
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2015年に公開された論文「Large-scale cluster management at Google with Borg」をもとにして、Googleのクラスター管理システム「Borg」を紹介します。論文にも記載があるように、サーチエンジンやGmailなどのエンドユーザー向けアプリケーションに始まり、Bigtableなどのミドルウェア、そして、数秒から数日間にわたる様々な長さのバッチジョブと言った、広範なワークロードがBorgの上で実行されており、Googleのデータセンターにおけるアプリケーション実行基盤の標準環境とも言えるシステムです。今回は、主に、利用者から見たBorgの機能や特徴を紹介します。
先ほどの論文の冒頭では、Borgが提供するメリットとして、次の3つがあげられています。
Borgを利用する主なユーザーは、アプリケーションを開発・デプロイするソフトウェアエンジニアですので、そういった利用者の視点では、上記の機能をBorgに委ねることで、アプリケーションの機能面での開発にフォーカスできることが主要なメリットと言えるでしょう。Borgの利用者は、「ジョブ」という単位でBorg上での処理を行います。それぞれのジョブは、同一の実行バイナリーを用いて、複数の「タスク」を起動します。ここでは、同一の処理を行うタスクを複数起動することで、スケールアウト型の並列処理を行うことが基本的な考え方となります。個々のタスクは、Linuxコンテナで隔離されたプロセス群に対応します。
Borgにジョブを投入する際は、タスクの実行数や個々のタスクに割り当てるリソースを宣言型の言語で記述します。CPUコアの数、メモリー容量、ローカルディスクサイズ、I/O性能要求などの他に、CPUアーキテクチャーを明示的に指定することも可能で、その場合は、該当のCPUを搭載したサーバーにタスクの実行が割り当てられます。また、実行中のジョブ/タスクに対する動的な設定変更も可能で、実行に使用するバイナリーファイルを入れ替えることもできます。リソース割り当てを変更した場合は、必要な際は、タスクの再配置なども自動で行われますが、再起動が発生するタスク数に上限を設けるなどの指定もできます。
ここでは、Borgのシステム構成の概要を紹介します。図1は、論文に記載された概要図ですが、Borgの環境は、「Cell(セル)」と呼ばれる単位で構築されます。Googleのデータセンター内には、複数のサーバーを束ねたクラスターが用意されており、通常、1つのクラスターに1つのセルが構築されます。論文の中では、典型的には、1つのセルは1万台程度のサーバーによって構成されると説明されています。場合によっては、1つのクラスター内にテスト用の小さなセルが同居することもあるそうです。セルを構成するサーバー群のCPUやメモリー容量などは、均一にはなっていませんが、タスクを配置するサーバーは、Borgが自動的に決定するため、基本的には、利用者が個々のサーバーの違いを意識することはありません。
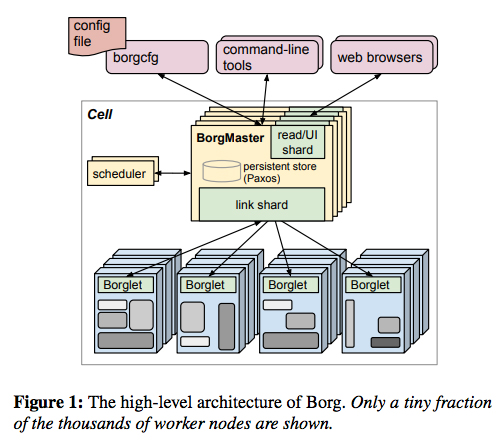
図1 Borgのシステム構成の概要図(論文より抜粋)
それぞれのジョブには、整数値で表された優先度が設定されており、タスクに対するリソースの割り当ては、この優先度に従って行われます。さらに、これらの優先度は、大きく、「monitoring」「production」「batch」「best-effort」という4種類に分類されており、「batch」と「best-effort」に含まれるタスクは、より優先度の高いタスクによって、強制停止させられることもあります。強制停止が行われたタスクは、ほとんどの場合、セル内の他のサーバーに再配置されるため、再実行可能なバッチジョブであれば、このような動作は問題にはなりません。論文の中では、バッチジョブのタスクの中でも、MapReduceのマスタータスクは、ワーカータスクよりも高い優先度を割り当てるなどのテクニックも紹介されています。
同じジョブに属するタスクは、そのジョブが投入されたセル内のサーバーに分散配置されます。それぞれのタスクには、BNS(Borg name service)によるユニークなタスク名、および、通常のDNSによるFQDN(Fully Qualified Domain Name)が動的に割り当てられて、外部のシステムから参照可能になります。特に、Googleの内部で利用されているRPCライブラリを用いたアプリケーションからは、BNSによる透過的なアクセスが可能になります。
また、それぞれのタスクは、組み込みのHTTPサーバーによって、ヘルスチェック用のアクセスポイントを提供すると共に、数千項目におよぶ性能情報(RPCのレイテンシーなど)を公開しています。Borgのモニタリングシステムは、ヘルスチェック用のURLに定期的にアクセスして、正常な応答が得られない場合は、タスクの再起動処理を行います。その他の性能情報は、外部のモニタリングツールによって収集されて、ダッシュボードへの表示、あるいは、しきい値設定によるアラートの発行などに利用されます。
今回は、論文「Large-scale cluster management at Google with Borg」をもとにして、Googleのデータセンターにおけるアプリケーション実行基盤の標準環境である「Borg」について、利用者から見た際の機能や特徴を紹介しました。次回は、Borgのアーキテクチャー、および、論文に記載されている各種の統計データを紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































