
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2022年に公開された論文「CacheSack: Admission Optimization for Datacenter Flash Caches」を元にして、Googleのデータセンターで使用されている、フラッシュディスクによるファイルキャッシュシステムを紹介します。この論文では、数理最適化を用いてキャッシングポリシーを選択するアルゴリズムが紹介されており、ITシステムにおける数理最適化の応用例としても興味深い内容です。今回は、最適化のアルゴリズムを解説します。
まずは、これまでに説明した内容を簡単に復習しておきます。前々回に説明したように、Googleのデータセンターでは、Colossusと呼ばれる分散ファイルシステムが標準的に利用されており、これと組み合わせる形で「Colossus Flash Cache」と呼ばれる、SSDを利用したファイルキャッシュのシステムが用意されています。Colossusを利用するユーザーは、SSDをバックエンドとするフラッシュサーバー上のキャッシュ領域を確保しておき、これを読み込みキャッシュとして利用します。この時、ユーザーがアクセスするファイルごとに、キャッシュ領域にデータをコピーするかどうかを判断するのが、冒頭の論文のメインテーマとなる「CacheSack」の役割です。CacheSackの動作の流れは、次のようになります。
まず、ユーザーは、Colossus上のファイルごとにワークロードの種別を表す「カテゴリー」を指定します。例えば、BigtableのバックエンドとしてColossusを使う場合は、テーブル名などの情報からカテゴリーを決定します。これは、テーブルによってアクセスパターンが異なるという想定に基づきます。そして、Colossusのクライアントライブラリーは、ファイルを読み込む際に、Colossus Falsh Cacheのインデックスサーバーを用いて、該当ファイルがキャッシュ済みかを確認します。ファイルがキャッシュされていない場合、すなわち、キャッシュミスが発生した場合は、Colossusからファイルを読み込みます。この時、インデックスサーバーで稼働するCacheSackは、該当ファイルのカテゴリーに対して事前に設定された「ポリシー」に基づいて、このファイルをキャッシュするかどうかを判断します。
ここでカテゴリーごとに設定されるポリシーは、前回に説明した「AdmitOnWrite」「AdmitOnMiss」「AdmitOnSecondMiss」「NeverAdmit」の4種類から選択されます。あるカテゴリーに対して特定のポリシーを割り当てた際に、そのカテゴリーのデータが使用するキャッシュ容量や、そのカテゴリーのデータにアクセスする際に発生するキャッシュミスの割合などを見積ることができれば、そのポリシー選択によって得られる「価値」、あるいは、その逆の意味を表す「コスト」を定義することができます。ここでいう「コスト」は、大雑把には「ハードディスクに発生するIO処理の回数」に相当しますが、詳細については、実現したい目的に応じてチューニングすることになります。この際、それぞれのカテゴリーに割り当てるポリシーには、さまざまな組み合わせが考えられますが、「使用するキャッシュ容量の合計が事前に割り当てられた容量の範囲を超えない」という条件の下に、発生するコストの合計が最小になる組み合わせが発見できれば、それが最適なポリシー選択ということになります。使用するカテゴリーは、ユーザーごとに最大5,000種類に決められているので、理屈の上では、4^5,000(4の5,000乗)通りの組み合わせが考えられます。
このように、一定の条件下で「コスト」の合計を最小にする問題は、数理最適化の問題として取り扱われます。今回の例は、一般に「ナップサック問題」と呼ばれるもので、理論上は「NP困難」に相当する問題です。そのため、4^5,000通りもの組み合わせの中から最適なものを高速に発見することはできません。そこで、CacheSackのシステムでは、ポリシーの割り当て方法に少し柔軟性を持たせます。1つのカテゴリーに対して、「20%のデータはAdmitOnMissを使用して、80%のデータはAdmitOnSecondMissを使用する」というように、一定の比率で複数のポリシーを割り当てられるようにします。このように修正された問題は、「Fractionalナップサック問題」と呼ばれており、この場合は最適な組み合わせを高速に発見する複数の方法が知られています。CacheSackでは、この後で説明する「Greedyアルゴリズム」によってこの問題を解きます。
それでは、Greedyアルゴリズムの手順を説明していきます。まずはじめに、キャッシュに保存されたデータが(再度アクセスされなかった場合に)キャッシュ上に存在し続ける期間をDとします。これは、キャッシュの容量や新しいファイルがキャッシュにコピーされる頻度などに応じて変わりますが、ここでは先にDを決めておき、カテゴリーごとに「期間Dを実現するとした場合に使用するキャッシュ容量」を計算して、すべてのカテゴリーが使用するキャッシュ容量の合計が、実際に確保されたキャッシュ容量を超えないという条件の中で最適なポリシー割り当てを探し出します。(このように、「キャッシュ容量」という本来決まっている値をあえて変数と考えて、本来は変数である「期間D」を固定して考えるという発想の転換は、数理最適化問題を解く際に使用するテクニックの1つです。)そうすると、さまざまなDの値に対して、「そのDの値の下に最適なポリシーが実現する総コスト」が決まりますが、これらの中で総コストが最も小さくなるDを採用します。具体的には、15分から15日間の範囲で128種類のDの値について計算を行います。
次に、特定のDの下にポリシーの割り当てを決定する方法ですが、まずはじめに、特定のカテゴリーに対して特定のポリシーを割り当てたと仮定して、この時に、このカテゴリーのデータが使用するキャッシュ容量と、このカテゴリーのデータによって発生するコストをシミュレーションで見積もります。それぞれのカテゴリーのデータに発生するアクセスについては、インデックスサーバーに保存された過去のアクセス履歴がありますので、これを用いてシミュレーションを実行します。前回説明したように、実際に発生するコスト(ハードディスクのIO処理の回数)は、Colossusバッファーキャッシュの影響も考慮して見積る必要があるので、CacheSackは、バッファーキャッシュの動作を含めたシミュレーションを実施します。5,000種類のカテゴリーのそれぞれに対して、4種類のポリシーのシミュレーションを行うので、この部分では、5,000×4=20,000種類のシミュレーションが実行されます。
次に、シミュレーションで得られた結果を図1のようなグラフに表示します。ここでは、特定の1つのカテゴリーに対する結果が示されており、横軸は使用するキャッシュ容量で、縦軸は見積もられたコストの値になります。
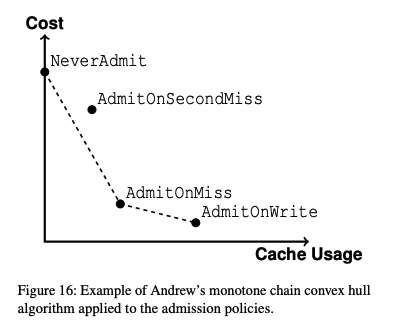
図1 特定のカテゴリーに対するシミュレーション結果の例(論文より抜粋)
図1の例を見ると、より積極的にキャッシュを使用するポリシーになるほど、使用するキャッシュ容量は大きくなり、キャッシュによるコスト削減の効果が大きくなることが分かります。なお、この図の場合、AdmitOnSecondMissは、NerverAdmitとAdmitOnMissを結ぶ直線よりも上に来ており、これは、AdmitOnSecondMissは最適なポリシーにはなり得ないことを意味します。なぜなら、NerverAdmitとAdmitOnMissを組み合わせたポリシーにより、これらを結ぶ直線上の任意の結果を得ることができるので、このような組み合わせポリシーで、AdmitOnSecondMissと同じだけのキャッシュ容量を使用しながら、AdmitOnSecondMissよりもコストが小さい結果が実現できることになります。ただし、1つのカテゴリーに対するグラフだけを見ていても全体として最適なポリシーの割り当ては決まりません。CacheSackはすべてのカテゴリーに対する同様のグラフを用意して、これらを用いて、次の手順でカテゴリーの割り当てを決定していきます。
まずはじめに、すべてのカテゴリーに対してNerverAdmitを割り当てたと仮定します。この場合、すべてのグラフにおいて、左端の点が実現されて、使用するキャッシュ容量の合計は0になります。この状態から、全体のコストがなるべく小さくなるように、それぞれのカテゴリーに対するポリシーの割り当てを変更していきます。具体的には、すべてのグラフの中で、NerverAdmitから右下に進む直線の傾きが最も大きいものを探しだして、該当するカテゴリーについては、割り当てるポリシーをNeverAdmitから、直線の右下に位置するポリシーに修正します。この直線の傾きが大きいほどコストを下げる効果が高いということのですので、まずはこれがベストな選択となります。このカテゴリーについては、この位置からさらに右下に向かうグラフの傾きを考えて、再度、他のすべてのカテゴリーを含めて、右下に向かう直線の傾きが最大になるものを探し出して、該当するカテゴリーに割り当てるポリシーを直線の右下に位置するものに変更します。
この作業を繰り返すと、使用するキャッシュ容量の合計が増加していき、やがて、「次のステップを実行すると使用するキャッシュ容量の合計が事前に用意したキャッシュ容量を超えてしまう」という時がやってきます。この場合は、直線の両端に位置するポリシーを一定の割合で組み合わせることで、使用するキャッシュ使用量の合計が事前に用意したキャッシュ容量にちょうど一致するように調整します。このように、各ステップにおいて、その時点でベストと考えられる選択を繰り返すアルゴリズムをGreedyアルゴリズムと呼びます。このような方法で、全体として最適なポリシーが得られるかどうかは問題の種類に依存しますが、今回のFractionalナップサック問題については、これで全体最適化が実現できることが数学的にも証明されています。
ただし、これらの計算は、CacheSackが実行するシミュレーションによる「見積もり」に基づいたものですので、シミュレーションが不正確であれば、本当に最適な結果になるとは限りません。この点ついては、実環境におけるベンチマークにより、CacheSackが選択したポリシーが実際に実現するコストの削減効果を測定することになります。
今回は、2022年に公開された論文「CacheSack: Admission Optimization for Datacenter Flash Caches」を元にして、Googleのデータセンターで使用されている、フラッシュディスクによるファイルキャッシュシステムについて、ワークロードごとに最適なポリシーを選択するアルゴリズムを解説しました。次回は、実環境におけるベンチマーク結果のデータを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































