これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2015年に公開された論文「The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing」をもとにして、Cloud Dataflowによるストリーミング処理の設計パターンを学びます。
前回、MillWheelの解説の中で、ストリーミング処理では「データ処理の区切り」を設定する必要がある事を説明しました。Cloud Dataflowは、FlumeJavaのバッチ処理プログラミングモデルに、データ処理の区切りを設定する機能を追加することで、ストリーミング処理にも対応できるように機能拡張したものと考えることができます。
冒頭の論文では、図1のサンプルデータに対して、さまざまなデータ処理の区切りを設定する例が紹介されています。まずは、このサンプルデータの見方を説明しておきましょう。
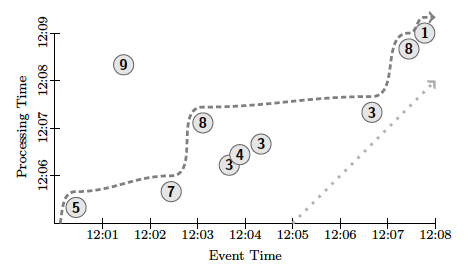
図1 サンプルデータ(論文より抜粋)
これは、不定期に発生する数値データについて、何らかの範囲を区切って、その範囲内での合計値を求めるというものです。論文内では、データに対する具体的な意味付けは与えられていませんが、ショッピングサイトの販売データ(図中の数字は1回の販売における売上金額)と考えるとよいかも知れません。1日分の売上の合計をバッチで計算する他に、1分単位の売上をリアルタイムに把握するなどのユースケースが考えられるでしょう。
図1は、横軸が「イベント時刻」になっていますが、これは個々のデータに付与されたタイムスタンプだと考えてください。システム上でプログラムコードが実行される実時刻は、縦軸の「処理時刻」の方になります。つまり、図1を下から上に見ていった時に、縦軸で示された時刻に、横軸で示されたタイムスタンプを持つデータがシステムに入力されるということになります。
そして、図1には、前回説明したLow Wartermarkの変化が破線で示されています。これは、未処理のデータに含まれる最も古いタイムスタンプを表わすものでした。たとえば、縦軸の処理時刻で見て、12:05~12:06の間に左下の⑤と⑦のデータ(それぞれのタイムスタンプは12:00過ぎと12:02過ぎ)を受信することで、Low Wartermarkの横軸の値が12:03まで進んでいます。Low Wartermarkが示す時刻(タイムスタンプ)は、横軸に対応する点に注意してください。
なお、この例では、左上の⑨のデータについては、Low Wartermarkの計算からは除外されています。前回説明したように、Low Wartermarkより古いタイムスタンプのデータが後から到着することを完全に排除することは不可能です。12:08過ぎに⑨のデータを受信したシステムは、何らかの例外処理を実施する必要があります。この点については、後ほど改めて説明します。
それでは、図1のデータを処理する具体的なコードを見ていきます。ここでは、ショッピングサイトの例を用いて、それぞれのデータは(商品ID, 売上) というKey-Value形式だと仮定します。商品IDがKeyになっていると考えてください。また、各データには付加情報としてタイムスタンプが付与されています。この場合、Cloud Dataflow(Apache Beam SDK)の組み込み関数 Sum.intergersPerKey() を用いることで、商品IDごとの売上合計が計算できます。図1では、簡単のために、商品IDが1種類しかない(もしくは、1種類の商品しか売れなかった)場合を考えているものとしてください。
ここでは、まずはバッチ処理の場合を考えてみましょう。昨日の売上データがファイルに保存されており、ここから昨日の売上合計を計算するのであれば、次のようなコードになります。
input = p.apply(TextIO.Read.from("input_file"));
output = input.apply(Sum.integersPerKey());
output.apply(TextIO.Write.to("output_file"));
1行目でファイルからデータを読み込んで、2行目で商品IDごとの合計を計算します。そして、3行目でその結果をファイルに書き出します。とてもシンプルなコードで、特に説明の必要はなさそうです。この処理の場合、データに付与されたタイムスタンプは、単純に無視されることになります。
また、Cloud Dataflowでは、同じバッチ処理でも、すべてのデータの集計が終わってから結果を出力するのではなく、データ処理の途中で定期的にその時点の結果を出力するということができます。たとえば、次の例は、1分ごとにその時点の合計値を出力します。
input = p.apply(TextIO.Read.from("input_file"));
worker = input.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.accumulating());
output = worker.apply(Sum.integersPerKey());
output.apply(TextIO.Write.to("filename"));
これは、2行目で「トリガー」を設定することで実現しています。トリガーは、データを出力するタイミングを設定する機能です。この例では、実時間が1分経過するごとに、その時点まで処理したデータの結果を出力するように設定しています。3行目にある accumulating() は、データを出力した後もカウント値をそのまま保持するという指定です。これを discarding() に変更すると、出力ごとにカウント値が0にリセットされて、前回の出力に対する追加分の値が出力されるようになります。図2の左はaccumulating()に設定した例で、右はdiscarding()に設定した例になります。図の下から上に向かって、処理が進んでいくものと考えてください。
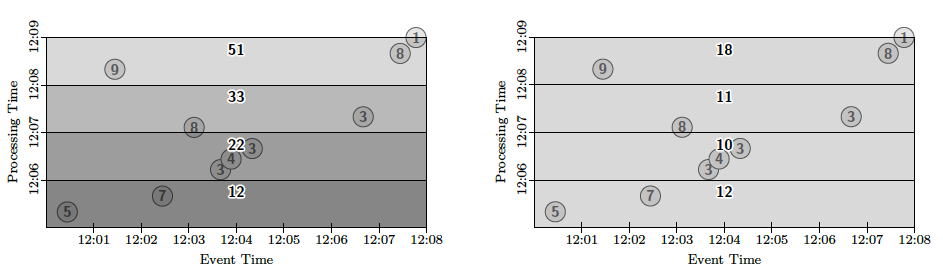
図2 バッチ処理における定期的なデータ出力例(論文より抜粋)
先ほどの例では、実時間の経過によってデータ出力のタイミングを設定しました。これをストリーミング処理に対応させるには、実時間ではなく、Low Wartermarkが示す時刻で処理を区切るように設定を変更します。たとえば、先ほどのコードの2行目~4行目を次のように書き換えます。
worker = input.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(Repeat(AtWatermark())))
.accumulating());
output = worker.apply(Sum.integersPerKey());
まず、1行目の Window.into(...) では、タイムスタンプを2分ごとの幅に区切って、各データを「ウィンドウ」に分割します。具体的には、図3のように、タイムスタンプを表わす横軸を2分ごとに区切って、[12:00,12:02]、[12:02,12:04] などのウィンドウを生成します。そして、2行目の .trigger(...) では、Low Wartermarkが各ウィンドウの右端に達するごとに、そのウィンドウの集計結果を出力するように設定しています。図3において、縦軸の実時刻にしたがって処理が進む中で、Low Wartermarkが各ウィンドウの右端に達するタイミングで、そのウィンドウの集計結果が出力されることになります。
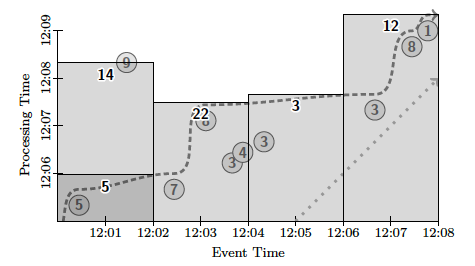
図3 Low Wartermarkを用いたストリーミング処理の例(論文より抜粋)
なお、この例では、左上の⑨のデータは、Low Watermarkの進みよりも遅延して現れる遅延データになります。この場合、遅延データが現れたタイミングで、該当のウィンドウの集計結果が再出力されます。この際、3行目に accumulating() が指定されているので、以前の結果にさらに新しい値を加えた結果(この例では14)が再出力されます。これを discarding() に変更すると、以前の結果は0にリセットされて、新しく追加された値(この例では9)が出力されます。出力データには、ウィンドウの情報(この例では、[12:00,12:02])が付与されているので、後段のシステムでは、同じウィンドウのデータを2回受け取った際の動作を設定しておくことになります。
これで、バッチ処理用のコードをストリーミング処理用に書き換えることができました。実際のデータ処理では、データの入力部分をCloud Pub/Subなどのストリーミング型のデータソースに置き換えて実行することになります。先ほどのバッチ処理の例とコードを比較すると、データを分割するウィンドウの設定、そして、データを出力するタイミングを示すトリガーの設定が変わっているだけで、本質的なコードの書き方には違いがないことに気がつきます。Cloud Dataflowでは、論理的にデータを区分する「ウィンドウ」と、物理的にデータを出力するタイミングを区切る「トリガー」の指定により、バッチ処理とストリーミング処理の両方を含む、さまざまなパターンの処理が可能になるのです。
先ほどの例では、2分単位の固定幅でウィンドウが設定されていました。これを固定ウィンドウと呼びます。Cloud Dataflowでは、この他にスライディングウィンドウやセッションウィンドウを設定することができます。スライディングウィンドウは、[12:00,12:30], [12:10,12:40], [12:20,12:50]・・・のように、重なった時刻を含むウィンドウの設定です。この例では、30分幅のウィンドウを10分ごとに生成しています。この場合、1つのデータは複数のウィンドウに含まれることになります。Cloud Dataflowでは、各データには、所属するウィンドウの情報が内部的に付与されるようになっており、ウィンドウごとに個別の集計処理が行われます。そのため、スライディングウィンドウの場合、1つのデータは所属するウィンドウの数だけ複製されるようになっています。
次に、セッションウィンドウは、ウィンドウの幅を動的に決定する仕組みです。たとえば、同一のKeyに対するデータが10分以上到着しなかった場合は、そこでウィンドウを閉じるといった設定になります。この場合、12:10のタイムスタンプのデータを受け取った後、Low Wartermarkが12:20になるまで同じKeyのデータを受け取らなければ、そこでウィンドウを閉じて、そこまでの集計結果を出力します。言い換えると、10分以内に同じKeyのデータが到着する限り、そのウィンドウの集計処理は継続するということです。この場合、長期間に渡ってウィンドウが閉じないという事もありえますが、そのような場合は、トリガーの設定により、定期的にその時点の集計結果を出力するといったことも可能です。図2のように、バッチ処理に対して、定期的に途中の集計結果を出力するのと同じ考え方になります。
あるいは、トリガーについてもさまざまな設定方法が用意されています。一定時間ごとに結果を出力するのではなく、1つのウィンドウに含まれるデータが一定数到着するごとに、そのウィンドウの結果を出力するといった設定も可能です。
今回は、Cloud Dataflowにおけるストリーミング処理の設計方法を解説しました。本文でも触れた、ウィンドウ(論理的なデータの区分方法)とトリガー(物理的なデータの出力タイミング)の組み合わせによる設定方法をよく味わってみてください。冒頭の論文には、この他のさらに複雑な設定例や、あるいは、入力データを複数のウィンドウに分割する内部処理の仕組みなども掲載されています。
さて、次回は少し趣向を変えて、「グーグルのシステムにおける数学の活用」という視点で話題を提供したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































