
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2010年に公開された論文「FlumeJava: Easy, Efficient Data-Parallel Pipelines」をもとにして、分散型のデータ処理基盤を提供する「FlumeJava」を紹介します。一般に、分散データ処理の方式には、バッチ型のデータ処理とストリーミング型のデータ処理があります。FlumeJavaは、バッチ型のデータ処理に特化した基盤となります。
ちなみに、Google Cloud Platform(GCP)では、分散データ処理サービスとして、Cloud Dataflowが提供されています。これは、今回紹介するFlumeJavaと、ストリームデータ処理基盤であるMillWheelの技術を統合して開発されたものです。今回は、FlumaJavaの解説を通して、Cloud Dataflowのバッチ処理機能の基礎を学びましょう。
FlumeJavaの仕組みを説明する前に、まずは、ユーザー視点でどのようなデータ処理ができるのかを整理しておきます。分散データ処理技術というとMapReduceが有名ですが、MapReduceの場合は、内部的に次の3つの処理が行われます。
通常のMapReduceでは、Map処理の関数とReduce処理の関数、あとは、Shuffle処理を行う際にどのような条件でグループ化するのかという指定を行います。Map処理とReduce処理を複数のノードで並列実行することで、並列分散処理を実現します。ただし、現実のデータ処理では、1種類のMapReduceだけで必要な処理が完了するとはかぎりません。場合によっては、複数のMapReduceを何段階にも組み合わせていく必要があります。
一方、FlumeJavaでは、Map/Shuffle/Reduceに相当する処理を複数定義して、これらをパイプラインとして結合することができます。これらは、parallelDo、groupByKey、combineValues、flattenの4種類に別れますが、大雑把に言うと、最初の3つが、Map、Shuffle、Reduceのそれぞれに対応する処理になります。これらの処理を自由に組み合わせられる点が、通常のMapReduceとは異なります。
FlumeJavaでは、一般的なデータの集合を「PCollection」、Key-Value形式のデータの集合を「PTable」というデータ形式で扱います。通常のMap処理であれば、一般的なデータをKey-Value形式に変換して出力する必要がありますが、parallelDoでは、そのような制約はありません。PCollection形式のデータから、再度、PCollection形式のデータを出力して、それをさらに別のparallelDoに入力するといった処理が可能です。一般には、図1のようなデータフローが定義されることになります。
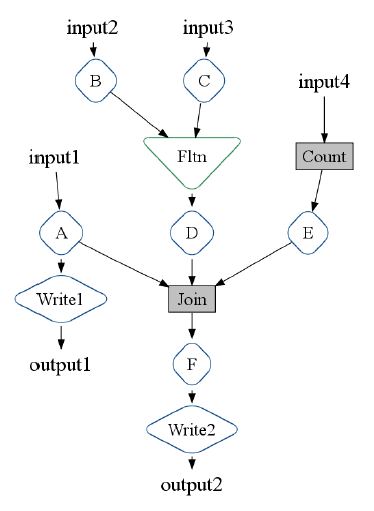
図1 FlumeJavaで定義したデータフローの例(論文より抜粋)
この図では、A〜Fは、parallelDoを用いて定義した何らかのデータ変換処理です。「Fltn」は、先ほど出てきたflattenと呼ばれる処理で、複数のPCollectionをまとめて、1つのPCollectionに変換します。「Join」は、複数のPTableから同一のKeyを持つデータをまとめて、1つのPTableに変換する処理を行います。単純化して表現すると、<Key, [Vaule1, Value2, ...]> (Value1, Value2, ... は、同じKeyを持つデータ)という形式のデータの集まりが出力されます。ただし、厳密には、入力元のPCollectionごとにデータの型が異なるため、複数の型を保存可能なUnion型のデータ型に変換するなどの処理が必要です。Joinは、このような処理を複数のparallelDoとgroupByKeyの組み合わせで実装したライブラリ関数です。
同じ図の中にある、「Count」も同様のライブラリ関数です。同一のデータを数えて、<データ, 個数> というKey-Value形式で出力する、定番のMapReduce処理をparallelDoとgroupByKeyの組み合わせで実装しています。このようなデータ変換処理を経て、最後に、「Write1」「Write2」の処理によって、処理済みのデータがファイルに書き出されます。この例では、4種類の入力データから、2種類の出力データが生成されることになります。
このように、FlumeJavaでは、多段階のMapReduceに相当する処理を1つのデータフローにまとめて記述することができるため、データ処理のコードを書く作業が簡単になります。目的の処理にあわせて、必要となるMapReduceの組み合わせを考えていくという、職人技は不要になるというわけです。
それでは、このように定義されたデータフローは、どのようにして実行されるのでしょうか。FlumeJavaでは、内部的にMapReduceのジョブを組み立てるという作業が行われます。前述のように、データフローに含まれる個々の処理は、従来のMap処理やReduce処理に対応していますので、これを多数のMapReduceに「直訳」することはそれほど難しくありません。ただし、それだけでは、冗長で非効率な処理になるのは目に見えています。そこで、FlumeJavaでは、たとえば、同一のデータソースを持つ複数のParallelDoについて、それぞれの処理関数を合成して、単一のParallelDoに変換するなどの最適化処理を行います。FlumeJavaにおける処理単位は、一般的なMapReduceを拡張した、「MapShuffleCombineReduce(MSCR)」と呼ばれるもので、図2のように、複数のMap処理と複数のShuffle/Combine/Reduce処理を並列に実行することが可能です。ユーザーがプログラムコードとして与えたデータフローは、最終的に多段階のMSCRとして表現されることになります。
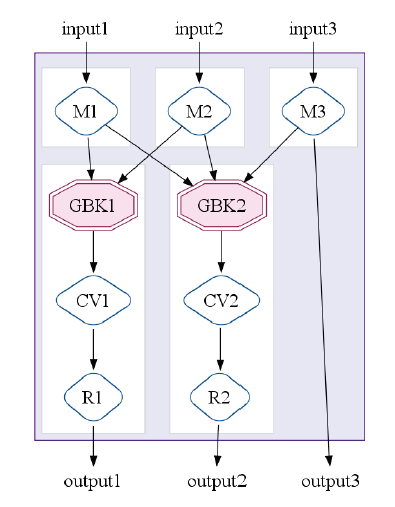
図2 MSCRの構成例(論文より抜粋)
図3は、論文で紹介されている最適化の例で、左図のデータフローは、最終的に、右図のような2段階のMSCRに集約されます。FlumeJavaの基盤は、APIサービスとして提供されていますので、ユーザーは、APIリクエストとしてプログラムコードを投入します。その後、処理対象のデータ量に応じて、MapReduce(MSCR)の実行ノードが動的に展開されて、多段階のMSCRの処理が並列実行されるという流れになります。
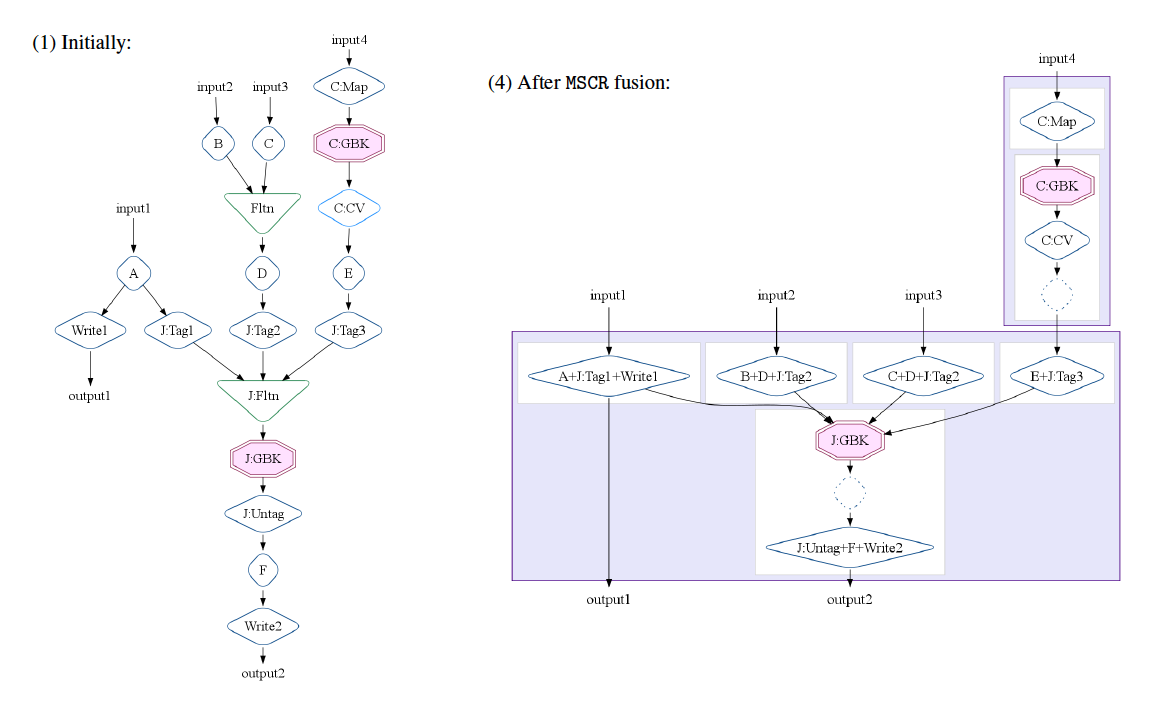
図3 データフロー最適化の実行例(論文より抜粋)
論文の中では、最適化による処理速度向上を計測したベンチマークの結果も公表されています。FlumeJavaが最適化した構成の他に、データフローを「直訳」したMapReduceの構成、そして、それをMapReduceの専門家が手作業で最適化した構成の比較です。ほとんどのケースで、FlumeJavaによる最適化は、専門家の手作業による最適化と同等の性能を達成しているという結果が得られています。
今回は、バッチ型の処理に対応した、分散データ処理基盤を提供するFlumeJavaを紹介しました。FlumeJavaでは、その名前から予想されるように、Java言語を用いてデータフローを記述していきます。一方、GCPで提供されるCloud Dataflowでは、Apache Beamという名称のSDKを用いてデータフローを記述します。Apache Beamはオープンソースソフトウェアとして開発が進められており、Java言語の他に、Pythonへの対応も行われています。
次回は、Cloud Dataflowの基礎となるもう一つの技術、「MillWheel」を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































