
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2021年に公開された論文「Take it to the Limit: Peak Prediction-driven Resource Overcommitment in Datacenters」を元にして、サーバークラスターの「オーバーコミット」を最適化するアルゴリズムを解説します。この論文では、サーバー全体のリソース使用量のピーク値を正確に予測する「Peak Oracle」という考え方を用いてアルゴリズムの設計と評価を行っており、アルゴリズムの評価・チューニング手法としても興味深い内容です。
はじめに、サーバークラスターの「オーバーコミット」について簡単に説明します。Googleのデータセンターでは、Borgと呼ばれるコンテナ管理システムを用いたアプリケーションのデプロイが行われており、数万台のサーバーからなるサーバークラスター上で膨大な数のジョブが稼働しています。それぞれのジョブは、複数の「タスク」をコンテナで起動しますが、それぞれのタスクが必要とするリソース(CPU実行時間、および、メモリー使用量)を指定することができます。Borgのスケジューラーは、指定されたリソースが確保できるサーバーを探し出してタスクを割り当てます。この時、指定されたリソースは、このタスク専用に確保された形になります。つまり、このサーバーで利用できる空きリソースは、サーバー上のリソース全体から、起動中のタスクに割り当てられたリソースの合計を引いたものになります。
ここで問題になるのが、次の2つの点です。
(1) タスクが使用するリソース量を正確に見積もるのは難しく、エンジニアの判断で設定する場合、必要以上のリソースを割り当てがちになる。
(2) タスクが使用するリソース量は時間的に変動するため、常に割り当てられたリソースをすべて使用するわけではない。
これらはいずれも、タスクに割り当てたにも関わらず実際には使用されない「無駄なリソース」の増加につながります。(1)の問題については、Googleのデータセンターでは、第84回の記事で紹介した「Autopilot」によるチューニングが行われています。Autopilotでは、それぞれのタスクが実際に使用したリソース量を測定して、タスクが必要とするリソースの最大量を見積もった上で、リソースの割り当て量を1日に数回程度の頻度で定期的に更新します。そして、今回のテーマである「オーバーコミット」は、(2)の問題に対処する手法になります。サーバー上で多数のタスクが同時に稼働する場合、それぞれのタスクがリソースの最大使用量、すなわち「ピーク値」を取るタイミングには、ばらつきがあります。したがって、「個々のタスクに割り当てたリソースの合計」がサーバーの実際のリソース量を超えたとしても、すべてのタスクが同時にピーク値を取らなければリソース不足は発生しません。
たとえば、図1はGoogleのデータセンターで稼働するサーバー群について、ピーク時のCPU使用量の分布を調べたデータになります。まず、破線は、タスク単位でのデータです。横軸はピーク時の使用量(タスクに割り当てられたCPUを使い切った状態を1とする)を表しており、縦軸は「ピーク時の使用量が横軸の値以下のタスクの割合」を示します。これを見ると、ピーク時の使用量が90%以下(横軸が0.9)のタスクは、全体の40%程度(縦軸が約0.4)になります。言い換えると、60%程度のタスクは、ピーク時において割り当てられたCPUを90%以上使っていることになります。一方、実線は、サーバー単位のデータです。こちらの場合、横軸が0.7を超えたあたりで、縦軸が1.0に達しています。つまり、個々のサーバーで見ると、最大でも70%程度のCPUしか使っておらず、残りの30%の性能は無駄になっているという事です。
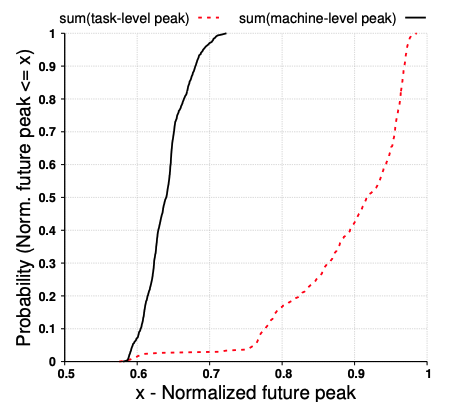
図1 サーバー単位、および、タスク単位でのピーク使用量の分布(論文より抜粋)
このような無駄を削減するために、スケジューラーに対して、一定の程度まではサーバーのリソース量を超えてタスクを起動することを許可する場合があります。スケジューラーのこのような動作を一般に「オーバーコミット」と呼びます。しかしながら、具体的にどこまでのオーバーコミットを許可するかは難しい問題です。万一、サーバーのリソースが不足した場合、タスクの強制停止(メモリーが不足した場合)や実行遅延(CPU実行時間が不足した場合)などの問題が発生します。冒頭の論文では、Googleのデータセンターにおけるタスクの稼働状況の過去データを用いたシミュレーションと「Peak Oracle」と呼ばれるユニークな考え方により、オーバーコミットを制御する複数のアルゴリズムについて、その性能を評価しています。
前述のように、(1)個々のタスクに割り当てるリソース量の最適化と、(2)サーバー全体でのオーバーコミットの最適化は異なる課題になります。この論文では (2)の最適化にフォーカスしており、サーバー全体でのリソース使用量のピークをできるだけ正確に見積もることを目標にしています。クラスター管理システムのスケジューラーは、適切なオーバーコミットを実現するために、この見積もり情報を元にして新たなタスクを追加で起動することを許可します。具体的には、サーバーの全リソースから、現時点での「サーバー全体でのリソース使用量のピーク値(の見積もり)」を引いた値が、新しいタスクに割り当てるリソースよりも大きければ、このタスクを受け入れることができます。論文の中では、このような「ピーク値の見積もりアルゴリズム」が実現できれば、Kubernetesなど、Borg以外のクラスター管理システムにも容易に適用できるだろうと説明されています。
今回は、2021年に公開された論文「Take it to the Limit: Peak Prediction-driven Resource Overcommitment in Datacenters」を元にして、サーバークラスターの「オーバーコミット」の考え方、そして、サーバー全体でのリソース使用量のピーク値を見積もることで、オーバーコミットの最適化が実現できることを説明しました。
次回は、「Peak Oracle」の具体的な考え方と、これを用いた最適化アルゴリズムの設計・評価の方法を解説します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































