これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「ghOSt: Fast and Flexible User-Space Delegation of Linux Scheduling」を元にして、Googleのエンジニアが開発したプラグイン型のタスクスケジューラ「ghOSt」を紹介します。今回は、実環境におけるghOStの性能を示すベンチマークデータを紹介します。
論文の中では、ghOStのさまざまな処理に要する時間を個別に計測したマイクロベンチマークの結果と、実環境のアプリケーションに対してghOStを適用した場合の効果を測定した結果が示されています。はじめにマイクロベンチマークの結果をまとめると、図1のようになります。

図1 マイクロベンチマークの結果(論文より抜粋)
まず、1. と 2. は、Linuxカーネルがメッセージキューを介してエージェントにメッセージを通知する際に要する時間です。前回説明したように、「per-CPUモデル」で使用するローカルエージェント(1.)の場合は、カーネルがメッセージを投入した後に、エージェントを実行状態に変更します。この際の切り替え処理(コンテキストスイッチ)のオーバーヘッドがあるため、グローバルエージェント(2.)の場合よりも処理時間が長くなっています。グローバルエージェントは、複数のCPUコアをグループ化した際に用いられるもので、常に起動状態のエージェントがポーリングを行います。そのため、コンテキストスイッチのオーバーヘッドがありません。
3. は、ローカルエージェントがスケジューリング処理を行う時間です。Linuxカーネル標準のCFSの場合は約600nsなので、これよりも少しだけ余分な時間がかかっています。これは、エージェントのスケジューリング結果をLinuxカーネルに通知するコミット処理などによるものと考えられます。4.〜9. は、グローバルエージェントがスケジューリング処理を行う時間です。この場合は、特定のCPUコアで実行中のエージェントが複数のCPUコアに対するスケジューリングを行います。そのため、スケジューリング結果を対象のCPUコアに通知するためのオーバーヘッド(5. および 8.)が加わります。1つのCPUコアだけを対象にした場合(4.〜6.)、全体の処理時間は1772nsで、ローカルエージェントの2倍以上の時間がかかります。ただし、グローバルエージェントは複数のCPUコアをまとめて処理することが目的であり、対象のCPUコアを増やすことにより、オーバーヘッドの割合を減らす事ができます。10コアの場合(7.〜9.)の結果を見ると、全体の処理時間は5688nsですので、1コアあたりの処理時間は、CFSを下回ることになります。図2は、処理対象のCPUコアを増やした場合に、1秒間に実行できるトランザクション数がどのように変化するかを実機で測定した結果です。これを見ると、20コア程度までは、コア数に比例して処理性能が伸びていることがわかります。その後、性能が伸びなくなっているのは、NUMAアーキテクチャーに起因するもので、「遠方」のCPUコアに通知するためのオーバーヘッドが大きくなるためです。
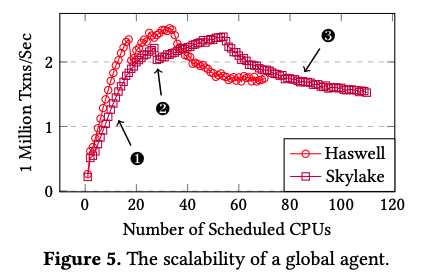
図2 グローバルエージェントが処理可能なトランザクション数(論文より抜粋)
実環境のアプリケーションにghOStを適用した場合の効果としては、「Google Search」と「Google Snap」にghOStを適用した結果が示されています。ここでは、Google Searchに対する結果を紹介します。Google Searchのシステムでは、Linuxカーネル標準のCFSが用いられていますが、これをghOStに置き換えた場合に、検索処理のスループットとレイテンシーがどのように変化するかを測定します。測定の際は、ベンチマーク用のクライアントを用いて、3種類の検索ワークロードを投入します。それぞれ、メモリー上のデータを使用する検索処理(Type A)、SSD上のデータを使用する検索処理(Type B)、CPUによる大量の計算が発生する検索処理(Type C)に別れます。
Google Searchの検索処理では、検索リクエストを受け取ったスレッドは、複数のワーカースレッドを起動して、実際の検索処理を行います。この際、いくつかのスレッドは同一のデータにアクセスするため、これらを同一のNUMAノード、あるいは、同一のCPUソケットに割り当てる事で、データローカリティを活かして処理を高速化することができます。ghOStのグローバルエージェントを用いれば、このようなCPUトポロジーを意識したスケジューリングを複数のスレッドに対してまとめて行う事ができます。CFSの場合は、「per-CPUモデル」のスケジューリングになるため、この点でghOStに優位性があります。論文にはghOStで用いるポリシーの詳細も記載されていますが、ここでは、最終的な測定結果のみを紹介します(図3)。
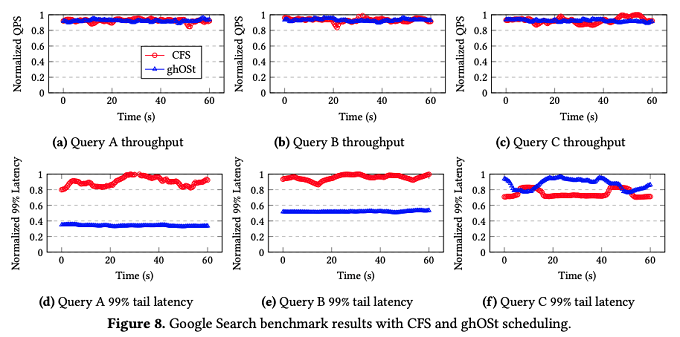
図3 Google Searchに対するベンチマーク結果(論文より抜粋)
図3の(a)(b)(c)は、3種類のクエリーに対するスループットを示すもので、CFSとghOStはほぼ同等のスループットを実現しています。一方、図3の(d)(e)(f)は、3種類のクエリーに対するレイテンシー(99%のテイルレイテンシー)を示すもので、(d)(e)(Type AとType Bのクエリー)では、ghOStの方がより短いレイテンシーを実現しています。(f)(Type Cのクエリー)では、ghOStの優位性が見られませんが、これは、CPUによる処理時間が長いため、検索処理のスレッドが他のスレッドに割り込まれる可能性が高いためと思われます。CFSの場合は、Linuxカーネルの標準機能(nice値)で検索処理のスレッドの優先度を上げていますが、この実験では、ghOStのポリシーにはそのような考慮は含まれていなかったということです。従って、ghOStのポリシーを適切に修正すれば、CFSよりもよい結果を出せる可能性があることが論文の中で説明されています。
今回は、2021年に公開された論文「ghOSt: Fast and Flexible User-Space Delegation of Linux Scheduling」を元にして、Googleのエンジニアが開発したプラグイン型のタスクスケジューラ「ghOSt」について、実環境での性能を示すベンチマークデータを紹介しました。
次回は、サーバークラスターの「オーバーコミット」を最適化するアルゴリズムの話題をお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































