
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2011年に公開された論文「Megastore: Providing Scalable, Highly Available Storage for Interactive Services」をもとにして、分散データストア「Megastore」のアーキテクチャーを解説していきます。前回触れたように、Google Cloud Platform(GCP)で提供されるCloud Datastoreは、内部的にMegastoreを用いて実装されています。Cloud Datastoreを使いこなす上でも、Megastoreの構造を理解することは重要なポイントになります。
まず、図1は、Megastore全体の構造を示したものになります。複数のデータセンターにデータを複製保存することで地理的な冗長性を確保しており、それぞれのデータセンターには、バックエンドのデータストアとしてBigtableのクラスターが用意されています。
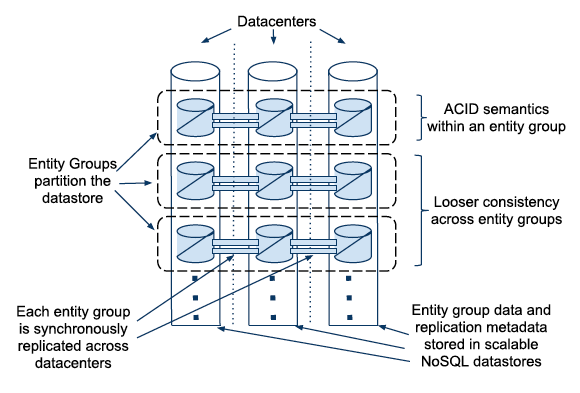
図1 Megastoreの全体像(論文より抜粋)
一般に、複数のデータセンターにまたがるデータレプリケーションでは、ネットワークの遅延に注意を払う必要があります。一部のデータセンターでネットワーク遅延が発生することで、データストア全体の動作がスローダウンすることを避けるため、Megastoreでは、Paxosと呼ばれるアルゴリズムを使用しています。基本的には、過半数のデータセンターに複製が完了した時点で次の処理に進み、残りのデータセンターへの複製はバックエンドで非同期に行うという動作になります。これにより、一部のデータセンターで極端な遅延が発生しても、システム全体のスローダウンを回避することが可能です。
また、レプリケーションの状態はエンティティグループごとに管理されます。後述する仕組みにより、それぞれのエンティティグループについて、そこに含まれるデータのレプリケーションの進捗状態が内部的に把握されるようになっています。
Megastoreに保存されたエンティティのデータは、どのような形でBigtableに保存されるのでしょうか? 実は、Megastoreのデータは、Bigtableの1つのテーブルにまとめて保存されます。第5回の記事で解説したように、Bigtableでは、1つの行に対して複数のカラムファミリーが用意されます。Megastoreのエンティティを保存する際は、プロパティごとに個別のカラムファミリーを用意することで、Kindによって異なるプロパティを同一のテーブルにまとめて配置しています。
さらに、Bigtableの行を特定するRow Keyとして、各エンティティのAncestorパスが用いられます。ここで、テーブル内の各行は、Row Keyの辞書順にソートされている事を思い出してください。すべてのKindのエンティティを1つのテーブルにまとめた上で、Ancestorパスの順にソートすると、それぞれのエンティティはどのような順序で並べられるかわかるでしょうか?
―― 図2の例からわかるように、ルートエンティティを先頭にして、エンティティグループのツリー構造を「深さ優先探索」で検索するような順序にデータが並びます。ここでは、前回用いた「本棚アプリ」のデータを例にしていますが、たとえば、ユーザー「Alice」が所有する書籍のデータは、すべてまとめて連続する行に配置されます。Ancestorクエリーによって、Aliceが所有する書籍のデータをまとめて取得するような場合、連続する行から効率的にデータを取り出せることがわかります。
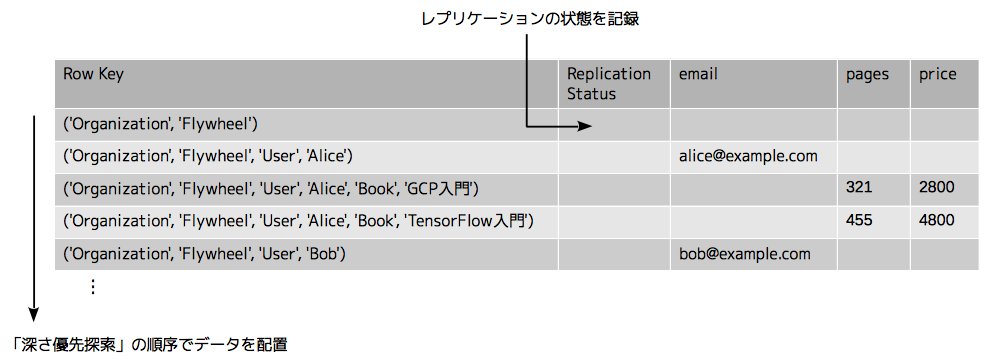
図2 Bigtableに対するデータの保存形式
Cloud Datastoreの検索処理は、専用のインデックステーブルを参照して行われます。このインデックステーブルもまた、Bigtableの上に作成されます。この時、グローバルクエリー用のインデックステーブルとAncestorクエリー用のインデックステーブルが別々に用意される点に注意が必要です。
特にAncestorクエリー用のインデックステーブルでは、1つのエンティティに対して、複数の行が用意されます。具体的には、1つのエンティティについて、「そのAncestorパスに含まれるそれぞれのエンティティのAncestorパス」をRow Keyとする行がインデックステーブル上に用意されます。―― 言葉で言うと複雑ですが、具体例をみればすぐに分かるでしょう。たとえば、次のAncestorパスを持つエンティティを考えます。
('Organization', 'Flywheel', 'User', 'Alice', 'Book', 'GCP入門')
この場合、「このAncestorパスに含まれるそれぞれのエンティティのAncestorパス」は、次の3つになります。
('Organization', 'Flywheel')
('Organization', 'Flywheel', 'User', 'Alice')
('Organization', 'Flywheel', 'User', 'Alice', 'Book', 'GCP入門')
したがって、ページ数「pages」を検索条件とする下記のインデックスを定義した場合、図3のようなインデックステーブルが用意されることになります。それぞれのRow Keyには、前述のAncestorパスに加えて、ページ数の値が付与されている点に注意してください。
indexes: - kind: Book ancestor: yes properties: - name: pages

図3 Ancestorクエリー用のインデックステーブルの例
この例では、2つのエンティティに対応するインデックスのみを示していますが、Ancestorクエリーの起点となるエンティティを指定すると、そのエンティティ配下のすべてのデータが固まって配置されていることがわかります。次のように、('Organization', 'Flywheel', 'User', 'Alice')をAncestorとするクエリーを実行した場合、図3のインデックステーブル上では、「('Organization', 'Flywheel', 'User', 'Alice') 配下のすべてのエンティティ」と示された行を見ることで、検索対象データをすべて把握することができます。
SELECT * FROM Book WHERE pages > 400 AND __key__ HAS \
ANCESTOR Key('Organization', 'Flywheel', 'User', 'Alice')
そして、この固まりに含まれるデータは、Row Keyの末尾についたページ数の順にソートされているので、この中から「ページ数が400以上」のデータを特定するのも簡単です。このようにして、検索の起点となるAncestorでインデックステーブル上のデータの範囲を絞り込んだ上で、検索条件にマッチするプロパティを持つデータが検索されることになります。
ここからわかるのは、Cloud Datastoreでは、検索条件に含まれるプロパティごとに、個別のインデックステーブルを用意する必要があるという事実です。複数のプロパティを検索条件に含むクエリーに対しては、複数のプロパティを末尾に付与したRow Keyを持つインデックステーブルが必要になるというわけです。
ただし、グローバルクエリー用のインデックステーブルについては例外があり、単一のプロパティを含むグローバルクエリー用のインデックステーブルは、Kindを定義した際に自動で作成されるようになっています。そのため、単一プロパティを検索条件に含むグローバルクエリーについては、明示的にインデックスを用意する必要がありません。
最後に、Ancestorクエリーにおけるストロングコンシステンシーの実現方法について説明しておきます。前述のように、データレプリケーションの状態はエンティティグループ単位で管理されており、Bigtableのテーブル上では、ルートエンティティに対応する行にレプリケーションの状態を示す情報が記録されています。図2の「Replication Status」がこれに相当します。Ancestorクエリーが発行された場合は、はじめに、該当のエンティティグループのデータ、および、関連するインデックステーブルのレプリケーションの状態が確認されます。ここで、最新のデータが反映されたことを確認した上で検索処理を実行することで、ストロングコンシステンシーが実現されます。
一方、グローバルクエリーの場合、検索対象のデータは複数のエンティティグループにまたがるので、性能上の問題を避けるため、すべてのデータが最新であることの確認は行われません。このため、グローバルクエリーには、イベンチュアルコンシステンシーが適用されることになります。
今回は、Megastoreの内部構造から、Cloud Datastoreの検索処理の仕組みをひもときました。なお、冒頭の論文はあくまでMegastoreの構造を解説したもので、Cloud Datastoreについては触れられていないので注意してください。今回の説明は、Cloud Datastoreに関する公開情報とあわせて組み立てたものになります。Cloud Datastoreのインデックスに関する詳細は、筆者が公開しているスライドも参考にしてください(*1)。この他の話題として、論文の中では、Paxosアルゴリズムの動作が詳しく解説されていますので、データレプリケーションの仕組みに興味のある方には、一読をお勧めしたいと思います。
次回は、新しい話題として、FlumeJavaの論文を解説したいと思います。GCPでは、Cloud Dataflowとして提供されるサービスを背後で支える技術となるものです。
*1 Google Cloud Datastore Inside-Out
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































