
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2013年に公開された論文「MillWheel: Fault-Tolerant Stream Processing at Internet Scale」をもとにして、ストリーミング処理に対応したデータ処理基盤「MillWheel」を紹介します。
前回も触れたように、Google Cloud Platform(GCP)では、バッチ処理とストリーミング処理を統合した分散データ処理サービスとして、Cloud Dataflowが提供されています。Cloud Dataflowと比較すると、MillWheelの機能はシンプルで限定的になりますが、「バッチ処理の拡張としてストリーミング処理を捉える」という発想は共通しています。今回は、MillWheelの仕組みを通して、ストリーミング処理を設計する際の基礎となる考え方を学びましょう。
先ほどの論文では、GoogleにおけるMillWheelの利用例として、「Hot Trendsサービス」が紹介されています。これは、Googleの検索サービスに入力された検索キーワードの中で、現在、最も人気の高い(入力数の多い)キーワードをリアルタイムに表示するもので、システムの全体像は、図1のようになります。
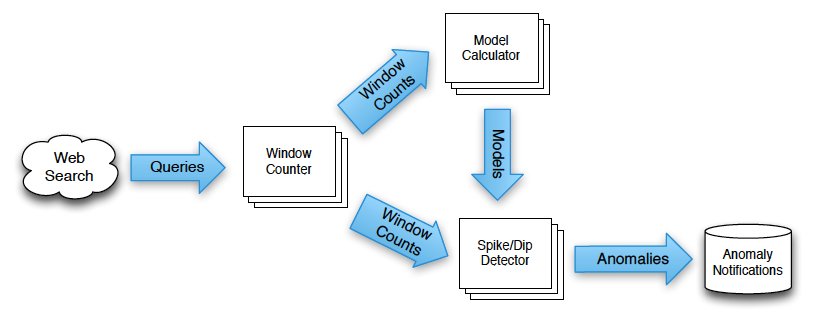
図1 Hot Trendsサービスにおけるデータ処理
このシステムでは、検索サービスに入力されたキーワードについて、1秒単位でその総数を集計して、入力数の多いキーワードを検出します。ただし、単純に数の大小を比較するだけでは、一般的によく入力されるキーワードが常に上位になってしまい、つまらない結果になる恐れがあります。そこで、過去の検索履歴から予想される入力数と比較して、通常よりも高い割合で入力されているものをトレンドとして検出します。この予測処理では、時刻変動を考慮した上で、その時刻における該当キーワードの入力数を予測しています。
図1の「Model Calculator」は、このような予測処理のモデルを組み立てる部分になっており、「Window Counter」で計算した実際の入力数を元にして、予測処理のモデルを更新していきます。そして、「Spike/Dip Detector」は、モデルから計算した予測数と実際の入力数を比較して、入力数のアノマリー、すなわち、予測と大きく異る状態を検出します。
Googleの検索サービスの利用状況を考えると、1秒単位の集計といっても、相当な量のデータ処理が必要なことが想像されるでしょう。MillWheelでは、入力データを (Key, Value) 形式で表現して、Keyの値ごとに並列して処理を行う仕組みが実装されています。図1の例では、各機能の箱が複数重なって描かれていますが、これは、複数のノードによって、キーワードごとの並列処理が行われていることを示します。以下では、このような並列処理を行う1つの処理単位を「処理ノード」と表現することにします。
バッチ処理とストリーミング処理の違いを理解するために、先ほどのキーワードをカウントする例をバッチ処理で実装するとどうなるか考えてみましょう。たとえば、昨日の1日分の検索データが1つのファイルに保存されており、このファイルをバッチ処理して、それぞれのキーワードについて、1時間ごとの入力数をカウントしてみます。
ここで、入力データは、(キーワード, 検索時刻) というKey-Value形式で、キーワードごとの並列処理を行う仕組みがあるものとします。この場合、1つの処理ノードでは、特定キーワードの数だけをカウントすればよいことになります。1時間単位で集計する前提ですので、0〜23(「時分秒」の「時」の値)をキーにしたハッシュにカウント数を保存していき、全部のデータを受け取った時点で、最終的なカウント数を出力すれば処理は終わりです。
それでは、これと同じ処理をストリーミングで実施するとどうなるでしょうか? 検索システムからリアルタイムに (キーワード, 検索時刻) という形式のデータが送られるとした場合、単純に考えると、0時から1時の間は0時台のデータをカウントして、1時から2時の間は1時台のデータをカウントする、という方法が考えられます。しかしながら、この方法の場合、データの遅延に対応することができません。たとえば、このシステムにやってくるデータが前段のシステムで前処理されている場合、前処理の時間を考えると、0時台のデータは、きっちりと0時から1時の間にくるとは限りません。実時刻は1時を過ぎているのに、前段には、まだ、0時50分のデータが残っている可能性があります。したがって、ストリーミング処理においては、「自分より前段のシステム内にどこまで古いデータが残っているか」という点を考慮する必要があります。そして、MillWheelには、この情報を「Low Watermark」として提供する仕組みがあります。
Low Watermarkは、前段のノードを含めたすべての未処理データにおける、一番古いタイムスタンプを表します。たとえば、Low Watermarkが1時になれば、0時台のデータはすべて処理したと判断して、0時台のカウント数を最終結果として出力することが可能です。図1のように、複数の処理ノードが連携して分析処理を進める場合、各ノードは(それぞれに前段のノード構成が異なるため)、異なるLow Watermarkを持つことになります。この後で説明するように、MillWheelでは、処理ノードごとに個別のLow Watermarkが計算されるようになっています。
MillWheelの上で実行されるデータ処理のコードは、図2のようなフレームワークを使用することができます。まず、新しいデータが到着すると「ProcessRecord」関数が呼び出されます。今の例であれば、データのタイムスタンプ(検索時刻)を見て、該当するタイムスロットのカウントを1つ増やすように、この関数を実装しておきます。さらに、このタイムスロットのデータをはじめて受け取った際には、「Timer API」を用いて、「Low Watermarkが該当タイムスロットの終了時刻に達した時」に発火するタイマーをセットしておきます。その後、このタイマーが発火すると、「ProcessTimer」関数が実行されます。この関数では、タイマーの発火時刻を元にして、対応するタイムスロットのカウント数を次の処理ノードに出力します。このようなデータ出力処理は、「ProduceAPI」を用いて行います。
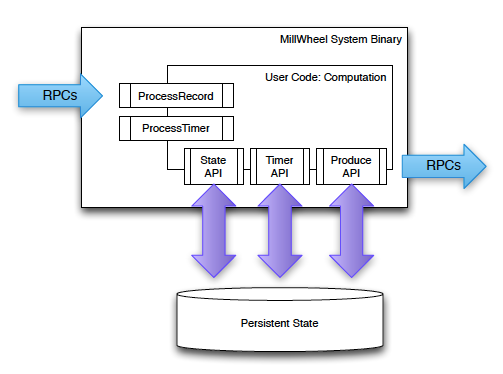
図2 MillWheelのプログラミングフレームワーク
以上の説明から、バッチ処理とストリーミング処理の違いが見えてきたのではないでしょうか? バッチ処理の場合は、1つの処理ノードは、基本的には、すべてのデータを受け取った段階で最終結果を次の処理ノードに送ります。一方、ストリーミング処理の場合は、「すべてのデータ」という考え方はできません。どこかのタイミングで処理の区切りをつけて、その時点の処理結果を出力する必要があります。Low Watermarkを利用して、このような処理の区切りを設定できる点が、MillWheelの特徴になります。
最後に、Low Watermarkを計算する仕組みを説明しておきましょう。まず、MillWheelにデータを送る外部のデータソースは、何らかの方法で自分自身のLow Watermarkを決定して、その値を最初の処理ノードに提供します。時刻順にソートされたログファイルがデータソースであれば、最後に送ったログのタイムスタンプがLow Watermarkに一致します。
ただし、時刻順のソートが完全ではなく、そのログより古い時刻のログがまだ残っている可能性がある場合は、余裕を見て、少し以前の時刻をLow Watermarkとして与えます。ここでは、例として、5分前の時刻を設定したものとします。これが、データソースからデータを受け取った最初の処理ノードのLow Watermarkになります。ただし、処理ノード内にデータが滞留して、さらに古い未処理データが残っている可能性があります。処理ノード内に10分前の未処理データが残っている場合、このノードのLow Watermarkは、10分前になります。さらに後段にある処理ノードについても、同様の方法でLow Watermarkが計算されます。一般には、前段のノードのLow Watermarkと自ノード内の最も古い未処理データのタイムスタンプを比較して、より古い方がこのノードのLow Watermarkになります。このようにして、すべての処理ノードのLow Watermarkが順番に決まっていきます。
ただし、この方法では、最初の入力データソースのLow Watermarkを完全に信頼することはできません。先の例では「余裕を見て5分前の時刻を設定する」としましたが、それでも何らかの理由で、さらに古いログデータが後から出てくる可能性は残ります。MillWheelでは、このような遅延データは、例外として処理します。各処理ノードでは、Low Watermarkよりも古いデータを受け取った場合は、単純にそのデータを破棄する、あるいは、後段のノードに出力済みの結果に対する修正情報を送るなどの処理を行います。当然ながら、後段のノードでは、このような修正情報に対応する処理を実装しておく必要があります。
今回は、MillWheelにおけるストリーミングデータ処理の考え方を中心に説明を行いました。Low Watermarkを用いてデータ処理の区切りを見つける点がポイントになるわけですが、Low Watermarkの考え方は、Cloud Dataflowでも利用されています。MillWheelの場合は、処理ノードで実行するコードの中でタイマーを設定して、処理を区切るタイミングをその都度指定する必要がありましたが、Cloud Dataflowでは、この部分の手続きがよりシンプルになっています。固定ウィンドウ、スライディングウィンドウ、セッションウィンドウなど、典型的な処理パターンを専用のパイプラインメソッドで指定する形になります。
なお、MillWheelは、分散型の処理基盤ですので、当然ながらノードの障害停止などに対する冗長性を考慮した設計がなされています。各ノードの処理状態を永続ストレージに出力することで、ノード障害時に他のノードが処理を継続する仕組み、あるいは、切り替えのタイミングによっては同一のデータが2回出力される可能性がありますが、そのようなデータの重複を検出して破棄する仕組みなどが実装されています。このあたりの詳細は、冒頭の論文で確認をしてみてください。
そして、実は、Cloud Dataflowについても、そのデータ処理の仕組みを解説した論文が公開されています。次回は、いよいよCloud Dataflowの解説へと進みたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































