
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2022年に公開された論文「Pathways: Asynchronous Distributed Dataflow for ML」を元にして、Googleのエンジニアが開発した、機械学習モデルの新しい分散学習インフラ「Pathways」を紹介します。今回は、最近の機械学習モデルの研究・開発の動向から、Pathwaysが必要とされる背景を説明します。
この論文では、分散学習インフラとしてのPathwaysのアーキテクチャーが説明されていますが、これとは別に機械学習モデルとしての「Pathways」という考え方があります。これは、次のBlog記事で紹介されているもので、さまざまな役割を持つ機械学習モデルの「ブロック」を相互接続することで、複数のタスクに対応した機械学習モデルを構成しようというアイデアです。
・Introducing Pathways: A next-generation AI architecture
最近の機械学習モデルでは、画像とテキスト文書など、複数の形式のデータを取り扱うものが増えています。このようなモデルでは、画像から特徴量を抽出するコンポーネントやテキスト文書を処理するコンポーネントなど、それぞれのデータ形式に応じたコンポーネントが用意されており、これらから出力された特徴量を目的に合わせて処理していくという構成がよく見られます。この場合、前段のコンポーネントは、目的のタスクに特化したものではなく、複数のタスクに対応した汎用的なコンポーネントとして利用できる可能性があります。上記のBlogではここまで詳しくは説明されていませんが、このような汎用的なコンポーネントを「ブロック」として組み合わせることで、複数タスクに対応したモデルを構成しようというアイデアのように思われます。
次回の記事で説明するように、冒頭の論文で紹介されている分散学習インフラとしてのPathwaysは、このような複数タスクに対応した機械学習モデルを効率的に学習するための仕組みとして利用できるものと期待されています。
分散学習インフラとしてのPathwaysが必要とされるもう1つの要因として、機械学習モデルのサイズが大きくなり続けるという傾向があります。特に、テキスト文書を扱う自然言語モデルでは、モデルの基本構造が同じであれば、モデルサイズが予測性能により大きな影響を与えるという経験則が知られており、より高性能なモデルを実現するために、今後もさらに大きなサイズのモデルの開発が継続すると予想されます。
そして、そのためには、より大きなモデルを効率的に学習するためのインフラが重要となります。たとえば、Googleでは、独自に開発した機械学習専用のプロセッサーであるTPUを用いた学習環境を使用しており、この環境はGoogle Cloudでも利用可能になっています。TPU Podと呼ばれる構成の場合は、図1に示すように、インターコネクト(高速内部接続線)で相互接続された複数のTPUボードを使用した分散学習処理環境が利用できます。

図1 Cloud TPU(TPU Pod)のアーキテクチャー(Cloud TPUの公式ドキュメントより引用)
それぞれのTPUボードは個別のTPUホストに接続されており、1つのTPUボードには4つのTPUチップが搭載されています。さらに、1つのTPUチップには2つのTPUコアが搭載されているので、1台のホストに8個のTPUコアが接続されていることになります。TPUコアに対する計算処理の命令は、TPUホスト上のプログラムから投入されますが、計算に必要なデータは、インターコネクトを介してTPUコア同士で直接にやりとりすることができます。Google社内では、多数のTPUボードを相互接続した大規模なTPU Podを使用しており、次のBlog記事では、4,096個のTPUチップを相互接続した構成が紹介されています。
・Google showcases Cloud TPU v4 Pods for large model training
また、複数のTPUコアで機械学習モデルの学習を行う際は、モデル並列、および、データ並列と呼ばれる手法が用いられます。モデル並列では、機械学習モデル(ニューラルネットワーク)を構成する各コンポーネントを異なるTPUコアに割り当てることで、複数のTPUコアによる並列計算を行います。データ並列では、同一のモデルのコピーを複数のTPUコアに割り当てておき、学習データの複数のバッチに対する計算を並列に行います。これらの手法を組み合わせることもできます。図2のように、インターコネクトで相互接続されたTPUコアの上に機械学習モデルを割り当てるため、コンポーネント間での計算結果のやり取りは、インターコネクトを介して行うことができます。
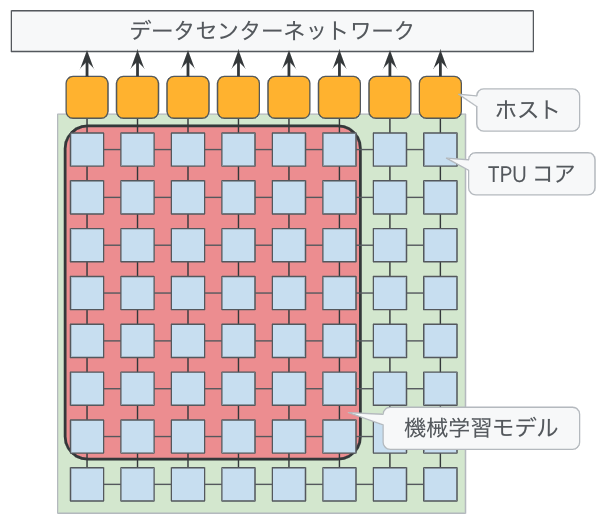
図2 複数のTPUコアに機械学習モデルを割り当てた状態
実際に計算処理を進める方法についてはいくつかのパターンがありますが、一例として、それぞれのTPUコアに対して機械学習モデルのコンポーネントを固定的に割り当てておき、各ホストのプログラムで非同期に計算を進める方法があります(図3)。ホストごとに計算の進み方が異なる場合、TPUコア間で計算結果をやり取りする部分(図3の「Collective operation」)で待ち時間が発生しますが、機械学習モデルの構造が比較的シンプルであれば、このような待ち時間をできるだけ減らすように計算のプロセスを工夫することも可能です。
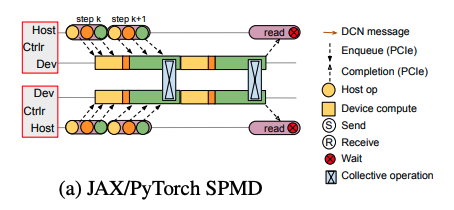
図3 複数ホストで並列に計算処理を進める様子(論文より抜粋)
さて、ここまではTPU Podを用いた学習処理の現状になりますが、冒頭の論文では、このような現状の仕組みには、先ほど説明した「複数タスクに対応した機械学習モデル」を学習する上での課題があることが指摘されています。まず、さまざまな役割を持ったコンポーネントが複雑に組み合わされた巨大なモデルの場合、単一のTPU Podにモデル全体を割り当てることができない可能性があります。さらには、コンポーネント間での計算結果のやりとりも複雑になるため、計算結果を受け取るための待ち時間が発生するポイントも多くなります。TPUコアに対して機械学習モデルのコンポーネントを固定的に割り当てた場合、このような待ち時間が多くなると、TPUコアの稼働率が低下して、計算リソースの有効活用が困難になります。この論文では、このような課題を解決するための新しい分散学習インフラとしてのPathwaysの仕組みが解説されています。
今回は、2022年に公開された論文「Pathways: Asynchronous Distributed Dataflow for ML」を元にして、Googleのエンジニアが開発した機械学習モデルの新しい分散学習インフラ「Pathways」について、このような新しい仕組みが必要される背景を説明しました。次回は、Pathwaysの具体的なアーキテクチャーについて解説していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































