
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Orion: Google's Software-Defined Networking Control Plane」に基づいて、Googleのデータセンターに導入された分散型のSDNコントローラー「Orion」を紹介していきます。今回は、グローバルネットワークシステムであるB4ネットワークへのOrionの適用例、そして、Orionの性能データを紹介します。
前回の記事で説明したように、Googleのデータセンター内には、Jupiterと呼ばれるローカルネットワークシステムがあります。そして、世界各地のデータセンターのローカルネットワークは、B4ネットワークと呼ばれるグローバルネットワークで相互接続されています。より具体的には、各サイトにあるFBR(Fabric Border Router)と呼ばれるルーターシステムがB4により相互接続されており、FBRの配下にJupiterのローカルネットワークシステムが接続される形になります。FBRは、OpenFlowで制御される複数のスイッチが連携してBGPルーターの機能を提供しており、内部的にパケットの負荷分散と経路の冗長化が行われます。FBRはSupernodeと呼ばれる単位でグループ化されており、前回の記事の図2にある「FBR Supernode」がちょうどこれにあたります。このSupernodeごとに、これを制御するOrionのコントローラーが配置されています。
Orionを通じてデータセンター間の通信経路を制御する仕組みは、図1のようになります。図の中央にある「Routing Engine」は、前々回の記事で説明したように、Orionを通じてスイッチ間のルーティングを制御するサービスですが、ここには、さらにその上位のさまざまなサービスがあります。特に、図の上部にあるCentral TE ServerとBandwidth Enforcerが、アプリケーションごとの通信経路を制御する「Traffic Engineering」の機能を提供するシステムになります。
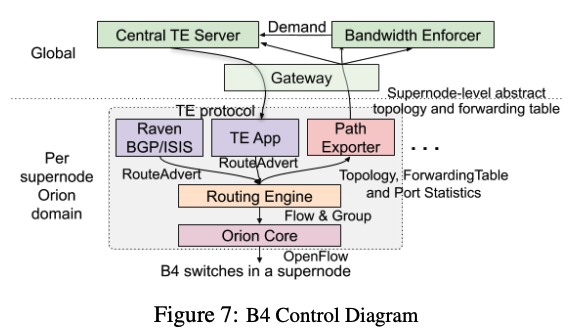
図1 OrionによるB4のルーティング制御(論文より抜粋)
まず、それぞれのSupernodeは、Path Exporterを通じて、自身の稼働状態や他のSupernodeとの接続状態、あるいは、サイト間のグローバルなネットワーク経路といった情報をBandwidth EnforcerとCentral TE Serverに通知します。これにより、Bandwidth EnforcerとCentral TE Serverは、B4を構成するネットワーク全体の状況(トポロジー)を把握することができます。次に、Bandwidth Enforcerは、B4で通信を行うさまざまなアプリケーションに対して、それぞれの優先順位に応じたネットワーク帯域の割り当てを行います。より正確に言うと、第17回の記事で解説したように、アプリケーションを「フローグループ」と呼ばれるグループに分けて、フローグループごとに帯域の割り当てをおこないます。
最後に、Central TE Serverは、割り当てられた帯域に応じて、実際の通信経路を決定します。例えば、サイトAからサイトBに通信を行う場合、AからBに直接にパケットを転送する以外にも、サイトCを経由して、A→C→Bと転送するなど複数のパターンが考えられます。Central TE Serverは、このようなさまざまなパターンを考慮して、それぞれのフローグループについて、要求された帯域を確保するための最適な経路の組み合わせを見つけ出します。Central TE Serverが決定した経路は、図1のTE Appを通じてOrionに伝えられた後、Orionによって実際の経路の割り当てが行われます。A→B、A→C→Bといった個別の経路は、オーバーレイ方式(IP Encapsulation)のトンネルとして定義されており、フローグループごとに使用するトンネルを使い分けるための設定がなされます。
サイト間の接続に問題が起きてトンネルを通じた通信ができなくなった場合、TE Appは、一時的に代替のトンネルを使用するか、もしくは、トンネルを使用しない、BGPによるデフォルトの経路に通信経路を切り替えます。その後、Central TE Serverによる最適な経路の再計算が行われます。このように、Orionによるローカルの制御とCentral TE Serverによるグローバルな制御を組み合わせる事で、全体的な経路の最適化と障害発生時の迅速な復旧を両立させていることがわかります。
冒頭の論文では、Orionの性能に関するいくつかのデータが公開されています。ここでは、Jupiterの障害発生時に経路を回復するまでにかかる時間のデータを紹介します。図2の左の2つのグラフは、Jupiterを構成するスイッチ(ノード)が停止した場合、および、スイッチが持つポートの1つが停止した場合のデータです。ノード、および、ポート障害が発生した場合、それぞれのスイッチは自発的に代替経路に切り替えて、その後、Orionのコントローラーがその状況を認識するという流れになります。図の棒グラフは、代替経路への切り替えが完了するまでの時間で、折れ線グラフは、コントローラーがそれを認識するまでの時間になります。Jupiterのクラスターサイズ(クラスターに含まれるスイッチのノード数)によって変化しますが、いずれの場合も1秒以下の時間で経路が回復しています。
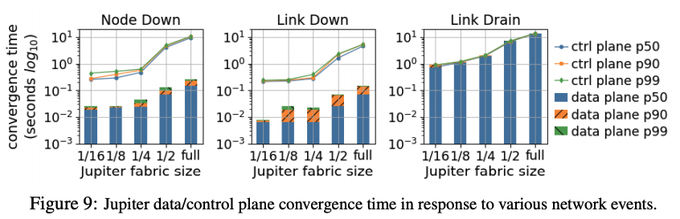
図2 Jupiterにおける経路の回復にかかる時間(論文より抜粋)
図2の一番右のグラフは、障害ではなく、Orionのコントローラーの指示により、特定のポートの使用を停止した場合の結果です。この場合、それぞれのスイッチはコントローラーの指示にしたがって通信経路を変更するので、経路変更が終わるまでの時間(棒グラフ)とコントローラーがそれを認識するまでの時間(折れ線グラフ)は同一になります。障害に伴う経路変更ではないので、特別に急いで処理を完了する必要はありませんが、1〜10秒程度で処理が完了しており、ノード障害/ポート障害に伴う経路変更を認識するまでの処理時間とほぼ同じになります。Orionは、ソフトウェアでネットワークを制御するというSDNの特徴を活かして、ソフトウェアのアップデートによる継続的な性能改善が行われており、図2に示した経路変更の認識時間については、2018年から2020年の間に、10〜40倍の高速化を実現したという事です。
この他には、Orionのコントローラーが使用するCPU/メモリー容量についてもデータが公開されています。Orionは、複数のサービスが連携する分散システムとして実装されていますが、実測値としては、1つのコントローラーを構成するサービス全体として、23CPUコアと24GBのメモリーがあれば十分だという事です。
今回は、2021年に公開された論文「Orion: Google's Software-Defined Networking Control Plane」に基づいて、B4ネットワークへのOrionの適用例とOrionの性能データを紹介しました。次回は、新しい話題として、Googleのデータセンターで稼働するLinuxに独自実装されたメモリー圧縮機能を解説したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































