
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Thesios: Synthesizing Accurate Counterfactual I/O Traces from I/O Samples」に基づいて、架空の構成のストレージシステムに対するI/Oトレースを生成するシステム「Thesios」について解説します。今回は、Thesiosが新しい構成のストレージシステムに対して、I/Oトレースの予測データを生成する仕組みを解説します。
前回の記事で説明したように、Thesiosは、「エンティティ/オブジェクト」モデルに基づいて、サーバーごと、および、ディスクごとにI/Oトレースデータを収集します。ただし、1つのディスクに対して収集されるデータは、あくまでもオブジェクトとして選ばれたファイルに対するデータですので、これが該当のディスクのI/O特性を偏りなく表しているという保証はありません。そこで、類似の特性を持ったディスクのデータを集める事で、該当の特性を持ったディスクの「代表データ」を作ります。各ディスクは、保存ファイルの1/nをデータ収集対象に選定しているとすれば、n台のディスクからのデータを集めることで、1台のディスクに対する「代表データ」が用意できます。ただし、突発的なアクセスの増加(バースト)が発生した際は、モニタリングシステムはデータ収集の負荷が上がらないように、データの収集割合を意図的に下げます。この影響を考慮して、全体的にw倍にデータ量を増やして代表データを構成します(図1)。wの値はバーストの発生状況に応じてチューニングした値を使用します。
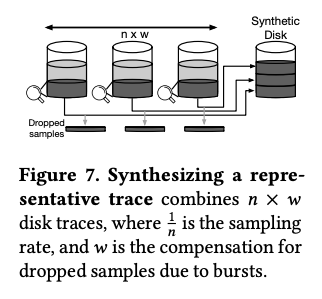
図1 収集データから「代表データ」を構成する仕組み(論文より抜粋)
また、先ほど、類似の特性を持ったディスクのデータを集めると説明しましたが、大きくは次の3つの基準値の組み合わせでディスクを分類します。
「アクセス頻度の基準値」におけるホットファイル/コールドファイルというのは、実際のアクセス頻度ではなく、ファイルを保存するアプリケーションが指定する設定値で決まります。アプリケーションの特性としてアクセス頻度が高いファイルには「ホットファイル」、アーカイブデータのようにアクセス頻度が低いファイルには「コールドファイル」のラベルが付けられており、ディスクごとのファイル保存ポリシーとして、ホットファイルとコールドファイルの割合が事前に指定されています。この割合はディスクの性能やアクセス帯域に応じて設定されます。
そして、これらの基準値でディスクをグループ分けした後に、実際のアクセス頻度やリードとライトの割合など、追加の基準でより詳細なクラスタリングを実施します。図2の左は、一例として、5つの追加基準で6種類のクラスターに分類した結果を表します。また、図2の右は、クラスタリングに使用する基準によって、クラスターに含まれるディスクのアクセス頻度のばらつき(最大値と最小値の差)が変化する様子を示します。クラスタリングの基準に使用するデータを増やしてより詳細にクラスターを分けた方が、クラスター内のばらつきが小さくなることがわかります。
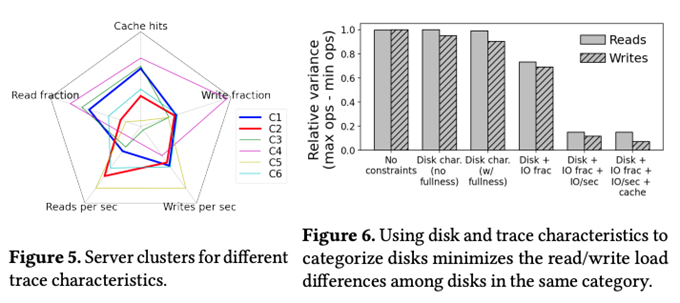
図2 ディスクの特性によるクラスタリングの例(論文より抜粋)
実際には、さまざまな基準値によるクラスタリングを試した上で、ストレージシステムごとに最適と思われるクラスタリング方法を採用していることが論文内で説明されています。
このようにして類似の特性を持ったディスクのグループごとの「代表データ」が用意できると、これらを組み合わせる事で、新しい構成のディスクに対する「アクセス予測データ」が生成できます。たとえば、これまでよりも容量が大きいディスクがあった場合、このディスクにはどのようなアクセスが発生するでしょうか? 一例として、容量以外の条件が類似したディスクグループの代表データを必要な容量分だけ集めるという方法が考えられます。この場合、集めたデータの分だけ該当ディスクへのアクセスが発生するという予測データが得られますが、これは現実的なデータと言えません。ディスク容量が増えたとしても、ディスクのアクセス帯域がこれまでと同じであれば、実際に処理できるI/Oオペレーションの数はそれほど大きくはならないはずです。そこで、Thesiosでは、先ほど説明したホットファイルとコールドファイルのデータを分けて考えます。図3の左にあるように、ホットファイルに対するデータは同じ容量のディスクと同量だけ集めて、残りはコールドファイルに対するデータで構成します。これにより、ディスクに保存するデータの総量を増やしながら、実際のアクセス頻度は従来のディスクと同等の予測データが構成できます。
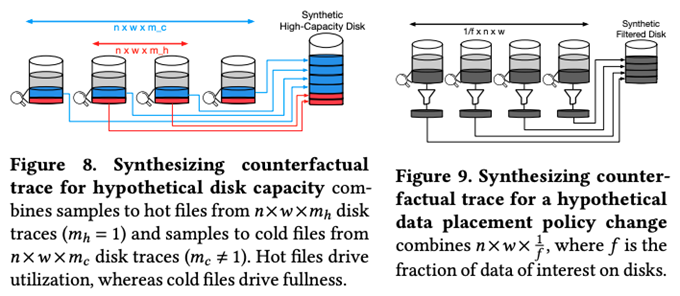
図3 「代表データ」を組み合わせてリクエスト予測データを構成(論文より抜粋)
あるいは、既存のディスクに対して、ディスクのアクセス帯域には十分な余裕があるという想定の下に、アクセス頻度の基準値(ホットファイルとコールドファイルの割合)を維持したまま、ディスクの使用率(ディスク容量の何%までデータが保存されているか)を増加した場合の架空のアクセス予測データを構成するのであれば、図3の右のように、ホットファイルとコールドファイルを区別せずに、必要なだけのデータを組み合わせることになります。
このようにして、類似した特性を持ったディスクのグループごとの「代表データ」をさまざまな条件の下にサンプリングして集めることで、新しい構成に対するアクセス予測データを構成します。
これで新しい構成のストレージに対するアクセス予測データが得られたわけですが、Thesiosの本来の目的は、単なるアクセス予測ではありません。この予測通りのI/Oリクエストが発生した場合の処理速度(レイテンシー)や消費電力などを計算する事で、構成変更の影響を予測することが最終的なゴールになります。この部分については、実際のI/O処理をソフトウェアでシミュレーションすることで予測します。具体的には、1台のサーバーに複数のディスクを接続したとして、それぞれのディスクに予測されたI/Oリクエストが発生した場合に、サーバー全体としてこれらのI/Oリクエストがどのように処理されるかを計算します。前回の図3で説明したように、I/Oリクエストの優先順位によって処理順序が変わるので、この部分も考慮したシミュレーションを行います。あるいは、より正確な予測が必要な場合は、実験用のサーバーに対して、予測されたI/Oリクエストを実際に発生させて処理時間を計測する場合もあるということです。
今回は、2024年に公開された論文「Thesios: Synthesizing Accurate Counterfactual I/O Traces from I/O Samples」に基づいて、Thesiosが新しい構成のストレージシステムに対するI/Oトレースデータを生成する仕組みを説明しました。次回は、Thesiosが生成したデータの正確性を示すデータとThesiosの実際の利用例を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































