
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2020年に公開された論文「Monarch: Google's Planet-Scale In-Memory Time Series Database」を元にして、Google社内で利用されているモニタリングシステム専用の時系列データストア「Monarch」のアーキテクチャーを紹介します。今回は、Monarchのアーキテクチャー概要とデータモデルについて説明します。
Monarchは、YouTube、Gmail、Google Mapsなど、Googleが提供するさまざまなサービスが共通に利用しているモニタリングシステムのバックエンドとなるデータストアです。次のブログ記事で紹介されているように、Google CloudのモニタリングサービスであるCloud Monitoringのバックエンドにも同じ仕組みが利用されています。
・Managed Service for Prometheusで世界規模のモニタリングを実現
Cloud Monitoringを利用すると、仮想マシンのリソース使用量から始まり、アプリケーションに対するアクセス数やレスポンスタイムなど、さまざまなレイヤーのモニタリングデータをリアルタイムに収集できます。これらのデータを保存して、検索可能にすることがMonarchの役割です。Google社内には、Google Cloudのバックエンドとは別に社内システム専用のMonarchが用意されており、複数のプロジェクトが共有サービスとして利用しています。冒頭の論文では、このようなGoogle社内での利用形態を前提とした解説がなされており、1秒間にテラバイト単位のデータ保存と数百万件のデータ検索が行われているなど、興味深いデータが公開されています。
Monarchのシステムは、複数のゾーン(地理的に分散したデータセンター)にデータを分散保存するように設計されており、全体のアーキテクチャーは、図1のようになります。
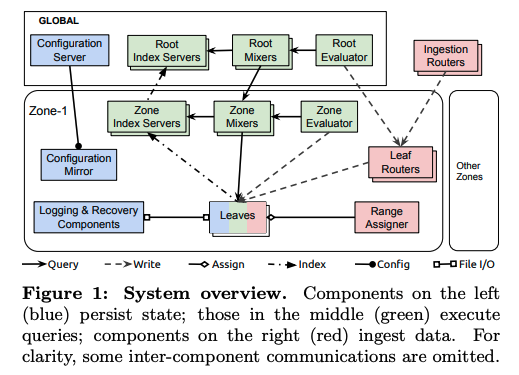
図1 Monarchのアーキテクチャー概要(論文より抜粋)
データを保存する経路は、図1の赤色で示されたコンポーネントが担います。Monarchのクライアントが送信したデータは、複数のゾーンに配置された「Leaf(Leaves)」に分散保存されますが、基本的には、送信元から地理的に近い位置にあるゾーンのLeafへと転送されます。具体的に説明すると、Monarchに保存するデータは、データを生成したコンポーネントやデータの種類を示す「キー」と実際の時系列データ(タイムスタンプとデータ値の組)を示す「バリュー」がペアになっており、キーに含まれる値によって保存先のLeafが決まります。対象コンポーネントからデータを取得したMonarchのクライアントは、まずは、複数のロケーションに配置された「Ingestion Router」のどれか1つにデータを送信します。Ingestion Routerは、キーの情報(この後で説明する「ロケーション」フィールド)から転送先のゾーンを決定して、該当ゾーンの「Leaf Router」にデータを転送します。さらに、Leaf Routerは、ゾーン内に複数ある「Leaf」の中から(冗長保存のために)標準で3つのLeafを選択して、データを転送するという流れになります。
ゾーン内でデータを保存するLeafの選択は、データのキー(正確には、この後で説明する「ターゲット」の値)によって行われます。キーとLeafの対応関係は、各ゾーンで稼働している「Range Assigner」が決定して、それぞれのLeafに通知します。さらにこの情報は、LeafからLeaf Routerへとアナウンスされます。キーとLeafの対応関係は固定的なものではなく、それぞれのLeafへのアクセス量に偏りが生じた際は、動的にデータの再配置が行われます。再配置の仕組みについては、次回に改めて解説します。
保存データのキー・バリュー構造の例として、論文では、図2の例が示されています。
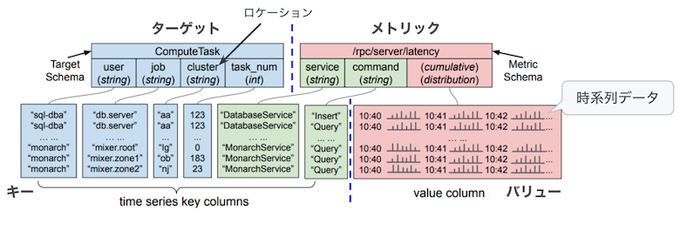
図2 Monarchに保存するデータのキー・バリュー構造の例(論文の図にコメントを追加)
図2の最上段は、Monarchのクライアントが送信するデータの構造を表しており、前半の「ターゲット」部分と後半の「メトリック」部分に分かれます。ターゲットはデータ収集対象のコンポーネントを表しており、メトリックは該当のコンポーネントから収集するデータ項目を表します。
図2の例では、ターゲット部分に「Compute Task」が定義されており、これはデータ収集対象のタスク(コンテナ)を表します。この部分にはタスクが稼働するクラスターの情報などが含まれており、ここからデータを転送するべきゾーン(物理的に近いゾーン)が判別できます。一般には、「ロケーション」として指定される特定のフィールドの値から転送先のゾーンが決まるようになっており、図2の例では「cluster」フィルードがこれに当たります。一方、メトリック部分には「/rpc/server/latency」という記載があります。これは、ターゲットで指定されたタスクが複数のAPIサービスを提供しており、サービス、および、コマンドごとにAPIリクエストに対するレイテンシーの情報を収集するという場合の構成例です。この例では、サービス「DatabaseService」に対する「Insert」処理のレイテンシー情報などが含まれています。
後半のメトリック部分は、データ項目を表す部分(緑色の部分)と実際のデータの値を表す部分(赤色の部分)に分かれていますが、Leafが該当データを保存する際は、青色部分(ターゲット)と緑色部分(メトリックのデータ項目を表す部分)を結合したものが「キー」になり、最後の赤色部分(実際のデータ値の部分)が「バリュー」という扱いになります。バリューの中身はタイムスタンプを伴う時系列データになっており、複数の時刻におけるデータがまとめて保存されます。時刻ごとに行を分けて保存するわけではありません。
また、先ほど、キーの値によって保存先のLeafが決まると説明しましたが、青色のターゲット部分の値を辞書順にソートした上で、その値の範囲によってLeafが分けられます。言い換えると、ターゲットの辞書順のレンジでシャーディングが行われるようになっており、ターゲットの内容が同一のデータは、必ず、同じLeafに保存されます。保存データの検索処理を行う際は、特定のターゲット、もしくは、値が連続する複数のターゲットに対するデータをまとめて取得することが多いため、このようにすることで、単一のLeafからまとめてデータを取得することが可能になります。複数のLeafから集めたデータを結合する処理が削減されるので、検索処理速度の向上に繋がります。保存データの検索処理は、図1の緑色のコンポーネントが担いますが、具体的な検索処理の流れについては、次回以降に改めて解説を進めます。
なお、バリューとして保存可能なデータ型は、boolean、int64、double、string、distribution、および、これらをまとめたタプル型です。distribution(分布)型は、double型のデータをヒストグラムの形式でまとめたもので、値の範囲を区切ったバケットとそれぞれのバケットに含まれるデータ数から構成されます。
今回は、2020年に公開された論文「Monarch: Google's Planet-Scale In-Memory Time Series Database」を元にして、Google社内で利用されているモニタリングシステム専用の時系列データストア「Monarch」について、アーキテクチャーの概要とデータモデルを紹介しました。次回は、各Leafがデータを保存する仕組みと、動的なデータの再配置について説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































