
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2013年に公開された論文「Does Bug Prediction Support Human Developers? Findings from a Google Case Study」をもとにして、「バグ予測アルゴリズム」の実効性に関するレポートを紹介します。学術的に評価の高いアルゴリズムである「FixCache」、そして、よりシンプルで直感的な「Rahmanアルゴリズム」の2種類を取り上げて、これらの有効性や実用化に向けた課題を検証することがレポートの目的となります。
前回説明したように、これらのアルゴリズムを実際のプロジェクトに適用するに先立って、アルゴリズムの有効性について、ソフトウェア開発者に対するインタビュー調査が行われました。2つの開発プロジェクトを選定して、3種類のアルゴリズムが選びだした「バグを含む可能性が高いファイル一覧(上位20ファイル)」を実際の開発メンバーに評価してもらうというものです。対象となるアルゴリズムは、「一覧サイズを制限したFixCache(Cache-20)」「変更数でランクづけしたFixCahce(Duration Cache)」「Rahmanアルゴリズム」の3種類です。(それぞれの違いについては、前回の記事を参照してください。)
インタビュー対象となったのは、さまざまな経験年数を持つ19名の開発者で、各ファイルについて、実際に開発に関わっている知見に基いて、「Bug-prone(バグを含む可能性が高い)」「Not bug-prone(バグを含む可能性は低い)」「Unknown(わからない)」というラベル付けを行います。その結果を集計したものが図1のグラフになります。
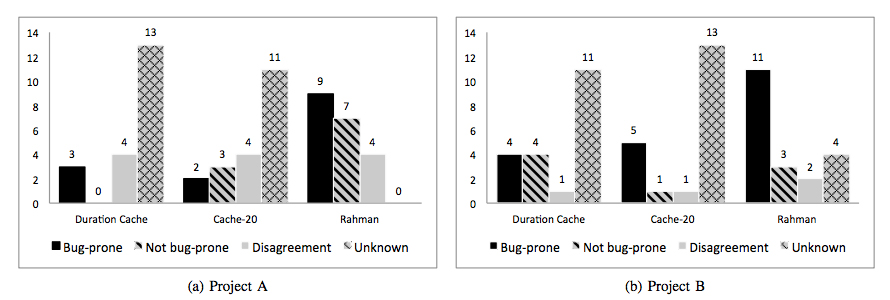
図1 ファイルに対する開発者の判断結果(論文より抜粋)
グラフ上では4種類に結果が分類されていますが、それぞれが表わす意味は次になります。
この結果を見ると、「Bug-prone」の比率が最も高いのは、Rahmanアルゴリズムで、その他の2つは、「Unknown」の比率が高いことがわかります。この結果について、開発者からのコメントには、次のようなものがあったそうです。まず、Cache-20については、実装に関する実験を行ったコードのプロトタイプ宣言など、本番システムのバグに影響しないファイルが含まれており、ファイルの選択に一貫性が感じられないという事です。こういった無関係なファイルを選定対象外にする方法も考えられますが、少なくとも、今回のアルゴリズムにはそのような処理は入っていませんでした。
また、Duration Cacheが選定したファイルには、非常に古いファイルで、その内容に関する知見が開発者の記憶に残っていないものが多かったという事です。これは、必ずしもバグを含まないという意味にはなりませんが、少なくとも、最近は、開発者の記憶に残るような変更がなかったファイルということになります。一方、Rahmanアルゴリズムが選定したファイルについては、古いファイルでありながら、開発者からは、「モノリシック」「依存関係が複雑」「メンテナンスが困難」などのコメントが与えられており、単純に古いことだけが「Unknown」と評価される要因ではなさそうだと推測されます。
そして、これら3つのアルゴリズムに対する開発者からの最終評価は、図2のようになります。それぞれの開発者は、3つのアルゴリズムに対して、「Most bug-prone」「Middle bug-prone」「Least bug-prone」というランク付けを行い、その結果を集計したものになります。縦軸の値は、該当の評価を与えた開発者の数になります。
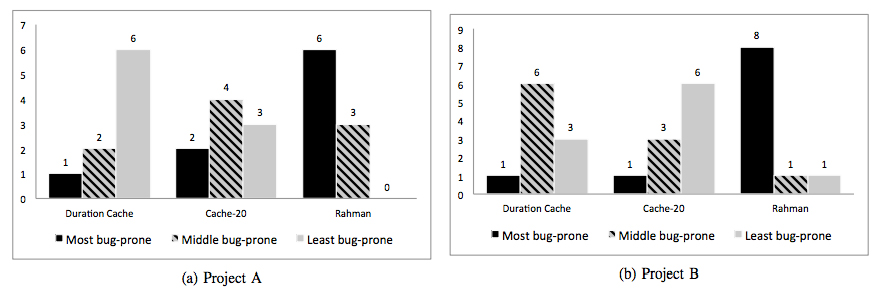
図2 アルゴリズムに対する開発者の評価結果(論文より抜粋)
結論としては、Rahmanアルゴリズムの評価が最も高く、これが、開発者の経験による判断と最もよく一致するアルゴリズムだということになります。
続いて、インタビュー調査の結果、最も評価がよかったRahmanアルゴリズムを実プロジェクトに適用するという実験が行われました。ただし、これは、特定のプロジェクトに対して適用するというわけではありません。第20回の記事で紹介したように、Googleでは、すべてのプロジェクトのソースコードは単一のリポジトリで管理されており、複数のプロジェクトにまたがってソースコードの分析・調査ができるようになっています。そこで、リポジトリ内の全ファイルにRahmanアルゴリズムを適用して、バグを含む可能性が高い、上位0.5%のファイルを選び出します。この処理は、夜間バッチによって、毎晩行われます。その後、社内標準のコードレビューシステム上で、該当ファイルに対する変更のレビューが発生すると、「このファイルは、バグ予測アルゴリズムによってバグを含む可能性が高いと判断されたので、より注意深くレビューしてください」という意味の警告メッセージを表示するようにしました。
その3ヶ月後、該当ファイルに対するレビュー時間、そして、本番環境で発生したバグチケット数にどのような変化が現れるかを検証しました。しかしながら残念なことに、結論としては、この仕組みを導入したことによる明確な変化は見られなかったということです。そこで、その理由を探るために、コードレビューに関わった開発者からのフィードバックを分析して、彼らの行動に変化を起こすには、何が不足していたのかを確認しました。
開発者からのフィードバック調査の中で確認された問題点には、次のようなものがありました。まず、前述のメッセージに対して、具体的に何をすればよいのかがわからず、変更を登録した開発者、そして、変更のレビュアーの双方で混乱が発生したという点です。つまり、バグの可能性を指摘するだけでは不十分で、具体的にどのような対応が必要なのかまで示さないと意味がないということです。そして、先のインタビュー調査で指摘された「古くからある、複雑でメンテナンスが困難なファイル」に対しては、何度も繰り返し警告が表示されること、あるいは、自動生成された設定ファイルや定義ファイルなど、そのファイル自体に問題の原因があるわけではないものにまで、警告が表示される場合があることです。このような事が続くと、開発者やレビュアーは、警告を重要なものとは思わなくなり、やがては、警告を無視するようになります。
これらをまとめると、バグ予測アルゴリズムによる警告メッセージが実用的な意味を持つには、なぜその警告が表示されたのかを示す具体的な理由、そして、具体的に必要となる対応の中身、これらをあわせて示す必要があるという事です。振り返ってみれば、lint系のソースコードチェッカーを始めとする、広く利用されているコード分析ツールは、確かにこれらの要件を満たしていることがわかります。また、この論文の中では、バグ予測アルゴリズムに求められる要件について、開発者に対するアンケート調査を行ったことも記載されています。その中でも、まさにこれらの点が多くの開発者から指摘されていたということです。
今回は、論文「Does Bug Prediction Support Human Developers? Findings from a Google Case Study」にもとづいて、バグ予測アルゴリズムの実効性に関する調査レポートを紹介しました。結論としては、バグを予測するだけでは不十分で、その原因や必要となるアクションまで示さなくてはならないことがわかりました。実はこの点は、最近よく話題となる、機械学習による予測処理にもあてはまります。機械学習のアルゴリズムが予測した内容がどれほど正確であったとしても、それを具体的なビジネス判断に結びつけることができなければ、実用的な意味は生まれません。予測内容と具体的なアクションを結びつけるビジネスプロセスの設計が大切だということです。
次回は、マイクロサービスに関わるGoogleのインフラ環境についての話題をお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































