
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2019年に公開された論文「Software-defined far memory in warehouse-scale computers」に基づいて、Googleのサーバークラスターで用いられる独自のメモリー圧縮機能について解説していきます。Linuxカーネルのzswapと呼ばれる機能を拡張したものですが、論文のタイトルにあるように、「far memory」と呼ばれるメモリーアーキテクチャーをソフトウェアで独自に実装したものになります。
第32回からの記事で紹介したように、Googleのデータセンターでは、Borgと呼ばれるコンテナ管理システムを利用しており、大規模なサーバークラスター上で、さまざまなワークロードをコンテナを用いて実行しています。1つのクラスターには1万台以上のサーバーが含まれることもあり、このような環境では、サーバーに搭載する物理メモリーのコスト削減も課題の1つとなります。特に最近では、大規模なデータ処理をオンメモリーで実施するなど、大容量のメモリーを要求するワークロードが増加しており、サーバー上で稼働する多数のコンテナに対して、効率的にメモリーを割り当てることが重要になります。
その一方で、最近、「far memory」と呼ばれるメモリーアーキテクチャーが話題になることがあります。これは、メインメモリーとストレージの間に、不揮発メモリーなどを用いた新たな記憶レイヤー(far memory)を配置するものです。メインメモリー上の長期間アクセスされていないデータを「far memory」に移動することで、メインメモリーをより効率的に利用しようというものです。しかしながら、既存の不揮発メモリーを用いた仕組みの場合、専用の機能を持った新しいCPUを必要とする、あるいは、既存のCPUでも利用できるものはアクセス速度が遅くてアプリケーションへの影響が大きいといった課題があり、Googleのデータセンターでの採用は難しい状況でした。
その他には、各サーバーに搭載する不揮発メモリーの容量をどのようにして決めるのか、という問題もあります。Googleのエンジニアが実際のサーバー上のメモリー使用状況を調べたところ、長期間アクセスされないデータの割合はサーバーによって大きな幅があり、最適な「far memory」の容量はサーバーごとに大きく異なります。同一容量の不揮発メモリーを一律に搭載した場合、実際には使用されない不揮発メモリーが発生して、コスト削減の観点では、逆効果になる可能性もあります。
上記のような課題に対して、Googleのエンジニアは、不揮発メモリーなどの新しいハードウェアを導入するのではなく、長期間アクセスされていないデータをメモリー上で圧縮することにより、利用可能なメインメモリーを増加するという解決策を導入しました。サーバー上で稼働するエージェントが、圧縮対象とするメモリー領域を動的に選択することで、アプリケーションの実行速度に対する影響を抑えながら、かつ、far memoryとして使用するメモリー容量をサーバーごとに自由に調整することができます。結果としては、長期間アクセスされないメモリーの20〜30%を圧縮処理の対象とすることで、物理メモリーにかかる費用の4〜5%を削減することに成功したそうです。論文内には、『サーバークラスターの規模を考慮すると「millions of dollars」のコスト削減に成功した』との記述があります。
上記の仕組みを実装するにあたって重要になるのが、圧縮対象とするデータの範囲です。「長期間アクセスされていないデータ」を圧縮対象にすると言っても、具体的に何秒間アクセスがなかったものを対象とするかを決める必要があります。この時間を短くすると、圧縮対象のデータが増えて、メモリーの利用効率は上がります。しかしながら、その後、圧縮したデータにアプリケーションからのアクセスが発生すると、これを解凍して取得するための処理(プロモーション)が必要になるため、アプリケーションの処理速度が低下します。そのため、圧縮対象のデータ量と、それにともなうプロモーションの発生頻度のバランスを取る必要があります。
そこで、Googleのエンジニアは、Borgのクラスターで稼働するLinuxカーネルに対して、メモリーへのアクセス状況のデータを取得する機能を実装した上で、実環境のデータを取得・分析しました。まず、図1は、複数のサーバークラスターからのデータを平均したものになります。
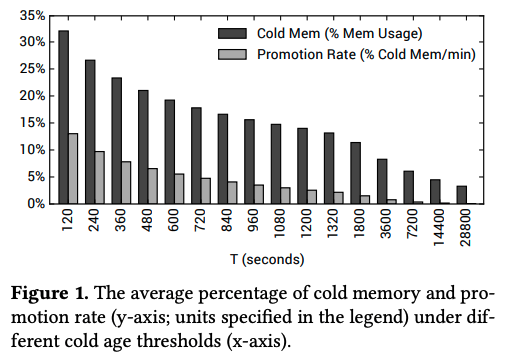
図1 コールドデータとプロモーションレートの関係(論文より抜粋)
これは、特定の時間T(秒)を設定した際に、ある瞬間において、メモリー上で、過去T秒間アクセスがなかったデータ(すなわち、圧縮対象となるデータ)の割合と、それらのデータの中で、その後1分以内にアクセスが発生したデータの割合を示します。例えば、T=120(秒)に設定した場合、約32%のメモリーが圧縮対象になる一方、その中の約13%に対して、1分以内にアクセスが発生するという結果になります。ここでは、圧縮対象となるデータを「コールドデータ」、そして、1分以内にアクセスが発生する割合を「プロモーションレート」と呼びます。Googleの環境では、アプリケーションの処理速度の低下を抑えることが重要になるため、単純に考えれば、このグラフを見て、プロモーションレートが許容範囲の値になる最小のTを選べばよいことになります。
ただし、図1のグラフは多数のサーバーに対する長時間にわたる測定値の平均を表したものですので、これだけを見て判断することはできません。実際には、サーバーごと、あるいは、アプリケーションの種類ごとにプロモーションレートの値が変化します。例えば、図2は、複数のサーバークラスターにおいて、コールドデータの割合がサーバーごとにどのぐらい変化するかを示したものになります。例えば、クラスターC1では、コールドデータが30%程度のサーバーが最も多いことになりますが、全体としては10〜55%程度の範囲に分布が広がっています。
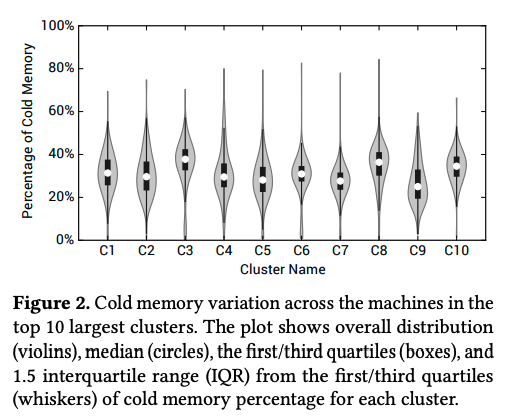
図2 クラスターごとのコールドデータの分布(論文より抜粋)
このように、いずれのクラスターにおいても、コールドデータの割合はサーバーによって大きく異なることがわかります。これは、サーバー上で稼働するアプリケーションの特性がまちまちであることを示唆しており、具体的なデータはありませんが、プロモーションレートについても、アプリケーションごとに異なる特性があるものと推察できます。そこで、Googleのエンジニアは、このようなメモリーの使用状況を監視するエージェントをサーバー上で稼働しておき、アプリケーション(コンテナ)ごとの特性に応じて、圧縮対象を決める時間Tを動的に決定する仕組みを実装しました。
今回は、2019年に公開された論文「Software-defined far memory in warehouse-scale computers」に基づいて、Googleのサーバークラスターで用いられる独自のメモリー圧縮機能について、それが求められる背景や実装方法の検討材料となる実データを紹介しました。次回は、より具体的な実装の内容を解説していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































