
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Take it to the Limit: Peak Prediction-driven Resource Overcommitment in Datacenters」を元にして、サーバークラスターの「オーバーコミット」を最適化するアルゴリズムを解説します。今回は、「Peak Oracle」の考え方に基づいて、アルゴリズムを設計・評価する方法を説明します。
前回の記事で説明したように、サーバー上で稼働するタスク群において、個々のタスクがリソース使用量のピーク値をとるタイミングには「ずれ」があるため、サーバー全体でのリソース使用量の変化、そして、そのピーク値を正確に予測することはそれほど簡単ではありません。しかしながら、もしも、これを正確に予測するアルゴリズムが存在したとすれば、クラスター管理システムのスケジューラーは、理想的なオーバーコミットを実現することができます。具体的には、スケジューラーに対して、次のようなルールを組み入れます。
・サーバーの全リソースから、現時点での「サーバー全体でのリソース使用量のピーク値(予測値)」を引いた値が、新しいタスクに割り当てるリソースよりも大きければ、このタスクを受け入れる
冒頭の論文では、サーバー全体でのリソース使用量のピーク値を正確に予測する「完全なアルゴリズム」を「Peak Oracle」と表現しています。もちろん、現実にはこのようなアルゴリズムは存在しませんが、これを近似的に実現するアルゴリズムを用いて、上記のルールでオーバーコミットのシステムを作ろうというのが基本的なアイデアです。さらには、近似的なアルゴリズムによる予測と「Peak Oracle」による正確な予測を比較することで、近似的なアルゴリズムの性能を評価することもできます。「実際には存在しないPeak Oracleを用いた評価など不可能では?」と思うかも知れませんが、少なくとも、すでに結果が分かっている過去のデータについては、正確な予測を行うことが可能です。この論文では、Googleのデータセンターで収集したサーバークラスターの稼働データを用いて、近似アルゴリズムの予測に基づいたスケジューラーの判断に対して、その後の実際のリソース使用量の変化をシミュレーションすることで、近似アルゴリズムの性能評価を行っています。具体的には、データセンターのサーバークラスターに、近似アルゴリズムに基づいたオーバーコミットを適用したものと仮定して、その後のクラスターの稼働状況を(過去データに基づいて)シミュレーションします。
たとえば、論文の中には、図1のグラフを用いた説明があります。赤色の曲線は過去データに基づいたリソース使用量の正確な変化を表しており、これを用いると、リソース使用量のピーク値の正確な予測値(Peak Oracleによる予測)は、緑色の横線の値になります。一方、破線で示された横線は、近似アルゴリズムによる予測を表します。この予測は、実際よりも小さな値になっています。そのため、この予測に基づいて新しいタスクの追加を許可すると、追加後のリソース使用量のシミュレーション結果は紫色のラインになり、結果的にリソース不足が発生しています。
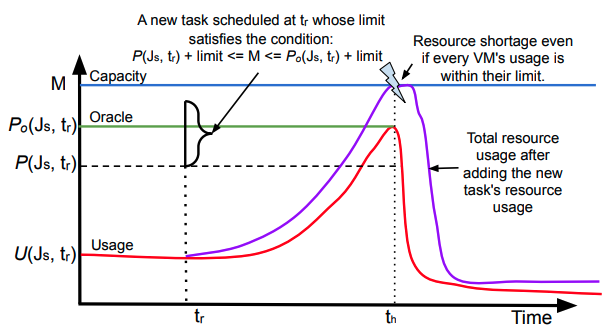
図1 リソース使用量のシミュレーションイメージ(論文から抜粋)
このようなシミュレーションを繰り返して次の3つの値を計算することにより、サーバー全体のリソース使用量を最大化しつつ、リソース不足の発生を許容範囲内に抑えられる近似アルゴリズムを設計(チューニング)しようというわけです。
・サーバー全体のリソース使用量の変化
・サーバー上でリソース不足が発生する回数
・リソース不足が発生した場合の不足量
なお、評価するべきリソースには、CPU使用時間とメモリー使用量がありますが、この論文では、CPU使用時間のみを調査の対象としています。
この論文では、次の3種類の近似アルゴリズムに対するシミュレーションを実施しています。
(1) Borg-default Predictor (borg-default)
(2) Resource Central-like Predictor (RC-like)
(3) N-sigma Predictor
(1)はBorgシステムがデフォルトで採用しているアルゴリズムに近いもので、単純に「現在稼働中のタスクに割り当てられたリソースの合計×P」をピーク値の予測とします。Pは、1より小さな値で、実際の稼働状況に応じてチューニングを行います。(2)は、稼働中の個々のタスクについて、過去のリソース使用量をモニタリングして、それぞれのタスクについて「上位(1-p)%を除いた最大使用量(つまり、下からp%の位置の使用量)」を計算した上で、これらの合計をピーク値の予測とします。この場合は、pの値がチューニング対象のパラメータとなります。(3)は、サーバー全体のリソース使用量をモニタリングして、過去の一定期間における平均と標準偏差を計算した上で、「平均+N×標準偏差」をピーク値の予測とします。ここでは、Nの値がチューニング対象のパラメータとなります。この後は、前述のシミュレーションを利用して、それぞれのアルゴリズムにおける適切なパラメーター値を決定する、あるいは、アルゴリズム同士の相互比較を行うといった流れになります。
今回は、2021年に公開された論文「Take it to the Limit: Peak Prediction-driven Resource Overcommitment in Datacenters」を元にして、「Peak Oracle」の考え方に基づいて、アルゴリズムを設計・評価する方法を説明しました。また、評価対象とする3種類のアルゴリズムも紹介しました。「Peak Oracle」の正確な予測を近似的に再現するという割には、シンプルなアルゴリズムにも思えますが、過去データを使ったシミュレーションによる実際の評価結果が気になるところです。次回は、実際の評価結果を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































