
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2017年に公開された論文「A Neural Representation of Sketch Drawings」をもとにして、ディープラーニングを用いて簡単なスケッチ(線画)を再現する実験を紹介したいと思います。この論文の面白い点として、Googleが公開しているオンラインのお絵かきゲーム「Quick, Draw!」のプレイヤーから提供されたデータを利用している点があります。機械学習、とくにディープラーニングでは、ラベル付きの教師データの収集が大変という話を耳にすることもありますが、ユーザー参加型の簡単なゲームを通じて研究用データの提供を受けるというのは、なかなかユニークな発想ではないでしょうか。
はじめに、この論文の特徴でもある「スケッチデータ」を紹介しておきます。前述の「Quick, Draw!」は、ネコやバスなど、指定されたカテゴリーの線画を20秒以内に描画して、AIシステムが正しく認識できるかを競うというゲームです。20秒という時間制限があるため、できるだけシンプルで特徴を捉えた絵を描こうというインセンティブが働きます。このようにして作られた線画のデータをカテゴリー別に整理したものが、「The Quick, Draw! Dataset」として公開されています(図1)。345カテゴリー、5千万件のデータが含まれており、Creative Commons(CC BY 4.0)のライセンスの下に再利用することができます。

図1 「Quick, Draw!」データセットに含まれるデータの例
オリジナルのデータには、個々の線を引く速さなどの情報も含まれていますが、冒頭の論文ではこれを単純化して、ペンの移動情報のみを取り出しています。曲線で描かれた画像を短い線分の集まりと見なして、個々の線分について、「x方向とy方向のペンの移動量」、および、「端点でのペンの上げ下げの動作」の情報を付与しています。線分の無い部分については、「ペンを上げた状態でペンを移動する」という形で表現されており、一連のデータに従って順番にペンを動かせば、線画が再現されることになります。
冒頭の論文では、線画を再現する仕組みとして、時系列データを取り扱うRNN(Recurrent Neural Network)とオートエンコーダーの一種であるVAE(Variational Autoencoder)を組み合わせたニューラルネットワークのアーキテクチャーを採用しています。・・・と、いきなり専門用語が出てきて話が難しくなりましたが、今回は、まずは、オートエンコーダーの基礎を説明します。今回の説明を踏まえた上で、次回、実際に論文の中で紹介されているニューラルネットワークの全体像(図2)を解説していきます。
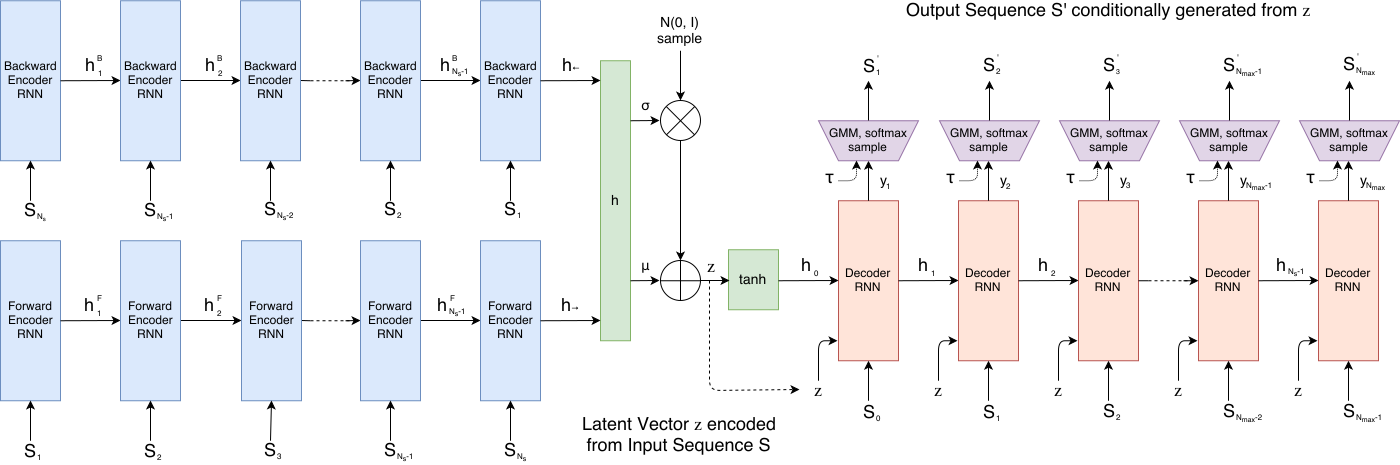
図2 スケッチ画像を生成するニューラルネットワーク(論文より抜粋)
オートエンコーダーというのは、入力データに対して、できるだけそれに似たデータを出力するニューラルネットワークです。たとえば、0〜9の数字の画像データを入力すると、同じ数字の画像が出力される様子を想像してください。もちろん、入力データをそのまま出力すれば、間違いなく同じデータが得られますが、オートエンコーダーの動作はそういうものではありません。オートエンコーダーを理解するために、あなた自身が数字の画像を記憶して、それを再現する方法を想像してみましょう。ほんの一瞬だけ数字の画像を見せられて、その後、同じ図形を描いてくださいと言われた場合、あなたはどうするでしょうか? 当然ながら、まずはじめに、それがどの数字かという情報を記憶するでしょう。その上で、細かな数字の形の特徴を覚えて、同じ形を再現していきます。
この際、「どの数字か」という情報さえ記憶しておけば、大きな間違いをおかすことはありません。ここがポイントです。オートエンコーダーの仕組みはこれと同じで、まずはじめに、トレーニング用のデータセットから、その特徴となる情報を抽出する「エンコーダー」と呼ばれる部分を用意します。次に、その特徴を元にして、データを再生成する「デコーダー」と呼ばれる部分を用意します。数字の画像の例であれば、それがどの数字かを理解するのがエンコーダーで、該当する数字の画像を生成するのがデコーダーということになります。
図3は、実際に動作するオートエンコーダーの模式図です。複数のレイヤーを重ねた典型的なニューラルネットワークですが、中央部のレイヤーはノード数が少なくなっているという特徴があります。そのため、入力データをそのまま記憶することはできず、少数の「重要な情報」のみが中央のレイヤーに抽出されることになります。入力データと出力データができるだけ一致するように、多数の学習データを用いてこのニューラルネットワークをトレーニングすることにより、エンコーダー部分とデコーダー部分が同時に学習されます。
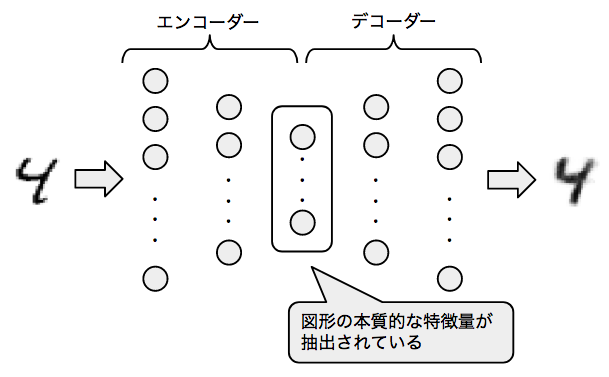
図3 簡単なオートエンコーダーの例
それでは、このようにして学習したオートエンコーダーに、学習データとは異なるデータを入力するとどうなるでしょうか? たとえば、先のように数字の画像データで学習した後に、アルファベットの「B」の画像を入力してみます。―― 図4は、筆者が実際に試した結果ですが、出力画像は数字の「8」に似た形になっています。つまり、このオートエンコーダーは、数字の画像のみで学習したため、数字以外の形の情報を持っておらず、どのような入力に対しても、それに一番近い数字の特徴を抽出して、似た形の数字を描くという動作を行うのです。
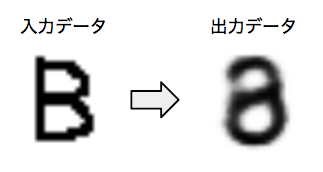
図4 学習データと異なるデータを入力した結果
先ほど図2に示した複雑なニューラルネットワークも、本質的な構造は同じです。左側の水色の部分がエンコーダーになっており、入力データを複数の数値からなる特徴量に変換します。右側の赤色の部分がデコーダーで、特徴量を元にして、新しいスケッチデータを生成する役割を担います。
今回は、論文「A Neural Representation of Sketch Drawings」について、学習用の教師データとなる「Quick, Draw!」データセットと、その基礎となるオートエンコーダーについて説明しました。次回は、図2のニューラルネットワークによって、新たなスケッチデータを生成する仕組みをもう少し詳しく見ていきたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































