
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「AI-assisted Assessment of Coding Practices in Industrial Code Review」に基づいて、Google社内での大規模言語モデルによるコードレビュー支援の事例を紹介していきます。ユースケースとしては比較的シンプルですが、ユーザーからのフィードバックに基づくモデルの改善など、数万人の開発者が利用する環境への導入における工夫には、参考になる点が数多くありそうです。今回は、事例の背景と大規模言語モデルの学習データについて説明します。
Google社内でコードレビューに大規模言語モデルを活用する例には、先に公開した下記の記事の事例があります。これは、レビュアーのコメントによる指摘に対して、指摘事項を解決するコード修正案を大規模言語モデルが自動提案するというものでした。
・第170回 大規模言語モデルによるコードレビュー支援の適用事例(パート1)
一方、今回の論文では、コードの書き方が「ベストプラクティス」に即していない部分を大規模言語モデルで発見して、修正の参考となるドキュメントへのリンクを提示するという事例が紹介されています。この事例の背景には、既存のコードレビュープロセスにおける「Readbilityプロセス」の課題を解決する目的があります。ここではまず、Readabilityプロセスについて簡単に説明しておきます。
一般に、多くのソフトウェア開発企業では、コードの書き方に関するスタイルガイドを策定しており、コードのインデントなどのフォーマット規則、関数や変数の命名規則、コード内に記載するドキュメントの書き方、特定機能の利用方法、コードイディオム(コードの書き方の典型パターン)などに関する取り決めがあります。Google社内でもコードレビューの際には、このような規則に関するチェックが行われます。これらの規則の中には、Linterなどの静的解析ツールでチェックできるものもありますが、既存のツールでは自動判定が困難なケースも多数あります。そこで、Google社内では、それぞれのプログラミング言語ごとにこのようなベストプラクティスに精通した「Readabilityメンター」が認定されており、経験の浅い開発者のコードに対して、コードレビュープロセス中に図1のような改善コメントをつけていきます。
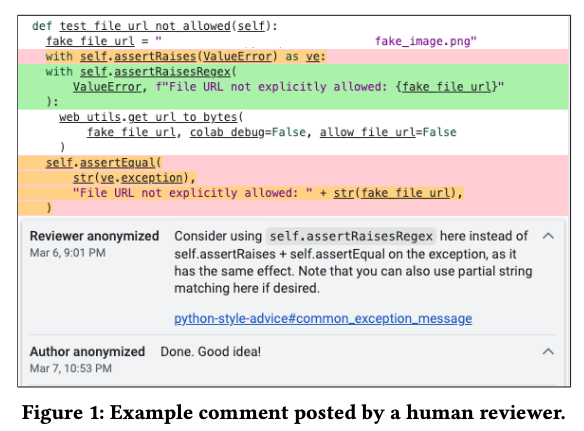
図1 Readabilityメンターによるコメントの例(論文より抜粋)
この例にあるように、Readabilityメンターは、適用するべきベストプラクティスを短くまとめた上で、詳細が記載されたドキュメントのリンクをコメントに書き込みます。このような作業は、Readbilityメンターにとっては単調で時間がかかる作業ですが、その一方で、技術の発展に伴って変化するプラクティスを継続的に学び続けるという努力も求められます。図1のようなコメントを大規模言語モデルで自動生成することにより、Readabilityメンターの作業負荷を軽減することが、この事例の目的の1つになります。
この事例では、Googleの研究チームが一般公開している大規模言語モデルT5Xを使用しています。第170回の記事の中で紹介したDIDACTワークフレームを用いて、プログラムコードを対象としたさまざまなタスクを同時に学習するマルチタスク学習を行う際に、ベストプラクティスに即していない部分を検出するタスクをあわせて学習します。図2は、学習データの例で、プログラムコードの一部を入力データとして、ベストプラクティスに関するレビューコメントを挿入するべき位置と、該当するベストプラクティスのドキュメントへのリンクを出力するように学習します。実際のレビューコメントでは、図1のようにリンク先のドキュメントのサマリーも記載しますが、この部分については、自然言語を対象とした別のモデルでリンク先のテキストから生成します。

図2 ベストプラクティス分析の学習データの例(論文より抜粋)
そして、学習処理全体のパイプラインは、図3の様になります。まず、左端の部分では、コードレビューシステムの既存のコメントデータからベストプラクティスの適用に関するコメントをバッチで抽出します。その後、中央の部分で図2の形式の学習データに変換します。この際、実際に使用するデータの種類を選別するなど、学習の目的に応じたフィルタリングが行われます。そして、右端の部分では、TPU pod上で学習処理を実行します。
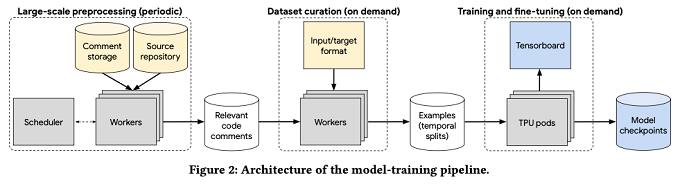
図3 学習データ作成から学習処理実行までのパイプライン(論文より抜粋)
そして学習後のモデルは、機械学習の通常の手続きに従って、テストデータによる評価を行います。ただし、今回の学習データとテストデータは、コードレビューシステムの既存のコメントデータ、言い換えると、現実世界のデータに基づいたものであり、「完全な学習・評価データ」とは言えません。現実のレビュープロセスでは、次の様なケースがあるためです。
従って、学習後のモデルを実際に利用するにあたっては、テストデータによる一般的な評価に加えて、限定ユーザーによるレビューやA/Bテストによる評価など、実環境からのフィードバックによる改善プロセスが重要になります。
今回は、2024年に公開された論文「AI-assisted Assessment of Coding Practices in Industrial Code Review」に基づいて、Google社内での大規模言語モデルによるコードレビュー支援の事例について、その背景と大規模言語モデルの学習データについて説明しました。次回は、このモデルを実環境に適用する際の評価・改善のプロセスについて説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































