これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2020年に公開された論文「Monarch: Google's Planet-Scale In-Memory Time Series Database」を元にして、Google社内で利用されているモニタリングシステム専用の時系列データストア「Monarch」のアーキテクチャーを紹介します。今回は、データ保存処理の詳細を解説します。
前回の記事で説明したように、Monarchに収集されたデータは、Leafと呼ばれるノードに分散保存されます。大量のデータを高速に検索する必要があるため、Leafが保持するデータはすべてメモリー上に保存されます。ただし、障害時にデータを失わないよう、ディスク上の追記型のリカバリーログにも同じデータが保存されます。この後で説明するように、リカバリーログは、データの動的な再配置を実施する際にも利用されます。
リカバリーログそのものも冗長化のために3カ所以上に保存されますが、これらのリカバリーログの書き込みは非同期に行われます。つまり、それぞれのLeafは、リカバリーログの書き込み完了を待たずに処理を継続していきます。これには、高速にデータを受け取り続けることに加えて、ディスクストレージシステムの障害の影響を回避するという目的があります。Monarchでは、ディスクストレージのバックエンドに分散ファイルシステムのColossusを使用しており、ColossusそのもののモニタリングにもMonarchが使用されています。そのため、Colossusの障害がMonarchの動作に影響を与えてしまうと、Colossusのモニタリングという役割が果たせなくなります。前述のように、Monarchはリカバリーログの書き込み完了を待たずに処理を継続するので、Colossusに障害が発生してもMonarchの処理が止まることはありません。
また、メモリー上にデータを保存する際は、ターゲット(前回の図2を参照)が同一のデータでタイムスタンプ情報を共有したり、distribution型(ヒストグラム形式のデータ)などの複雑なデータ構造については、直前のデータとの差分を保存するといった最適化が行われます。一般的なデータ圧縮については、処理速度を優先するために、処理が高速で圧縮率の低いアルゴリズムを使用しています。
前回説明したように、データを保存するLeafは、データの送信元を表すターゲットの辞書順のレンジによって振り分けられます。この時、前回の図1にある「Range Assigner」は、それぞれのLeafが受け取るデータ量やCPU使用率に応じて、各Leafに割り当てるレンジを調整します。レンジの割り当てが変更された場合、Leaf間でのデータの再配置が必要になりますが、次のような流れにより、データ収集を中断することなく再配置が行われます(図1)。
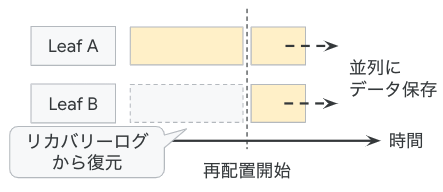
図1 データの動的再配置の流れ
たとえば、あるターゲットのデータの受け取り先がLeaf AからLeaf Bに変わったとします。この時、Range Assignerは、このターゲットのデータの転送先にLeaf Bを加えて、Leaf AとLeaf Bが同じデータを収集する状態にします。その後、Leaf Bは、Leaf Aが保存したリカバリーログを用いて、過去のデータを自身のメモリー上に再構成します。再構成処理が終わって、Leaf AとLeaf Bが同一のデータを保持する状態に到達したところで、Leaf Aに対するデータ転送を停止します。この仕組みであれば、過去データを再構成中のLeaf Bに問題が発生した場合でも、Leaf Aはこれまで通りにデータを受け取り続けることができます。
Monarchが収集するデータは、基本的には、ターゲットごとに分けて保存されますが、複数のターゲットからのデータを集約することも可能です。たとえば、ディスクのI/O数(IOPS)のデータを収集する場合、個々のディスク装置が個別のターゲットになりますが、膨大な数のディスクのデータを個別に収集するというのは、データ量の観点からあまり現実的ではありません。実際には、クラスターに含まれるすべてのディスクに対する総I/O数が分かれば十分という場合もあります。このような場合、複数のターゲットから送信されるデータを集約して、その合計値を保存するといった設定ができます。特に、ディスクI/O数などのカウンタータイプのメトリックは、「一定期間の総数」という形式で保存することが推奨されます。この形式の場合、データを送信するターゲット側のクライアントは、一定期間のデータを集約してから送信することが可能になります。
これは、具体的には、次のような仕組みになります。それぞれのターゲットのクライアントは、一定期間(TD秒間)のI/O数をカウントして、その総数をTD秒ごとにMonarchに送信します。通常、TDは10秒に設定されます。一方、このデータを受け取ったMonarchは、同一のクラスターに属するターゲットからのデータをさらに集約して保存します(図2)。
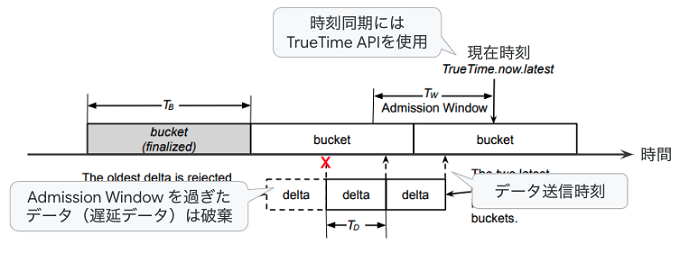
図2 複数ターゲットのデータ集約の仕組み(論文の図にコメントを追加)
図2では、「delta」と示された1つの箱がクライアントから送信された(TD秒間の)カウント数になります。複数のクライアントから同様のデータが送られてきますが、これらをより長い時間間隔(TB秒間)で足し上げて、得られた結果を保存する形になります。図2の「bucket」という1つの箱がTB秒間の総数になります。ここでは、「delta」に含まれるデータの末尾の時刻(カウントを終了してデータを送信した時刻)によって、対応する「bucket」が決まるようになっています。また、クライアントからのデータが届くまでに何らかの理由で大きな遅延が発生する可能性がありますが、一定期間よりも古いデータは「bucket」に加えずに破棄します。この処理を行わなければ、それぞれの「bucket」の値が永遠に確定しなくなるからです。図2の「Admission Window」で示された範囲が、現時点で「受付中」の時刻範囲を示します。この際、クライアント側の時刻情報とMonarchのそれぞれのLeafが持つ時刻情報に大きな誤差があると、正確な集計ができなくなります。そのため、各クライアントとLeafは、Googleが独自開発した「TrueTime API」を用いて、一般的な時刻サーバーよりもさらに正確な時刻同期を行っています。TBの値は、1〜60秒の範囲で設定が可能です。また、実環境では、平均的に30個程度のターゲットを集約する設定が用いられますが、極端なケースでは、100万を超えるターゲットのデータを1つに集約する場合もあるということです。
今回は、2020年に公開された論文「Monarch: Google's Planet-Scale In-Memory Time Series Database」を元にして、Google社内で利用されているモニタリングシステム専用の時系列データストア「Monarch」について、データ保存処理の詳細を解説しました。次回は、データ検索処理の仕組みを解説した上で、実環境における稼働状況を示すデータを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































