
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、前回に引き続き、2017年に公開された論文「Taking the Edge off with Espresso: Scale, Reliability and Programmability for Global Internet Peering」をもとにして、Googleのデータセンターとインターネットの相互接続を担うネットワークシステム「Espresso」を紹介します。
前回は、一般的なBGPルーターによるインターネット接続において必要とされる機能、そして、これらを独自のアーキテクチャーで置き換えるEspressoの構成要素を紹介しました。今回は、これらの構成要素の連携について説明します。
前回、Espressoの中で、実際の通信処理を行うコンポーネントとして、次のものを紹介しました。
そして、これらを動的に制御するコントローラーとして、次のものがあります。
この中で、外部ネットワークとの物理的な接点となるのが、Peering Fabricです。これは、汎用のMPLSスイッチを束ねたネットワークファブリックで、パケットに付与されたMPLSラベルによってパケットを送出するポートが決まります。対向のISPごとに異なる物理ポートが割り当てられており、データセンター側からのパケットは、送信先のISPに対応したラベルが事前に付与された状態でPeering Fabricに到着します。これにより、複数のISPに対する接続がこれらのスイッチ群のハードウェア機能で処理されます。
図1は、外部のユーザーからのパケットを受信した際に発生するやりとりの一例です。ISPからのパケットを受信したPeering Fabricはパケットの種類に応じて転送先を決定しますが、事前に転送先が設定された特別なパケット以外は、まずは、GREトンネルを用いて、Packet Processorへと送られます(図1右)。ここでは、パケットに対するフィルタリング処理と次の転送先を決定するルーティング処理が行われます。一般的なBGPルーターの場合は、パケットを受信したルーターのハードウェア内部において、パケットフィルタリングやIPアドレスに基づいた転送処理が行われますが、それらの処理が外部サーバーに外出しされた形になります。
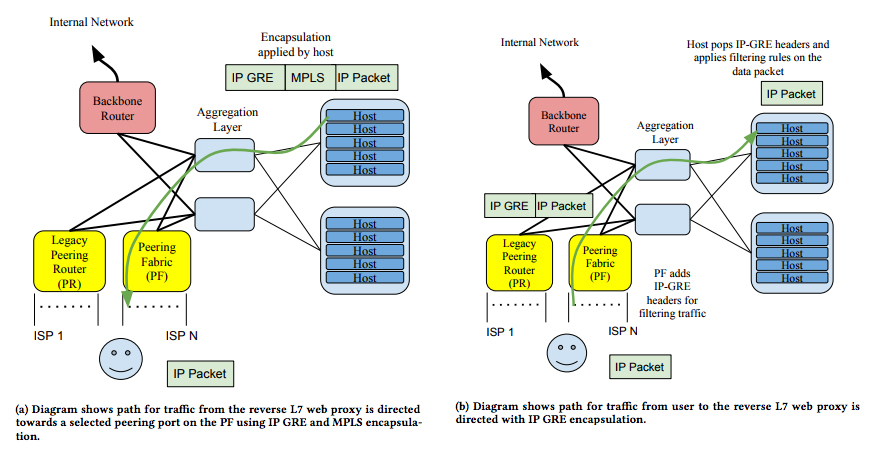
図1 外部ユーザーとパケットをやりとりする例(論文より抜粋)
前回の図3を見ると分かるように、Packet Processorが稼働するサーバー(Host)は、「Edge Metro」と呼ばれる場所に配置されています。これは、リバースプロキシーやコンテンツキャッシュなどの機能を提供する場所でもあります。そのため、ユーザーからのアクセスに対してキャッシュ上のコンテンツを返せる場合は、ここからダイレクトにパケットの返送が行われます(図1左)。返送パケットは、Packet Processorによって、送信先のISPに応じたMPLSラベルが付与された後に、GREトンネルを用いて、Peering Fabricへと届けられます。
Peering Fabricを構成するスイッチ群に対する設定、たとえば、MPLSラベルに対応するパケット送出ポートの設定などは、Peering Fabric Controllerによって行われます。この際、BGP Speakerが収集した情報により、どのポートの先にどのISPが接続されているかなどの判断を行います。ポートのリンクダウンを検知した際は、その情報をLocal Controllerに通知して、パケット送出に使用するポートを自動的に切り替えるなどの処理も行われます。
前述したリンクダウンに伴うポートの切り替えなど、接続拠点の内部だけで完了する経路制御は、各接続拠点に配置されたLocal Controllerによって行われます。BGP speakerが収集した経路情報を集約した後、Packet Processor、および、Peering Fabricに対して、MPLSラベルとポートの紐づけなど、必要となる設定を行います。(Peering Fabricに対する設定は、Peering Fabric Controllerによって仲介されます。)
一方、複数の接続拠点にまたがった最適化は、Global TE Controllerによって行われます。Global TE Controllerは、図2のような情報を各接続拠点から収集しており、これらにもとづいて、アプリケーションのプライオリティやアクセス元のクライアント(クライアント側のIPアドレスのレンジ)に応じて、パケットを送出する接続拠点とポート(パケット送信先のISP)を決定します。
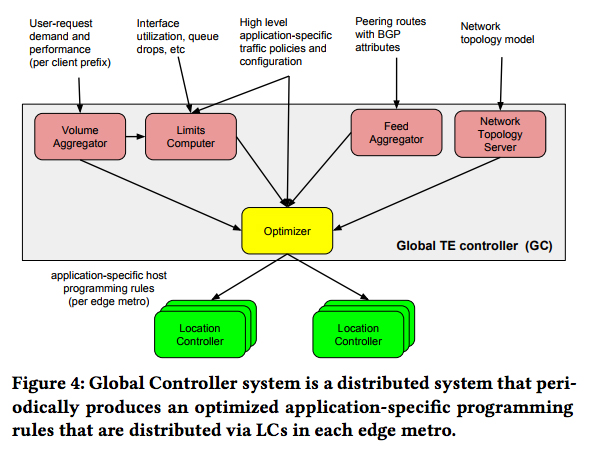
図2 Global TE Controllerが収集する情報(論文より抜粋)
Global TE Controllerが決定した情報は、各接続拠点のLocal Controllerに転送され、Local Controllerは、この情報を参照しながら実際の設定処理を行います。また、各接続拠点には従来型のBGPルーターも存在しており、パケットの送出に、BGPルーターとPeering Fabricのどちらを使用するかという指示もGlobal TE Controllerによって与えられます。これにより、従来型のBGPルーターを使用したまま、段階的にPeering Fabricの導入が進められるようになっています。
また、Global TE Controllerは、ユーザーからのアクセス量や各リンクのトラフィック量の情報も収集しており、特定のリンク(特定のISP)とのトラフィック量が多く、ネットワーク通信に遅延が発生していると判断した場合は、複数のISPに負荷を分散するといった処理も行われます。Global TE Controllerは、すべての接続拠点の状況を把握しているため、複数の接続拠点に負荷を分散することも可能です。冒頭の論文には、このような負荷分散の70%以上は、複数拠点にまたがって行われているとの記述があります。
さらに、それぞれのアプリケーションのトラフィックには、プライオリティが設定されており、Global TE Controllerは、プライオリティの高いトラフィックに通信帯域を割り当てた後、残りの通信帯域に対して、プライオリティの低いトラフィックを割り当てます。そして、万一、特定のリンクで通信帯域の不足が発生した場合、Peering Fabricは、プライオリティの低いトラフィックのパケットを優先的にドロップします。これにより、各リンクの帯域使用率を高めながら、プライオリティの高いトラフィックに対するパケットドロップを避けることができます。冒頭の論文には、約4割のリンクにおいて、半分以上の時間、帯域の使用率が95%を超えているという結果が記載されています。
また、実際にパケットドロップが発生した場合は、必要に応じて、他のリンクにトラフィックが負荷分散されますので、パケットドロップ数が極端に増えるということもありません。同じく冒頭の論文には、帯域の使用率が100%の状況でも、パケットドロップは平均で2%以下に抑えられているとの記載があります。
今回は、論文「Taking the Edge off with Espresso: Scale, Reliability and Programmability for Global Internet Peering」をもとにして、B2ネットワークのグローバルな経路制御を実現する「Espresso」の動作原理を説明しました。冒頭の論文には、より具体的な性能情報なども記載されていますので、興味のある方は、そちらも参照してください。
2017年の連載は、今回が最後となります。次回の記事は、2018年の新年に掲載させていただく予定です。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































