
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2020年に公開された論文「Monarch: Google's Planet-Scale In-Memory Time Series Database」を元にして、Google社内で利用されているモニタリングシステム専用の時系列データストア「Monarch」のアーキテクチャーを紹介します。今回は、データ検索処理の仕組みを解説した上で、実環境における稼働状況を示すデータを紹介します。
Monarchに保存したデータはさまざまな方法で検索することができますが、Google社内では、主に、図1に示すような独自のクエリー言語で検索を実行します。第127回の記事の図2に示したように、Monarchに保存されるデータはキー・バリュー構造を持っています。このキーの部分に含まれるフィールド値を用いて、フィルタリングやグループ化(group_by)など、リレーショナルデータベースの検索に類似の処理を実施する事ができます。

図1 Monarchのクエリーと検索結果の例(論文より抜粋)
図1の例では、タスクごとのビルドラベル(コンテナイメージのイメージIDに相当するラベル)を保存したテーブルと、タスクごとのレイテンシーの分布を保存したテーブルを結合(Join)して、ビルドラベルごとにレイテンシーの分布を集計するという処理を行っています。具体的には、「mixer」で始まる同一のビルドラベルを持つすべてのタスクについて、レイテンシーの分布を集約しています。特定のビルドだけレイテンシーの分布が大きく変化していた場合、そのビルドに何らかの問題があるかも知れない、といった判断に用いる想定です。また、図1の下部には検索結果のイメージが示されています。この例では、1分ごとのデータが表示されていますが、それぞれのデータは、示された時刻から過去1時間に渡るデータの分布になっており、いわゆる「スライディング・ウィンドウ」を用いた集計が行われています。
Monarchに対して行う検索には、エンジニアやアナリストがデータ分析のために手動で行うアドホック・クエリーと、マテリアライズド・ビューを作成するために事前定義しておく継続クエリーがあります。継続クエリーはバックグラウンドで定期的に実行され、得られた結果は独立したビューとして保存されます。このようなビューを作成する目的は、2つあります。1つはモニタリングダッシュボードに表示するためのデータを事前に用意することで、もう1つは、得られた結果を用いたアラートを設定することです。
実際のデータ検索処理は、図2の緑色のコンポーネントによって行われます。前述の継続クエリーについては、「Root Evaluator」もしくは「Zone Evaluator」が定期的に検索を実行して、結果をビューに保存します。特定ゾーンのデータのみが検索対象になると分かっている場合は、該当ゾーンのZone Evaluatorが使用されます。ここでは、Root Evaluatorが検索処理を実行する場合で説明します。なお、「Zone Evaluator」と「Root Evalutator」は、複数用意されており、検索文全体のハッシュ値によるロードバランスが行われます。
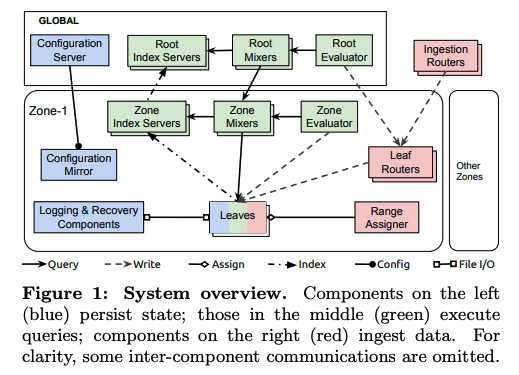
図2 Monarchのアーキテクチャー概要(論文より抜粋)
まずはじめに、Root Evaluatorは、Root Mixerに検索文を送信します。検索文を受け取ったRoot Mixerは、検索文の最適化やセキュリティチェックなどを行った後、それぞれのゾーンのZone Mixerに該当ゾーンに含まれるデータの検索を依頼します。さらに、それぞれのZone Mixerは、「Index Server」を参照して検索対象のデータを持つLeafを特定した後、それぞれのLeafに検索処理を送ります。この時、同一のデータが冗長化のために複数のLeafに保存されていることを利用して、Zone Mixerは、選択するLeafの最適化を行います。具体的には、Index Serverで発見したそれぞれのLeafに対して、保持しているデータの範囲(ターゲットの値の範囲)やデータの保存状況(データの再配置処理が実行中でないかなど)を問い合わせます。得られた結果を元にして、データの範囲ごとに取得するLeafを決定していきます。
最後に、それぞれのLeafは、問い合わせ対象のデータを取得して、Leaf内で実行可能な範囲でフィルタリングやグループ化の処理を行った後、得られた結果をZone Mixerに返します。Zone Mixerは、それぞれのLeafから得られた結果を総合してRoot Mixerに返します。最後に、Root Mixerが全体の結果を総合して検索処理が完了します。
先ほど、「Zone Mixerは、Index Serverを参照して検索対象のデータを持つLeafを特定する」と説明しました。具体的には、検索対象データのキーに含まれるフィールドの値を指定すると、対応するデータを保持するLeafのリストが得られます。この時、フィールドに含まれる値(文字列)には膨大な種類がある一方、高速に処理を行うためにすべてのインデックス情報をメモリー上に保持する必要があります。そこで、MonarchのIndex Serverでは、フィールドに含まれる値(文字列)を3文字ごとに分割してインデックス化するというユニークな処理を行います。たとえば、"mix" という3文字の文字列を考えて、「フィールドの値(文字列全体)の部分文字列として"mix"を含む」という条件にマッチするLeafのリストを構成します。この場合、フィールドに「mixer.zone1」という値を持つデータを保持するLeafは、このリストに含まれることになります。これをアルファベットのあらゆる3文字の組み合わせについて行えば、「26×26×26」個のリストが得られます。厳密には、大文字・小文字、行頭・行末記号などを含めた組み合わせを考えるので、実際のリストの数はもう少し大きくなりますが、Index Serverが保持する情報は、基本的にはこれだけです。
それでは、この情報からどのようにして検索を行うのでしょうか? 一例として、「mixer.*」という正規表現でのフィルタリングが行われた場合を考えます。これは、「mixer」で始まる任意の文字列を意味しますので、"^^m"、"^mi"、"mix"、"ixe"、"xer" (「^」は文字列の先頭を表す記号)という5種類の条件すべてにマッチするLeafを選択すれば、該当データを保持するすべてのLeafを洗い出すことができます。厳密には「min-mixer」など、それ以外の文字列にもマッチしますが、先ほど説明したように、発見したそれぞれのLeafに対して実際に保持しているデータを問い合わせる処理が行われるので、この点は問題にはなりません。この方法で構成したインデックス情報は、数GBのサイズに収まるということです。
最後にGoogle社内での実環境における稼働状況を示すデータを紹介します。これらは、2019年時点でのデータになります。まず、先ほどの図2に示したコンポーネントは、それぞれがコンテナによるタスクとして稼働しており、具体的なタスク数(コンテナ数)は、図3のようになります。
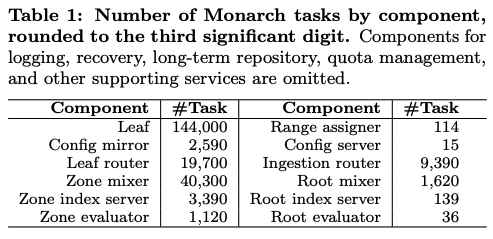
図3 Monarchを構成するコンポーネントのタスク数(論文より抜粋)
システム全体は38のゾーンに分散配置されており、それぞれのゾーンは1,000〜10,000程度のLeafを持ちます。10,000以上のLeafを持つゾーンは6カ所あります。全体として、1秒間に約2.2TBのデータが収集されており、メモリ上に保持するデータの総量は約750TBになります。ここには、約9,500億種類の時系列データが含まれます。また、1秒間に約600万回の検索処理を実行しており、その大部分(約95%)は、事前に定義された継続クエリーになります。前述のように、これらの継続クエリーは、モニタリングダッシュボードに表示するためのビューの作成、および、アラートの生成に利用されています。検索の実行時間は、システム全体の中央値で79ミリ秒、99.9パーセンタイルで6秒になりますが、数百万種類のデータを集約する複雑なクエリーでは、50秒に達する場合もあるということです。
今回は、2020年に公開された論文「Monarch: Google's Planet-Scale In-Memory Time Series Database」を元にして、Google社内で利用されているモニタリングシステム専用の時系列データストア「Monarch」について、データ検索処理の仕組みを解説した上で、実環境における稼働状況を示すデータを紹介しました。実環境での稼働状況については、論文内にさらに詳しいデータが掲載されていますので、興味のある方は、ぜひ論文も参照してください。
次回は、リモート・ダイレクトメモリアクセス(RDMA)を利用した分散キャッシングシステムの話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































