
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「Thesios: Synthesizing Accurate Counterfactual I/O Traces from I/O Samples」に基づいて、架空の構成のストレージシステムに対するI/Oトレースを生成するシステムである「Thesios」について解説していきます。今回は、Thesiosが収集するI/Oトレースデータについて説明します。
Googleのデータセンターでは多数のストレージシステム、端的に言うと、多数のハードディスクを搭載した多数のサーバーが稼働しています。下記から始まる一連の記事でも説明したように、これらのハードディスクは複数世代の製品が混在しており、容量や通信帯域、あるいは、回転速度などの特性が異なります。
・第203回 ホットリンクを回避するコンテナスケジューラーの活用(パート1)
現状のハードディスクに対するアクセスの発生状況や個々のアクセスのレイテンシーについては、既存のモニタリングシステムでデータ収集されていますが、それに加えて、ストレージシステムに変更を加えた際のアクセス状況の変化を予測することも大切です。ディスクシステムの構成変更やアクセスポリシーの変更を行う場合、これまでは、本番環境の一部を利用したA/Bテストなど、一定のリスクを伴うテストを時間をかけて行う必要がありました。Thesiosは、モニタリングシステムが収集したI/Oトレースデータを元にして、新しい構成での架空のトレースデータを生成します。これにより、本番環境を利用せずに、さまざまな構成変更の影響が事前に予測できます。
Thesiosは、実環境のI/Oトレースデータを利用しますが、この際、適切な予測に必要なデータをうまく選定する必要があります。すべてのI/Oアクセスのデータが利用できるのが理想ですが、これは現実的ではありません。Googleのデータセンター規模のストレージシステムですべてのアクセスデータを収集すると膨大な容量になる上に、データ収集のオーバーヘッドがストレージシステムの性能に悪影響を及ぼす恐れもあります。
そこで、一定の割合でサンプリングしたデータを収集することになりますが、この際、収集したデータから、システム全体の特性が再構成できることが重要になります。そこで、Thesiosでは、複数の「オブジェクト」を含む「エンティティ」について、「一定割合のオブジェクトから収集したデータを用いて、エンティティとしての特性を再構成する」という考え方を適用します。たとえば、1台のサーバーには複数のハードディスクが接続されていますが、データを収取するハードディスクを決めておき、これらから集まったデータをこのサーバーに対する代表的なI/Oデータとみなします。ここでは、すべてのハードディスクから断片的なデータを集めるのではなく、サンプリング対象に決めたハードディスクからは完全なデータを収集する所がポイントになります。サーバーに搭載されたハードディスクの多くは、類似したI/O特性を持っているはずですので、すべてのハードディスクから断片的なデータを集めるよりは、一部のハードディスクから完全なデータを集める方が、より正確にシステムの特性が再現できると考えられます。
この例では、サーバーが「エンティティ」で、ハードディスクが「オブジェクト」にあたりますが、この考え方は階層的に適用されます。1台のハードディスクには複数のファイルが保存されていますので、ハードディスクに対するデータを収集する際は、1台のハードディスクを「エンティティ」、そして、そこに保存された個々のファイルを「オブジェクト」と見なします。つまり、ハードディスク内の一定数のファイルをサンプリング対象として、これらのファイルに対する完全なI/Oデータを収集します。Thesiosは、このようにして収集したデータを組み合わせて、新しい構成のハードディスクに対する架空のI/Oデータを再構成します(図1)。
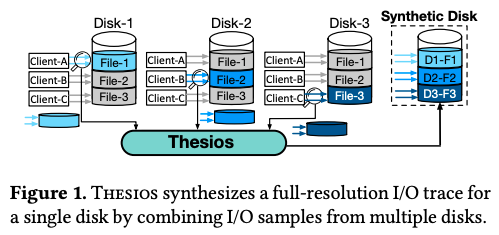
図1 ThesiosによるI/Oデータ生成の考え方(論文より抜粋)
次の図2は、「エンティティ」と「オブジェクト」に基づいたデータ収集の利点を示すデータの例です。これは、ファイル毎の1日のアクセス数の分布を示すデータで、左は、この方式で収集したサンプルから計算した結果で、右は、すべてのファイルからランダムにサンプリングした場合の結果です。ランダムサンプリングの場合、個々のファイルから4個以下のデータしか収集されておらず、ファイル毎のアクセス数に関する正しい情報が得られないことがわかります。
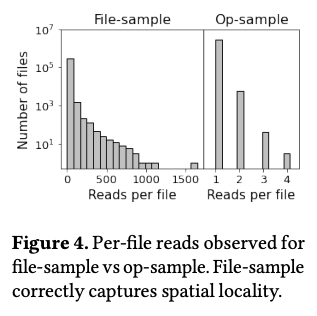
図2 Thesiosのデータ収集方式の利点を示す例(論文より抜粋)
ThesiosがI/Oトレースデータを収集する際の考え方は前述の通りですが、実際に収集したデータをそのまま利用するわけではありません。I/Oトレースデータの収集はサーバー上で行われるため、そこから個々のハードディスクに対するI/Oトレースを再構成する必要があります。例えば、モニタリングシステムは、サーバーがI/Oリクエストを受け取った時刻を記録しますが、ここから、該当のI/Oリクエストがハードディスクに到達する時刻を推定する必要があります。特に、サーバーが受け取るI/Oリクエストには、「Latency-sensitive(L)」「Throughput-oriented(TP)」「Other(O)」の3種類の優先順位が設定されており、図3のように、優先順位に応じたリクエストキューに入ります。そのため、サーバーがI/Oリクエストを受け取る時刻とそのリクエストがハードディスクに到達する時刻の差は、優先順位によって変動します。そこで、Thesiosは、収集したI/Oトレースデータを用いて、リクエストキューの状態変化をシミュレーションすることで、個々のI/Oリクエストがハードディスクに到達する時刻を計算します。
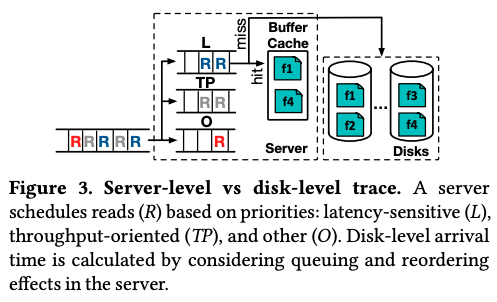
図3 サーバーとディスクのI/Oトレースの関係(論文より抜粋)
このような処理を経て、Thesiosが最終的に収集するI/Oトレースデータの内容は、図4のようになります。上段はモニタリングシステムから直接収集されるデータで、下段は上述の仕組みで計算されるデータです。このようにして収集・再構成されたI/Oトレースデータを元にして、新しい構成のストレージシステムに対する架空のI/Oトレースデータを生成するのがThesiosの役割です。

図4 Thesiosが記録するI/Oトレースデータ(論文より抜粋)
今回は、2024年に公開された論文「Thesios: Synthesizing Accurate Counterfactual I/O Traces from I/O Samples」に基づいて、架空の構成のストレージシステムに対するI/Oトレースを生成するシステムである「Thesios」について、Thesiosが収集するI/Oトレースデータを解説しました。次回は、新しい構成のストレージシステムに対して、I/Oトレースの予測データを生成する仕組みを解説します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































