
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Take it to the Limit: Peak Prediction-driven Resource Overcommitment in Datacenters」を元にして、サーバークラスターの「オーバーコミット」を最適化するアルゴリズムを解説します。今回は、過去データを使ったシミュレーションによる評価結果、および、実環境に適用した場合の効果を示すデータを紹介します。
前回の記事では、「サーバー全体でのリソース使用量のピーク値」を予測するアルゴリズムを用いて、より最適なオーバーコミットを実現する方法を説明しましたが、その際に、予測アルゴリズムの具体例として次の3つを紹介しました。
(1) Borg-default Predictor (borg-default)
(2) Resource Central-like Predictor (RC-like)
(3) N-sigma Predictor
それぞれのアルゴリズムにはチューニング対象のパラメーターが含まれているため、実際の性能を評価するには、これらのパラメーターを決定しておく必要があります。まず、(1)は、「現在稼働中のタスクに割り当てられたリソースの合計×P」をピーク値の予測とするものでしたが、論文内では、具体例としてP=0.9という設定を用いています。図1は、Googleのデータセンターで稼働するタスクについて、実際のリソース使用量(CPU使用時間)を調査した結果ですが、大多数のクラスター(cell)において、横軸(割り当て量に対する実際の使用量の割合)が0.9のところで、縦軸(タスクの割合)が1.0に近くなっています。つまり、実際のリソース使用量が割り当て量の90%を超えることはほとんどなく、P=0.9という設定は十分に妥当であるとわかります。
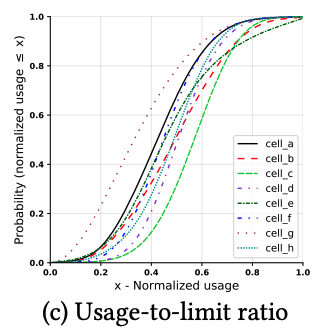
図1 タスクごとのリソース使用量の分布(論文より抜粋)
(2)は、稼働中の個々のタスクについて、過去のリソース使用量をモニタリングして、それぞれのタスクについて「上位(1-p)%を除いた最大使用量(つまり、下からp%の位置の使用量)」を計算した上で、これらの合計をピーク値の予測とします。論文内では、さまざまなpの値について、アルゴリズムの性能がどのように変化するかを測定した結果が図2のように示されています。
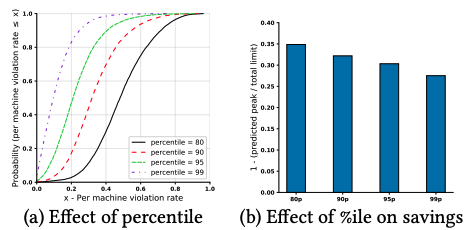
図2 Resource Central-like Predictorの性能評価(論文より抜粋)
図2の左のグラフの横軸は、「Violation rate」と呼ばれる値です。これは、一定の時間間隔で「サーバー全体でのリソース使用量のピーク値」を予測して、その予測値がその後に実際に発生するピーク値よりも小さかった場合の割合を表します。つまり、この値が大きいほど、想定外のリソース不足が発生する危険性が高くなります。縦軸は、クラスターに含まれる多数のサーバーの中で「Violation rateが横軸の値以下であるサーバーの割合」を表します。例えば、80%以上のサーバーでVioration rateを20%以下に抑えたければ、p(percentile)=99%と設定する必要があることがわかります。そして、図2の右のグラフは、4種類のpの値について、(オーバーコミットを適用しない場合に比べて)利用可能なリソースがどの程度増えるかを示します。実際にパラメーターをチューニングする際は、Vioration rateを許容可能な値に抑えた際に、リソース使用量がどの程度増えるかを評価することになります。
(3)は、サーバー全体のリソース使用量をモニタリングして、過去の一定期間における平均と標準偏差を計算した上で、「平均+N×標準偏差」をピーク値の予測とします。論文内では、さまざまなNの値について、アルゴリズムの性能がどのように変化するかを測定した結果が図3のように示されています。グラフの見方は、図2と同じです。
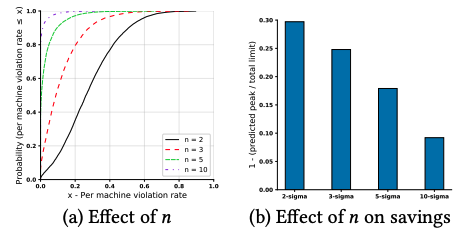
図3 N-sigma Predictorの性能評価(論文より抜粋)
この論文では、さらに、2種類のアルゴリズムを組み合わせた場合のシミュレーション結果が示されています。具体的には、(2)(3)のそれぞれのアルゴリズムでピーク値を予測して、値が大きい方を実際の予測値として採用します。それぞれのアルゴリズムを単独で用いる場合よりも、より安全側に振った予測結果が得られることになります。詳細な分析は論文に譲りますが、結論としては、(2)(3)のパラメーターをそれぞれp=99%、および、N=5に設定した場合に(単独のアルゴリズムを用いる場合よりも優れた)最適な結果が得られたということです。具体的な評価結果は、図4のようになります。ここでは、複数のクラスター(cell)に対する結果が個別に示されており、左のグラフがVioration rateで、右のグラフが使用可能なリソースがどの程度増えるかの割合を示します。
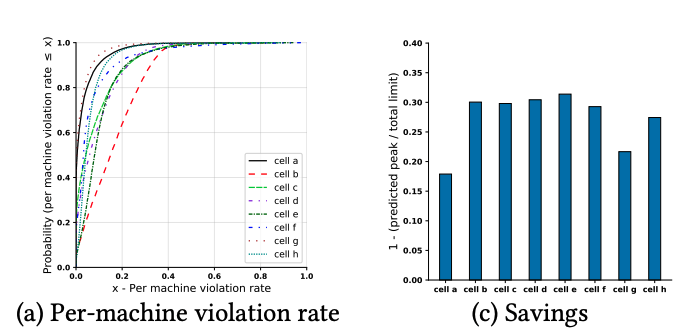
図4 アルゴリズムを組み合わせた際の性能評価(論文より抜粋)
そして最後に、このアルゴリズムの組み合わせを用いたシステムを実環境のスケジューラーに適用した際の実験結果が示されています。既存で使用しているBorgのデフォルトスケジューラーよりも優れた性能が得られるものと期待されますが、具体的な実験結果は図5のようになります。
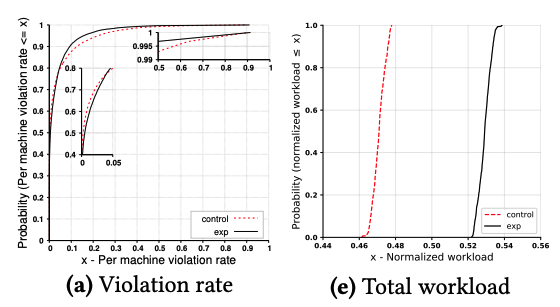
図5 実環境での性能評価(論文より抜粋)
図5の左のグラフはViolation rateで、右のグラフは各サーバーのCPU使用率を表します。それぞれのグラフにおいて、「control」がデフォルトスケジューラーにおける結果、「exp」が新しいシステムを適用した際の結果を示します。ここでは特に、「デフォルトスケジューラーと同等のViolation rateが得られる」という条件で各アルゴリズムのパラメーターをチューニングしておき、その結果、CPU使用率がどの程度向上するかを検証しています。右のグラフから分かるように、CPU使用率は6%程度増加しており、サーバー上でより多くのタスクを実行できていることになります。
今回は、2021年に公開された論文「Take it to the Limit: Peak Prediction-driven Resource Overcommitment in Datacenters」を元にして、サーバークラスターの「オーバーコミット」を最適化するアルゴリズムについて、過去データを使ったシミュレーションによる評価結果、および、実環境に適用した場合の効果を示すデータを紹介しました。個々のアルゴリズムは比較的シンプルなものですが、2つのアルゴリズムを組み合わせることでより最適な結果が得られるというのは、面白いポイントかも知れません。性能評価の結果を示すグラフをいくつか引用して紹介しましたが、論文ではより多くのデータが示されているので、興味のある方はぜひ実際の論文も参照してみてください。
次回は、機械学習の中でも最近注目を集める「Explainable AI」に関する話題をお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































