
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「AI-assisted Assessment of Coding Practices in Industrial Code Review」に基づいて、Google社内での大規模言語モデルによるコードレビュー支援の事例を紹介します。今回は、実環境に適用する際の評価・改善のプロセス、特に、開発チーム内のテスト利用段階で実施したチューニングを紹介します。
前回の記事では、大規模言語モデルT5Xを用いて、プログラムコードに対して、ベストプラクティスに関するレビューコメントを挿入するべき位置と該当するベストプラクティスのドキュメントへのリンクを生成するモデルを用意する所まで説明しました。開発チームでは、このモデルを「AutoCommenter」と呼んでいます。AutoCommenterを実際に使用する環境には、レビューシステムのWeb UIと開発中に使用するIDEのUIがあります。
まず、レビューシステムのWeb UIでは、レビュー対象のコードに対して、図1のようなコメントが自動的に追加されます。ここでは、適用が推奨されるベストプラクティスのドキュメント(図の例では「C++ style guide: Structs vs. Tuples」)へのリンクと、該当のベストプラクティスのサマリーがコメントとして表示されます。AutoCommenterのモデルがドキュメントへのリンクを生成した後に、別の大規模言語モデルを用いて、コメントに表示するべきサマリーを生成しています。このコメントを見た開発者やレビューアーは、Thumbs-up/downボタンによるポジティブ/ネガティブのフィードバックを返すことができます。また、このコメントの指示に従うべきだと考えたレビュアーは、「Please fix」をクリックして、開発者にコードの修正を依頼します。これもまたポジティブなフィードバックとして捉えられます。

図1 AutoCommenterが自動生成するレビューコメントの例(論文より抜粋)
次に、IDEのUIでは、ソフトウェア開発者がIDEのエディタでコードを書いている時に、リアルタイムでモデルによる予測を適用して、該当箇所に波線のアンダーラインを表示します。この部分にマウスカーソルを移動すると、レビューシステムと同様のコメントとリンクが表示されます。こちらはリアルタイムでの予測が必要となるので、1秒以下での予測が性能要件として設定されました。
AutoCommenterの実環境への適用は、次の4つのフェーズに分けて行われました。
図2は、それぞれの期間におけるユーザーからのフィードバックの変化を時系列で示したものです。波線のグラフは1ヶ月あたりのフィードバック数の変化、オレンジ色と青色のグラフは、ポジティブなフィードバックとネガティブなフィードバックの比率を表します。
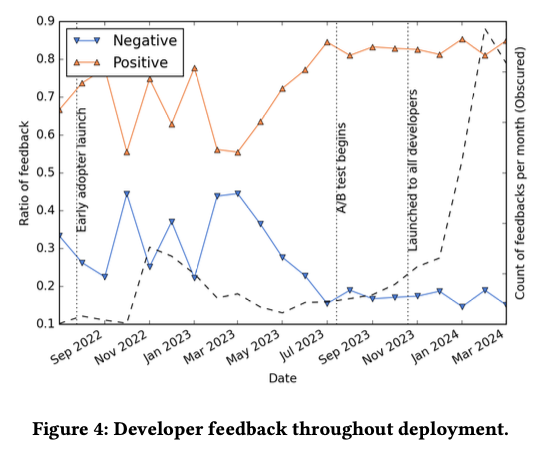
図2 開発者からのフィードバックの時系列変化(論文より抜粋)
A/Bテストを開始するまでは、さまざまなチューニングを行っており、それに応じてフィードバックも大きく変動していることがわかります。ここではまず、開発チーム内のテスト利用段階で実施したチューニングを紹介します。論文では、具体的な内容として、プログラミング言語ごとのしきい値の設定と、学習済みのモデルによるテキスト生成時の予測手法の選択が説明されています。
まず、AutoCommenterのモデルは、レビューコメントを挿入するべき箇所を予測する際に、その予測に対する信頼度の値を出力します。当初は、信頼性を優先して、信頼度が0.98以上の結果のみを採用していましたが、この信頼度以下でも正しい予測が多数残っていることが判明したため、より適切なしきい値を確認することにしました。この際、プログラミング言語ごとに信頼度の分布が大きく異なることがわかり、プログラミング言語ごとにしきい値を設定することにしました。しかしながら、しきい値を下げて適用するコメント数を増やしていくと、レビューの対象にはならない、変更していない部分のコードに対するコメントが多数生成されたり、特定のベストプラクティスに対するコメントが偏って選択されるなどの課題が発生しました。具体的には、変更部分に対するコメントは全体の1.3%で、最頻の10種類のベストプラクティスに関するコメントが全体の80%を占めるという状況でした。
開発チームでは、このような予測の偏りを低減する方法として、複数の予測手法を比較しました。一般に、大規模言語モデルでテキストを生成する際は、「次の単語を予測する」という処理を繰り返しますが、最も確率が高い単語を選択するGreedy searchの他に、top-k、top-pなどのパラメーターに従ってサンプリングする方法、あるいは、複数の予測結果を並列に生成しながら、より信頼度の高い結果を探索するBeam searchなどの方法があります。これらの方法を比較した結果、Beam searchを用いれば、変更部分に対するコメントを3.9%まで増加して、最頻の10種類の割合は41%まで低減できることがわかりました。ただし、Beam searchは予測に時間がかかるため、バッチ処理が可能なレビューシステム上でのコメント生成のみに使用して、IDE上でのリアルタイム予測はデフォルトのGreedy searchを採用したということです。
今回は、2024年に公開された論文「AI-assisted Assessment of Coding Practices in Industrial Code Review」に基づいて、Google社内での大規模言語モデルによるコードレビュー支援の事例について、実環境に適用する際の評価・改善のプロセス、特に、開発チーム内のテスト利用段階で実施したチューニングを紹介しました。次回は、より多くの開発者によるテスト利用を開始した後のチューニングについて説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































