
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2021年に公開された論文「Acquisition of Chess Knowledge in AlphaZero」を元にして、強化学習を適用したニューラルネットワークの「学習内容」を分析するという研究事例を紹介します。今回は、「学習の過程」に対する分析例を紹介します。
前回までは強化学習による学習処理が終わった状態のニューラルネットワークを分析してきました。今回は、学習の過程において、機械学習モデルが習得した知識がどのように変化するかを分析します。この論文では、第123回の記事の図1に示した機械学習モデルを用いていますが、このモデルには多数のパラメーターが含まれており、学習データを用いてこれらのパラメーターをチューニングしていくことになります。この際、人間のプレイヤーが対戦した際の棋譜データを学習データとすることも可能ですが、AlphaZeroでは、このような棋譜データは使用しません。学習対象の機械学習モデル同士を自動対戦させることで得られた棋譜データを用いて学習を行います。機械学習モデルに含まれるパラメーターは乱数で初期化されるため、学習の初期においてはお互いに出鱈目な手を打ち合うため、まともな棋譜データにはなりませんが、それでも何らかの形で勝敗は決定します。そのようにして得られた棋譜データを用いることで、「何をすれば勝てるのか」「何をすれば負けるのか」ということを少しづつ学んでいきます。学習が進むにつれて徐々に「まともな手」を打てるようになるので、自動対戦で得られる棋譜データの品質がよくなり、さらに学習が進むものと期待ができます。
それでは、実際の学習過程では、このような期待通りの変化が本当に得られるのでしょうか。この論文では、一例として、対戦の一番初めに打つ「初手」の傾向がどのように変化するかを調べています(図1)
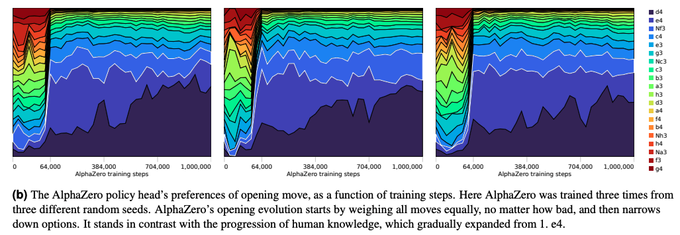
図1 学習が進むにつれて「初手」の傾向が変化する様子(論文より抜粋)
図1には、3種類のグラフが示されていますが、これは、異なる乱数で初期化した3種類の学習過程に対応します。グラフ内の異なる色は、それぞれ異なる手に対応します。これを見ると、学習の初期は、初手として可能な20種類のすべての手をほぼランダムに選択していることがわかります。その後、64,000ステップあたりまで学習が進むと、突然、初手に選ぶ手の傾向が変化します。チェスの棋譜記号で表すと、「d4」「e4」「Nf3」「c4」などの手が主に選択されるようになっています。単純に「より良い手を少しづつ学んでいく」というわけでなく、学習過程のあるタイミングで、学習内容に大きな変化を引き起こしていることが読み取れます。
それでは、AlphaZeroの機械学習モデルが学んだこれらの手は、人間のプレイヤーが打つ手とどのような関係にあるのでしょうか? 論文の中では、西暦1400年ごろから現在にいたるまでのプロ棋士の棋譜データを元にして、初手の傾向がどのように変化したかが示されています(図2)。
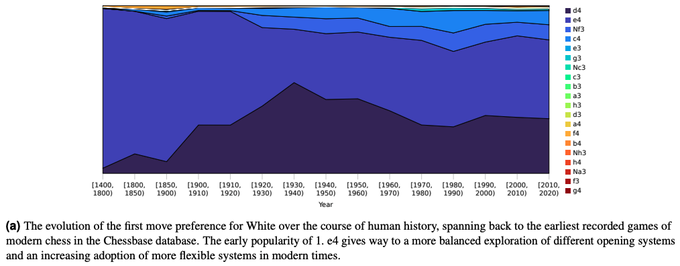
図2 初手の傾向の歴史的変化(論文より抜粋)
これを見ると、歴史と共に人間のプレイヤーが打つ手も変化していることが分かります。チェスの歴史が始まったころは、初手は「e4」で始めるのがほぼ常識でしたが、その後、「d4」も良い手であることが発見されています。さらに現代に近づくと、「Nf3」「c4」など、これら以外の手も含めたバリエーションが少しづつ広がっていきます。チェスの世界では、長い歴史をかけて、新しい定石が発見されてきたことが分かります。一方、これを先ほどの図1と比較すると、AlphaZeroの場合は、あるタイミング(64,000ステップあたり)で、これらのバリエーションを含めた幅広い手を一度に発見していることが読み取れます。
ここまで、AlphaZeroの機械学習モデルで指す「初手」の変化をみてきましたが、初手に続く打ち手についてはどのようになるでしょうか? 論文の中では、「ルイ・ロペス」と呼ばれる定番のオープンニングへの対応が分析されています。ルイ・ロペスというのは、先手が3手目を打つまでの「1. e4 e5 2. Nf3 Nc6 3. Bb5」という流れで、チェスの歴史が始まってから現代まで、数多く指されているオープンニングの流れです。ここでは、この後の展開に注目します(図3)。
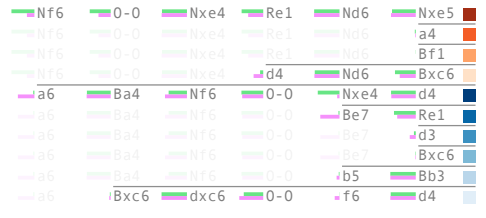
図3 ルイ・ロペス以降の展開パターン(論文より抜粋)
図3には、後手が3手目を打った後、先手が6手目を打つまでのパターンが10通り示されており、上の4種類は学習済みのAlphaZeroが最も良く打つパターン(上位4種類)で、その下の6種類は過去30年間にグランドマスター(チェス棋士の最高位タイトル保持者)が最も良く打ったパターン(上位6種類)になります。これを見ると、AlphaZeroの機械学習モデルと人間のプレイヤーには明確な差異が見受けられます。後手の3手目において、グランドマスターは「a6」を選択し、一方、AplhaZeroの機械学習モデルは「Nf6」を選択するという違いがあります。実は、「Nf6」という選択は「ベルリン・ディフェンス」と呼ばれる定石で、チェスの歴史においては、近代になってから発見されたものになります(図4)。
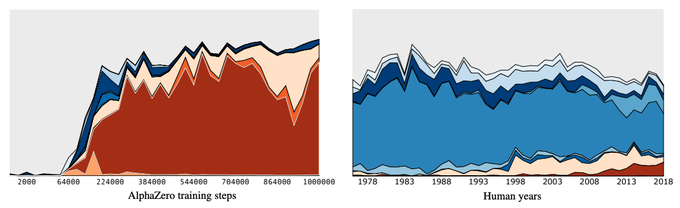
図4 ルイ・ロペス以降の展開パターンの変化(論文より抜粋)
図4の右はグランドマスターの打ち手の変化を表しており、1900年代後半以降に、ベルリン・ディフェンスを選択する割合が徐々に増えていることが分かります。一方、図4の左は、学習過程におけるAlphaZeroの機械学習モデルの打ち手の変化を示します。先ほどの図1では、64,000ステップあたりで一気に学習が進んでいましたが、こちらも同様で、64,000ステップを超えたところで、ベルリン・ディフェンスを中心とした展開パターンを学んでいることが分かります。これらの結果を見ると、強化学習による学習過程は、人間が歴史を通して定石を発見しながら新しい打ち手を学んできた様子とは異なることが理解できます。人間のプレイヤーはそれぞれの時代における「常識」に考え方が縛られる一方、強化学習による学習過程では、常識に縛られることなく、あくまでも合理的に学習を進めていると考えられるのかも知れません。
今回は、2021年に公開された論文「Acquisition of Chess Knowledge in AlphaZero」を元にして、強化学習を適用したニューラルネットワークの「学習内容」に関する研究事例に関して、「学習の過程」に対する分析例を紹介しました。これまでに紹介した分析内容を振り返ると、いずれも明確な結論が得られるものではありませんでしたが、これまでブラックボックスと言われていたニューラルネットワークの構造、あるいは、「機械学習モデルは、どのような過程で何を学んでいるのか?」という点について、さまざまな気づきが得られる内容と言えるでしょう。
次回は、クラウドインフラのモニタリングシステムを支える分散グローバルデータストアの話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































