
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2022年に公開された論文「Pathways: Asynchronous Distributed Dataflow for ML」を元にして、Googleのエンジニアが開発した、機械学習モデルの新しい分散学習インフラ「Pathways」を紹介します。今回は、Pathwaysのアーキテクチャーを説明します。
前回の記事で説明したように、Googleでは、大規模な分散学習インフラとして複数のTPUコアを高速なインターコネクトで相互接続したTPU Podを使用しています。Pathwaysが想定する複数タスクに対応した大規模な機械学習モデルへの適用を考えた場合、これには次のような課題がありました。
・機械学習モデルのサイズが大きくなると、単一のTPU Podにモデル全体を割り当てられない可能性がある
・機械学習モデルのコンポーネントを固定的に割り当てた場合、TPUコアの稼働率が低下する
1つ目の課題については、TPU Podのサイズをさらに大きくすることで対応する方法もあります。今後、インターコネクトの技術が発達するに伴い、1つのTPU Podに含まれるTPUコアの数は増加していくはずです。しかしながら、それでもどこかで技術的な限界に達するものと想像されます。したがって、TPU Podのサイズの拡大だけに頼るのではなく、通常のデータセンターネットワークで相互接続した複数のTPU Podを連携させる方法を考える必要があります。そこで、Pathwaysの分散学習インフラでは、図1の右図のように、機械学習モデルに含まれるコンポーネントを複数のTPU Podにまたがって配置する方式を採用しています。
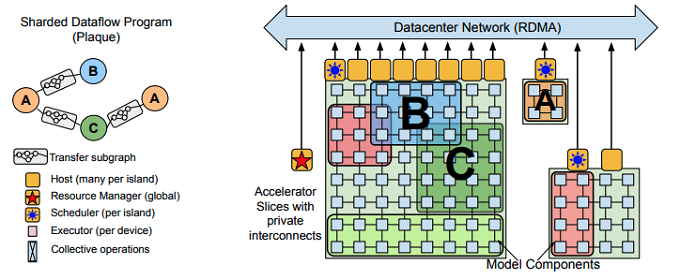
図1 Pathwaysのアーキテクチャー概要(論文より抜粋)
この場合、異なるTPU Podに配置されたコンポーネント間のデータのやり取りは、インターコネクトではなく、通常のデータセンターネットワークを介して行われます。しかしながら、Pathwaysが想定する「複数タスクに対応した機械学習モデル」は、図1の左図のように異なる役割を持ったコンポーネントが相互接続された構成になっており、コンポーネント間でのデータ転送量は、コンポーネント内部でのデータ転送量よりも少なくなります。このような機械学習モデルの構造に合わせてコンポーネントを配置することで、TPU Pod間のデータ転送がボトルネックにならないようにします。
さらに、図1の右図を見ると、複数のコンポーネントが重なって配置されていることに気がつきます。これは、コンポーネントの配置が固定的ではなく、ダイナミックに再配置されることを示しています。学習処理の過程によっては、他のコンポーネントによる計算が完了するまで、待ち状態となるコンポーネントが発生する場合があります。この場合、待ち状態のコンポーネントをTPUコアに割り当てたままにするのは無駄になります。そこで、リソーススケジューラーがTPUコアのグループ(スライス)を動的に確保して、計算処理が必要なコンポーネントに対して割り当てます。計算処理が終わって待ち状態となったコンポーネントは割り当てを解除して、該当のスライスを解放します(図2)。
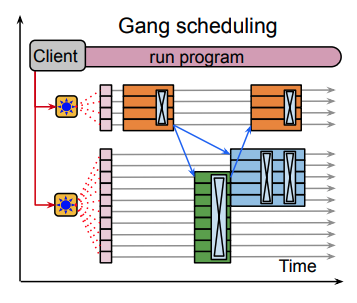
図2 リソーススケジューラーによるスライスの割り当て(論文より抜粋)
これは、サーバーで稼働するOSが複数のプロセスの実行を複数のCPUコアに割り当てる、タスクスケジューラーの役割にも似ています。今の場合は、コンポーネントごとの計算処理の依存関係も考慮して、無駄な待ち時間ができるだけ発生しないようにスケジューリングを行います。このようなスケジューリング機能は、HPCクラスターなどでも利用されるもので、一般に「Gang Scheduler」と呼ばれます。
冒頭の論文には、データセンターネットワークを介したデータ転送のオーバーヘッドを検証した結果が記載されています。たとえば、800億個のパラメーターを持つ自然言語モデルを「128個のTPUを持つ単一のTPU Pod」、および、「32個のTPUを持つ4個のTPU Pod(合計で128個のTPU)」という2つの環境で学習させた場合、いずれの構成でも同じ学習速度が得られたということです。図3は、4個のTPU Podを用いた構成でのTPUコアの使用状況を示したトレース図になります。
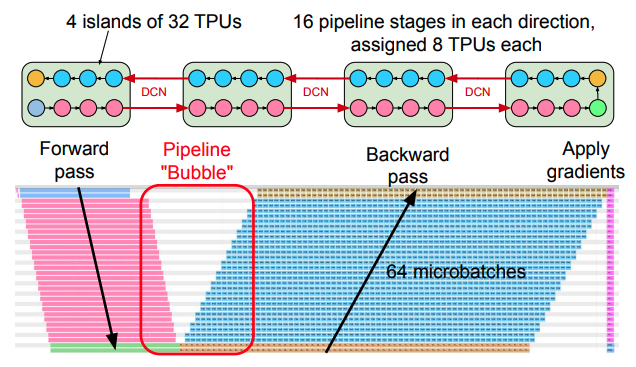
図3 TPUコアの使用状況のトレース図(論文より抜粋)
この学習プロセスでは、フォワードパスによる誤差関数の計算、バックプロパゲーションによる勾配の計算、勾配の適用によるパラメーターの更新という3種類の処理が行われており、それぞれのTPUコアの稼働状態が色分けして表示されています(各TPU Podから8個ずつのサンプルを表示)。それぞれの処理において異なるTPU Pod間でのデータ転送が行われており、このデータ転送による待ち時間が発生した場合、8個のグループごとに処理時間の差異が生まれるはずですが、トレース図にはそのような差異は現れていません。つまり、データセンターネットワークを介したデータ転送による遅延は、インターコネクトを介したデータ転送と同等の遅延に留まっているものと考えられます。
今回は、2022年に公開された論文「Pathways: Asynchronous Distributed Dataflow for ML」を元にして、Googleのエンジニアが開発した機械学習モデルの新しい分散学習インフラ「Pathways」について、そのアーキテクチャーの概要を紹介しました。
次回は、Pathwaysの分散学習インフラを用いて学習した自然言語モデルに関する論文を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































