
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Orion: Google's Software-Defined Networking Control Plane」に基づいて、Googleのデータセンターに導入された分散型のSDNコントローラー「Orion」を紹介していきます。今回は、Orionの設計ポリシー、そして、Jupiterとの関係を解説します。
前回の記事では、Orionの特徴として、NIBを用いたインテントベースの管理システムであることを説明しました。冒頭の論文では、この他には、次のような設計上の特徴が紹介されています。
(1) 接続が失われたスイッチに対する楽観的制御
(2) コントロールプレーンと障害ドメインの対応
(3) インバンド接続とアウトオブバンド接続の利用
これらは、いずれもSDNシステムに固有の考慮点に関係しています。SDNシステムでは、SDNコントローラーが複数のネットワーク機器を集中管理しますが、コントローラーとネットワーク機器の接続が切れた場合、あるいは、コントローラー自体が障害で停止した場合など、SDNに固有の障害モードがあり、このような障害への対応方法を考えておく必要があります。たとえば、(1)は、一部のネットワークスイッチの情報がコントローラーに到達しなくなった場合、すなわち、コントローラーから見た時にスイッチが正常に稼働しているかどうかがわからなくなった場合の対応方法を示します。Orionのコントローラーは、管理対象のスイッチ全体の状況を見て、Fail Closed、もしくは、Fail Staticと呼ばれる対応を取ります。
Fail Closedは、現在の状態がわからないスイッチは、障害で停止しているものと判断して、該当のスイッチを利用しないようにネットワーク経路を変更します。一方、Fail Staticは、該当のスイッチは、コントローラーとの通信ができないだけで、ネットワークパケットは正常に処理し続けていると考えて、ネットワーク経路は変更せずに現状のままで様子を見るという対応を取ります。Fail ClosedとFail Staticのどちらの対応を取るべきかは、さまざまな判断方法が考えられますが、経験的には、Fail Staicの対応で問題ない場合が多いため、Orionのコントローラーは残存するネットワークキャパシティに応じた対応を取ります。
たとえば、図1の左の図は、すべてのスイッチが正常に稼働している状態を表しており、すべてのスイッチをネットワークパケットが通過しています。この状態において、中段にある2つのスイッチの状態がわからなくなったとします。この場合、中段にはまだ2つのスイッチが残っていますので、Fail Closedの対応を取り、状態がわからないスイッチを回避するようにネットワーク経路を変更します(図1の中央の図)。そして、ここからさらに、中段の残り2つのスイッチの状態がわからなくなったとします。この場合、これらのスイッチを回避すると、利用できるネットワーク経路がなくなってしまいます。そこで、Orionのコントローラーは、Fail Staticの対応を取り、ネットワーク経路を現状のままに保ちます。
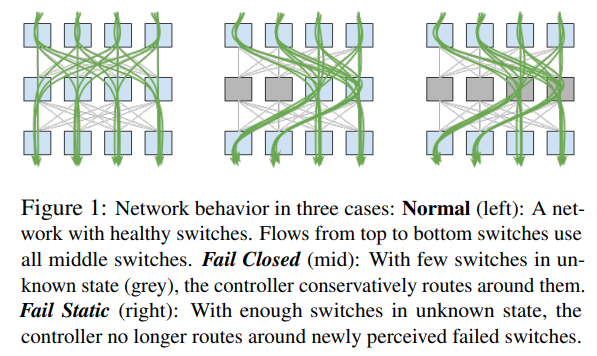
図1 Fail ClosedとFail Static(論文より抜粋)
これは、比較的単純な例ですが、実際には、今後予定されている計画停止時にも必要なネットワークキャパシティが確保できるか、あるいは、ネットワークシステムに要求される冗長性が確保できているかなど、ネットワーク経路全体のトポロジーを考慮して総合的な判断を行います。
前述の(2)(3)については、OrionによるJupiterの制御方法を例として説明します。Jupiterは、データセンター内のサーバークラスターを相互接続するローカルネットワークシステムで、図2のような構成になっています。図の最下段にあるAggregation blockは複数のサーバーラックを相互接続するスイッチ群で、さらに、上段にあるSpineと呼ばれるスイッチ群で複数のAggregation blockを相互接続します。この図では、左端のSpineのみがAggregation blockに接続されていますが、実際には、これと同様に、すべてのSpineがAggregation blockに接続されており、Aggregation block同士は、複数のSpineを経由して通信することができます。これにより、複数のSpineを経由した負荷分散と、Spineの障害停止に対する冗長性を確保しています。
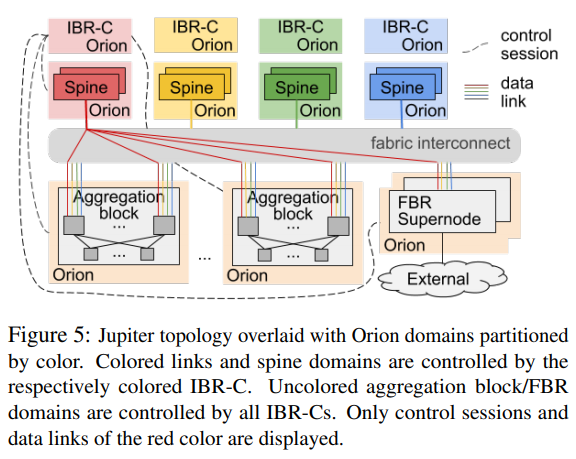
図2 Jupiterの全体構成、および、Orionとの関係(論文より抜粋)
それでは、これらのスイッチ群をOrionはどのように管理しているのでしょうか? 理屈の上では、単一のOrionコントローラーですべてを統合管理することもできますが、その場合、Orionコントローラーの障害により、これらのスイッチ群全体が停止する危険性があります。そこで、図2に示したように、Jupiterを構成するコンポーネントごとにOrionコントローラーを配置するという構成が取られています。これが前述の(2)に対応します。
具体的には、それぞれのAggregation blockを個別に管理するOrionコントローラーがあり、さらに、Spine全体を4つのグループに分割して、それぞれのグループごとにOrionコントローラーを配置します。これらのコントローラーは、自身が管理するAggregation block内、もしくは、Spine内のスイッチの構成を管理します。さらに、これらの上位に位置するIBR-C(Inter-Block Routing Central)と呼ばれるOrionコントローラーがあり、SpineとAggregation Blockの間のルーティングを制御します。IBR-Cもまた、Spineのグループごとに用意されています。
これはちょうど、Jupiterの障害ドメイン(障害により同時に停止する可能性が高い範囲)ごとにOrionのコントローラーが配置された形になっており、Jupiterの耐障害性を活かした設計と言えます。たとえば、Spineの特定グループを管理するOrionコントローラーが停止した場合でも、他のSpineのグループには影響を与えないため、Aggregation block間の接続が失われることはありません。
最後の(3)は、Orionコントローラーと管理対象のネットワーク機器を接続する経路に関する設計方針です。SDNシステムでは、通常、ネットワーク機器が本来処理すべきデータが流れるデータプレーンとは別に、コントローラーとの通信専用のネットワークであるコントロールプレーンを用意します。Orionでも、基本的には、コントロールプレーンを使用しますが、一部、例外があります。Jupiterが管理するネットワークスイッチには、個々のサーバーラックに搭載されたToR(Top of Rack Switch)が含まれます。ToRを専用のコントロールプレーンで管理するには、すべてのサーバーラックに追加のネットワーク配線が必要になりますが、サーバーラックの台数を考慮すると、相応の追加投資と物理配線の管理コストが発生します。そこで、ToRについては、例外的に、データプレーンを経由して管理する構成が用いられています。
今回は、2021年に公開された論文「Orion: Google's Software-Defined Networking Control Plane」に基づいて、分散型のSDNコントローラー「Orion」の設計ポリシー、および、Jupiterへの適用例を紹介しました。次回は、B4ネットワークへの適用例を説明した上で、論文内に示されている性能データを紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































