にしています。これにより、文字列の前方一致を用いて、「com.example.a*」(「*」は任意の文字列)といった、範囲指定でのデータ取得が可能になります。テーブル内の各行は、Row Keyの文字列に対して、辞書順にソートされていると考えてください。
また、Bigtableに格納されるデータには、タイムスタンプの情報が付与されており、カラム内のデータをアップデートした場合でも過去のデータが削除されることはありません。クライアントは、タイムスタンプを用いて、過去のデータを参照することも可能です。古いデータについては、世代数指定、もしくは、期限指定で自動削除することができます。図1の例では、「t3, t5, t6」などが、タイムスタンプの情報を表します。
続いて、Bigtableの内部の仕組みへと話を進めましょう。Bigtableを構成するサーバーの全体像を示すと図3のようになります。
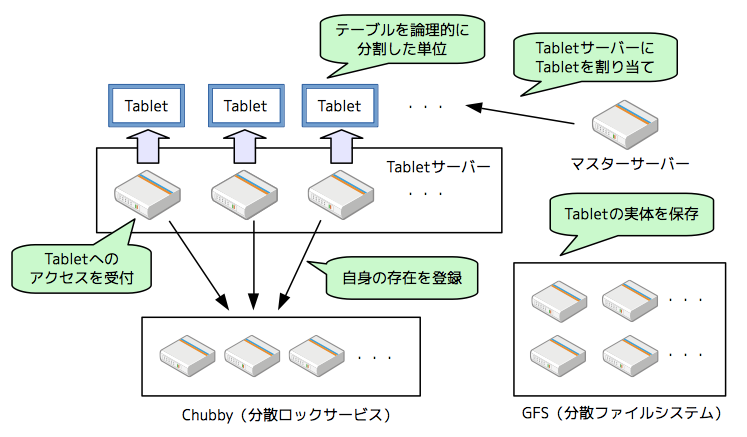
図3 Bigtableを構成するサーバー群
Bigtableが提供する1つのテーブルは、内部的に複数の「Tablet」に分割されており、各Tabletは、複数あるTabletサーバーのどれか1つに割り当てられます。(1つのTabletサーバーが複数のTabletを担当することも可能です。)Bigtableを使用するクライアントは、テーブル内のアクセス対象の行を含むTabletを特定した後、該当のTabletが割り当てられたTabletサーバーにアクセスを行います。この際、Tabletに含まれるデータの実体は、Tabletサーバーのメモリー上にある「memtable」と、バックエンドのGFS(Google File System)に保存された「SSTable」から構成されます。
GFSは、分散型の共有ファイルシステムで、Tabletサーバーはネットワーク経由でGFSにアクセスを行います。Tabletサーバーが障害などで停止した場合、該当のTabletは他のTabletサーバーに再割り当てが行われます。新しく割り当てられたTabletサーバーは、GFS上のファイルを利用してmemtableの内容をメモリー上に再構成できるようになっており、Tabletサーバーの障害でデータが失われることはなく、クライアントはテーブルへのアクセスを継続することが可能です。第3回、第4回に解説したように、GFS自体もデータの冗長性を確保する設計となっており、GFSを構成するサーバーの障害でデータが失われることもありません。
稼働中のTabletサーバーは、分散ロックサービスを提供する「Chubby」に自身の存在を登録するようになっており、マスターサーバーは、この情報を用いて、Tabletサーバーに対するTabletの割り当て処理を行います。Chubbyもまた複数サーバーによる分散アーキテクチャーを採用しており、単一障害点を排除した構成となっています。
今回紹介した全体像から、Bigtableの動作原理が想像できてきたと思いますが、インフラ技術に興味がある読者の方は、まだ、さまざまな疑問を感じているに違いありません。例えば、次のような点はどうでしょうか?
(1) クライアントは、アクセス対象の行を含むTablet、および、該当のTabletを担当するTabletサーバーをどのようにして発見するのか?
(2) マスターサーバーは、Tabletサーバーの障害をどのように検知して、Tabletの再割り当てを行うのか?
(3) Tabletの実体は、「memtable」と「SSTable」によってどのように構成されているのか?
特に、(3)に関連するポイントとして、大量データへのアクセスに高い性能を発揮する上では、物理的なファイルアクセスによるボトルネックを回避することはとても重要です。GFSは、シーケンシャルな読み込み、あるいは、追記処理に対して高い性能を発揮するという特徴がありましたが、memtableとSSTableでは、このような特徴を活かした設計がなされています。次回は、(1)〜(3)について、より詳細な解説を行います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































