
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2017年に公開された論文「A Neural Representation of Sketch Drawings」をもとにして、ディープラーニングを用いて簡単なスケッチ(線画)を再現する機械学習モデルを解説します。前回説明したように、入力データに対して類似性のあるデータを出力する「オートエンコーダー」とよばれる仕組みが基礎となります。
図1は、前回紹介したSketch-RNNと呼ばれる機械学習モデルの全体像です。左側の青色の部分が、前回の図3における「エンコーダー」に相当する部分で、入力データから特徴量を抽出する処理を行います。最終的に得られる特徴量は、128次元(具体的な次元数はモデルによって異なります)のベクトル値、すなわち、128個の数値の集まりですが、このモデルでは、ここに乱数の要素を取り入れています。どういうことかと言うと、入力データから直接に特徴量を計算するのではなく、まずはじめに、特徴量空間における「平均 μ」と「標準偏差 σ」を計算します。その後、これらを用いた正規分布の乱数(μ を中心として、σ 程度の広がりを持つ乱数)を生成して、これを特徴量とします。σ の値が大きいほど、生成される特徴量の「ゆらぎ」が大きくなります。また、入力データから μ と σ を計算する部分には、時系列データを取り扱う「RNN(Recurrent Neural Network)」を使用しています。つまり、線画を描く順序も考慮したデータ処理が行われます。
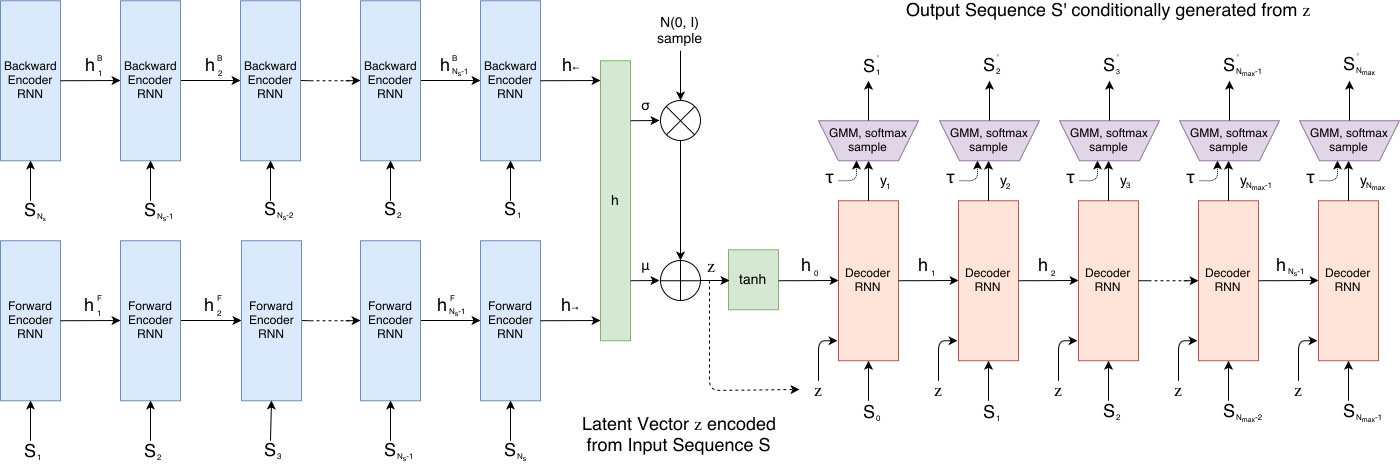
図1 Sketch-RNNの構造(論文より抜粋)
続いて、右側の赤色の部分が「デコーダー」に相当する部分で、特徴量を元にして、新たな線画のデータを生成していきます。ここでも、時系列データを取り扱うRNNに加えて、データ生成の際に乱数の要素が取り入れられています。はじめに、特徴量を元にして、最初のストローク(ペンをどの位置に持ってくるか)を決定するのですが、ペンの移動量に対する「平均 μ」と「標準偏差 σ」を計算した後に、これらを用いた正規分布の乱数で実際のペンの動きを決定します。そして、先ほどの特徴量に加えて、ここで決定したペンの動きを入力値として、次のペンの移動量に対する「平均 μ」と「標準偏差 σ」を計算する、という処理を繰り返していきます。ペンの移動量に加えて、ペンの上げ下げ、および、ペンを止めて絵を描くのをやめると言った動作についても同様の乱数を用いた決定法を適用しています。
Sketch-RNNの機械学習モデルは、RNNを用いている点、そして、乱数の要素を取り入れているという特徴があるものの、本質的には、「エンコーダー」と「デコーダー」を組み合わせたオートエンコーダーと同じ仕組みになっています。このモデルを学習する際は、前回の説明と同様に、入力データに対して、(乱数を用いて)生成された出力データができるだけ近い形になることを目指して、モデルに含まれるパラメータを更新していきます。
この際、特徴量に乱数の要素をどの程度取り入れるかを調整する、正則化の処理を行います。具体的には、特徴量空間における「平均 μ」と「標準偏差 σ」がそれぞれ、0 と 1 になるべく近くなるように調整するもので、この正則化を強くすると、学習後のモデルが生成する特徴量のゆらぎが小さくなります。言い換えると、モデルが生成するスケッチの「バリエーション」が小さくなるということで、安定的にきれいなスケッチを生成することができるようになります。逆に正則化を弱くすると、生成されるスケッチのバリエーションが広がりますが、その代わりに、大きく乱れたスケッチができてしまう可能性も大きくなります。この部分は、出力データの安定性とバリエーションのトレードオフを考慮して、適切な値を見つけ出す必要があります。
また、学習後のモデルを用いて、新しいスケッチを生成する際は、2つのやり方があります。1つは、何らかのスケッチデータをエンコーダーに入力して、ここで得られた特徴量をデコーダーに入力するという方法です。この場合、入力データに似た形の出力データが得れると期待されますが、前回の図4に示したように、その出力は、学習に用いたデータに大きく影響されます。たとえば、「ネコ」のデータだけを用いて学習したモデルであれば、どのようなスケッチを入力しても、かならず、ネコに似たスケッチが出力されることになります。図2は、一般公開されている学習済みモデルを用いて、筆者の手書き画像から生成したスケッチの例になります。
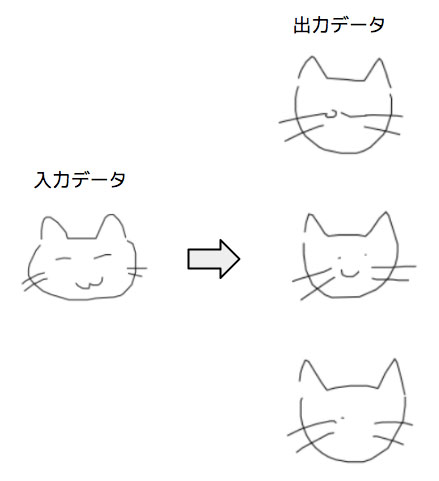
図2 学習済みモデルで生成したスケッチの例
そして、もう1つの方法は、人為的に用意した特徴量からスケッチを生成するという方法です。たとえば、特徴量を連続的に変化させると、そこから生成されるスケッチも連続的に変化することが期待されます。図3は、4種類の特徴量を事前に決めておき、それらの間で直線的に特徴量を変化させた際に、対応する出力画像がどのように変化するかを示した例です。この例では、「ネコ」と「ブタ」のデータで学習したモデルを使用しており、さまざまなネコとブタの画像が徐々に変化する様子が観察できます。

図3 特徴量の変化に対応した出力画像の変化(論文より抜粋)
今回は、論文「A Neural Representation of Sketch Drawings」を元に、スケッチデータを生成するSketch-RNNの機械学習モデルを解説しました。学習済みモデルを用いたサンプルアプリケーションも公開されているので、興味のある方は、実際にスケッチを生成して観察してみるとよいでしょう。
次回は、比較的最近のネットワーク技術の話題として、Googleの新しいSDN技術「Espresso」を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































