
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2013年に公開された論文「Does Bug Prediction Support Human Developers? Findings from a Google Case Study」を紹介します。これは、いくつかの既存の「バグ予測アルゴリズム」をGoogle社内の開発プロセスに適用して、その有効性、あるいは、実用化に向けた課題を調査した際のレポートです。結論としては、この調査では、具体的なバグ低減への寄与は見られなかったということですが、それぞれのアルゴリズムの特性や実用化に向けた課題には興味深い点があります。今回から数回に分けて、これらの内容を紹介していきます。
冒頭の論文では、バグ予測のアルゴリズムについて、学術的な研究は盛んに行われているものの、現実のソフトウェア開発プロジェクトにおける有効性は十分に検証されていないという課題が指摘されています。そこで、学術的に評価の高いアルゴリズムである「FixCache」、そして、よりシンプルで直感的な「Rahmanアルゴリズム」の2種類を取り上げて、これらの有効性や実用化に向けた課題を検証することがレポートの目的としてあげられています。
FixCacheは、バグの存在の「局所性(locality)」を想定して、ファイル単位で「バグを含む可能性が高いソースファイル」を分類するアルゴリズムです。具体的には、リポジトリ内のすべてのファイルを定期的にチェックして、後述する条件を満たす場合、「バグを含む可能性が高いファイル一覧」に登録されます。この一覧に含まれるファイル数には上限があり、新しいファイルが登録されると、先に登録されたファイルから順に一覧から削除されます。登録済みのファイルが再登録された場合は、このタイミングで新しく登録されたものとして扱われるので、何度も再登録されるファイルは一覧に残り続けることになります(図1)。
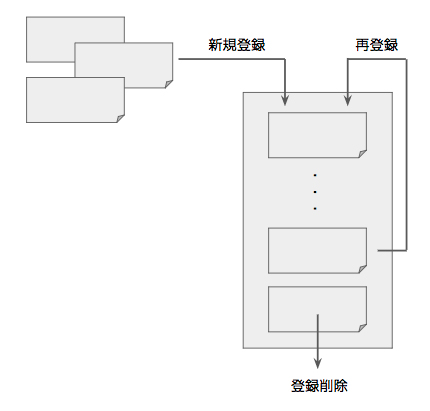
図1 FixCacheの一覧登録の仕組み
この一覧へ登録するかどうかの判定は、該当プロジェクトのバグトラッキングシステムから、このファイルに関連する既存のバグを参照することで行われます。具体的には、次の3つの条件を満たす場合に、一覧に登録されます。
2. と 3. が局所性に相当する部分で、端的に言うと、複数のバグは(何らかの理由で)関連して同時に発生することが多いので、既存のバグがあるファイルについては、新しい変更も何らかのバグを含む可能性が高いという考え方になります。ある意味シンプルな考え方ですが、オリジナルの論文「Predicting Faults from Cached History」では、高い予測性能を実現することが示されています。
もうひとつのRahmanアルゴリズムは、この考え方をよりシンプルに適用したもので、該当ファイルに対して修正済みのバグの数をカウントして、その数が多いほど、そのファイルが潜在的な(未修正の)バグを含む可能性が高いと判断するものです。この場合、古くから存在するファイルほどバグを含むと判定されやすくなりますので、このケーススタディでは、古いファイルほど評価を落とす(バグの可能性判定を下げる)ように重み付けをして適用しています。
これらのアルゴリズムを実際のプロジェクトに適用するに先立って、アルゴリズムの有効性と改善点について、ソフトウェア開発者に対するインタビュー調査が行われました。「アルゴリズムの有効性」については、2つの開発プロジェクトを選定して、上記のアルゴリズムが選びだした「バグを含む可能性が高いファイル一覧」を実際の開発メンバーに評価してもらうというものです。これは、ソフトウェア開発者が経験的に「危険」と感じる部分が、アルゴリズムによる選定とマッチするかどうかを確認する意味があります。選定された2つのプロジェクトの特徴は、図2の通りです。
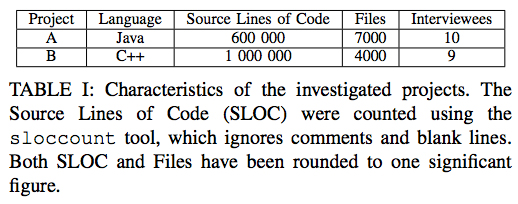
図2 インタビュー調査の対象プロジェクト(論文より抜粋)
論文によると、これらは、Google社内の開発プロジェクトとしては標準的なサイズということですが、数千以上のファイル数という点が、FixCacheの適用に問題を引き起こしました。FixCacheでは、全ファイル数の10%が「バグを含む可能性が高いファイル一覧」のサイズとして推奨されています。しかしながら、全ファイルが数千あると、一覧には数百のファイルが登録されます。実際のプロジェクトでこれだけのファイルに警告があがるとなると、すべてを入念にチェックするのは現実的ではなくなります。そこで、警告対象とするファイル数を20個に絞るために、2つの方法が提案されました。
1つは、一覧のサイズを単純に20ファイルに制限する方法です。ただし、この場合は、最近変更されたファイルが一覧に追加されることで、古いファイルが一覧から削除されるため、古いファイルに対するバグが無視される可能性が高くなります。もう1つの案は、一覧のサイズはそのままにして、一覧に含まれるファイルの中から、特に危険度の高いものを20個選び出すという方法です。この論文では、「一覧に登録されている期間中に行われた変更数」が多いものほど危険度が高いという判定法を採用しています。そして、これら3つのアルゴリズム(一覧サイズを制限したFixCache、変更数でランクづけしたFixCahce、Rahmanアルゴリズム)、それぞれによって選ばれた20個のファイルのリストについて、前述のインタビューが行われました。
もうひとつの「アルゴリズムの改善点」については、プロジェクトを特定せず、Google社内のソフトウェア開発者から広く意見を集めるという方法が取られました。
今回は、論文「Does Bug Prediction Support Human Developers? Findings from a Google Case Study」にもとづいて、FixCache、および、Rahmanアルゴリズムという2種類の「バグ予測アルゴリズム」、そして、これらのアルゴリズムに関するインタビュー調査について説明しました。lint系のソースコードチェッカーやFindBugsなどの静的なコード分析のツールは、Google社内でも標準的に利用されていますが、今回紹介したアルゴリズムは、バグトラッキングシステムと連携して動的な予測を行うという特徴があります。
次回は、インタビュー調査の結果、そして、インタビュー調査で高評価を得たアルゴリズムを実際のコードレビュープロセスに適用した結果などを紹介していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































