
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Napa: Powering Scalable Data Warehousing with Robust Query Performance at Google」を元にして、Google社内で利用されている、Napaと呼ばれるデータウェアハウスシステムを紹介します。今回は、ストリーミングで受け取ったデータを検索可能な形に変換する「Storage」の処理について説明します。
「データベースのテーブルに新しいデータを書き込む」という処理を素朴に考えた場合、「最新のデータを保持するテーブルがあり、新しいデータを受け取るごとにそのテーブルを上書きで更新する」という流れをイメージするかも知れません。しかしながら、Napaは、リアルタイムに生成されるデータをストリーミングで受け取るという特徴があるため、受け取ったデータを即座にテーブルに反映するのではなく、「差分データを蓄積しながら、差分データ同士を徐々にマージしていく」という戦略を取ります。図1は、差分データがマージされていく様子を示した図になります。
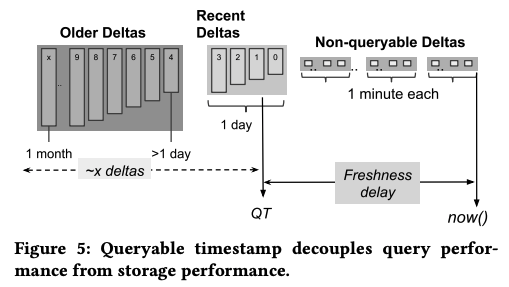
図1 差分データがマージされていく様子(論文より抜粋)
まず、図1の右にある「Non-queryable Deltas」は受け取った直後の生データを表します。これらのデータを一定の時間範囲(たとえば1分間)ごとのグループに分けて、グループ内のデータを1つの差分データにマージします。各差分データは、列指向のデータ構造を持ち、高速に検索できるように、レンジ分割やインデックスの付与などの処理が行われます。イメージとしては、一定の時間範囲のデータのみを保存したテーブルが個別に用意されていると考えればよいでしょう。図1の中央にある「Recent Deltas」は、このような1回目のマージ処理が行われた差分データを表します。そして、これらの差分データをより大きな時間範囲(たとえば1日)ごとのグループに分けて、再度、マージ処理を行います。このようにして、差分データのマージ処理を段階的に行うことにより、差分データの数を減らしていきます。最も古い差分データから直近の差分データまでを総合することで、最新のテーブルの状態が再現されることになります。
ただし、実際にテーブルを検索する際は、すべての差分データを総合するのではなく、図1の「QT」で示された、過去のある時点までの差分データに限定します。「QT」は、「Queryable Timestamp(検索可能なタイムスタンプ)」を表しており、この時刻までのデータが検索結果に反映されることを意味します。実際のQTの値は、検索処理の性能要求に応じて変化しますが、通常は、QTより古い差分データ(検索時の処理対象となる差分データ)の個数が数十個程度になるように調整されます。差分データのマージ処理が進むにつれて、QTの値は自動的に更新されていきます。
このように、ストリーミングで受け取ったデータを段階的にマージする処理に加えて、検索時に一定範囲の差分データを総合することで、最終的な結果を得るという流れになります。QTによって検索時に処理する差分データの数を制限することで、検索処理の応答時間をチューニングすることができるのです。たとえば、QTの値をより古い値に設定すれば、検索時に処理するべき差分データの分量を減らせるので、検索の応答時間を短縮することができます。一方、より最新のデータに対する検索処理が必要な場合は、QTの値をより新しい値に設定します。この場合は、処理対象の差分データの数が増えるため、検索の応答時間は長くなります。
なお、1つのデータベースには複数のテーブルがあり、上述のQTの値はテーブルごとに決まります。実際の検索処理では、すべてのテーブルのQTにおいて、最も古い値が適用されることになります。また、Napaでは、テーブルの更新に合わせて、ユーザー定義ビューの更新も行われます。マージ処理が進んでテーブルのQTが更新されると、対応するビューも合わせて更新されます。
Napaのテーブルに対する検索は、「F1 Query」と呼ばれる検索エンジンによって行われます。F1 Queryは、Google社内で古くから用いられている、検索対象のデータに依存しない汎用的なSQLの実行エンジンです。図2に示すように、メタデータから検索対象の差分データを特定した上で、クエリーの実行計画を立て、実行計画に含まれるサブクエリーを並列に実行していきます。差分データへのアクセスは、図2の「Delta Server」を介して行われます。また、差分データの実体は、分散ファイルシステムであるColossusに格納されており、データへのアクセスを高速化するための分散キャッシュがその前段に配置されています。
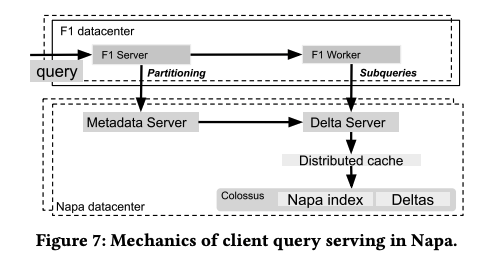
図2 F1 Qeuryによる検索処理の流れ(論文より抜粋)
今回は、2021年に公開された論文「Napa: Powering Scalable Data Warehousing with Robust Query Performance at Google」を元にして、Google社内で利用されている、Napaと呼ばれるデータウェアハウスシステムについて、差分データを用いたデータ更新処理を説明しました。次回は、F1 Queryから実行される検索処理を高速化するための工夫、そして、プロダクション環境における性能データなどを紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































